DEVELOPER’s BLOG
技術ブログ
Microsoft Azure Machine Learning でランダムフォレスト回帰を用いた人気ブログタイトル予測

様々な場面で使われるランダムフォレストですが、大きく分けると「ランダム」の部分と「フォレスト=森」の部分の2つに分けることができます。そこで今回は理論編でそれぞれの部分がどういう仕組みになっているのか、解説していきたいと思います。後半では、実践編と題して、実際のデータセットとMicrosoft Azureを用いてRandom Forest Regressionを一般的なLinear Regression (直線回帰) と比べてみたいと思います。
理論編
0.前提知識
ここではRandom Forest Regressionの中身を主に説明していくので、一部省略している部分があります。具体的には、
「回帰」って何?
「学習」って何?
のような問いには答えていないので、その場合は他の記事をご参考ください。ここでは、Random Forestの仕組みについて説明していきます。
1.「フォレスト=森」
フォレストモデルはその名の通りで、複数の「木」から成り立つ「森」のような学習モデルです。下の図のように、一つ一つの木は「decision tree(決定木)」のような条件分岐でデータを分類しています。それぞれの分岐において使われる変数を説明変数と言い、最適な説明変数を学習していくのが決定木における学習です。
例えば、下の図の場合、まずは「男性かどうか」、次に男性のうち、「10歳位以上かどうか」、最後に、10歳未満の男性のうち、「兄弟が3人以上いるか」、このような分岐条件でデータを4つに分類しています。
実際には、この3つの説明変数以外に、「身長が170cm以上か」「海外旅行に行ったことがあるか」など、様々な説明変数があり、どの変数を使うとデータを一番適切に分類できるか、決定木が学習していきます。
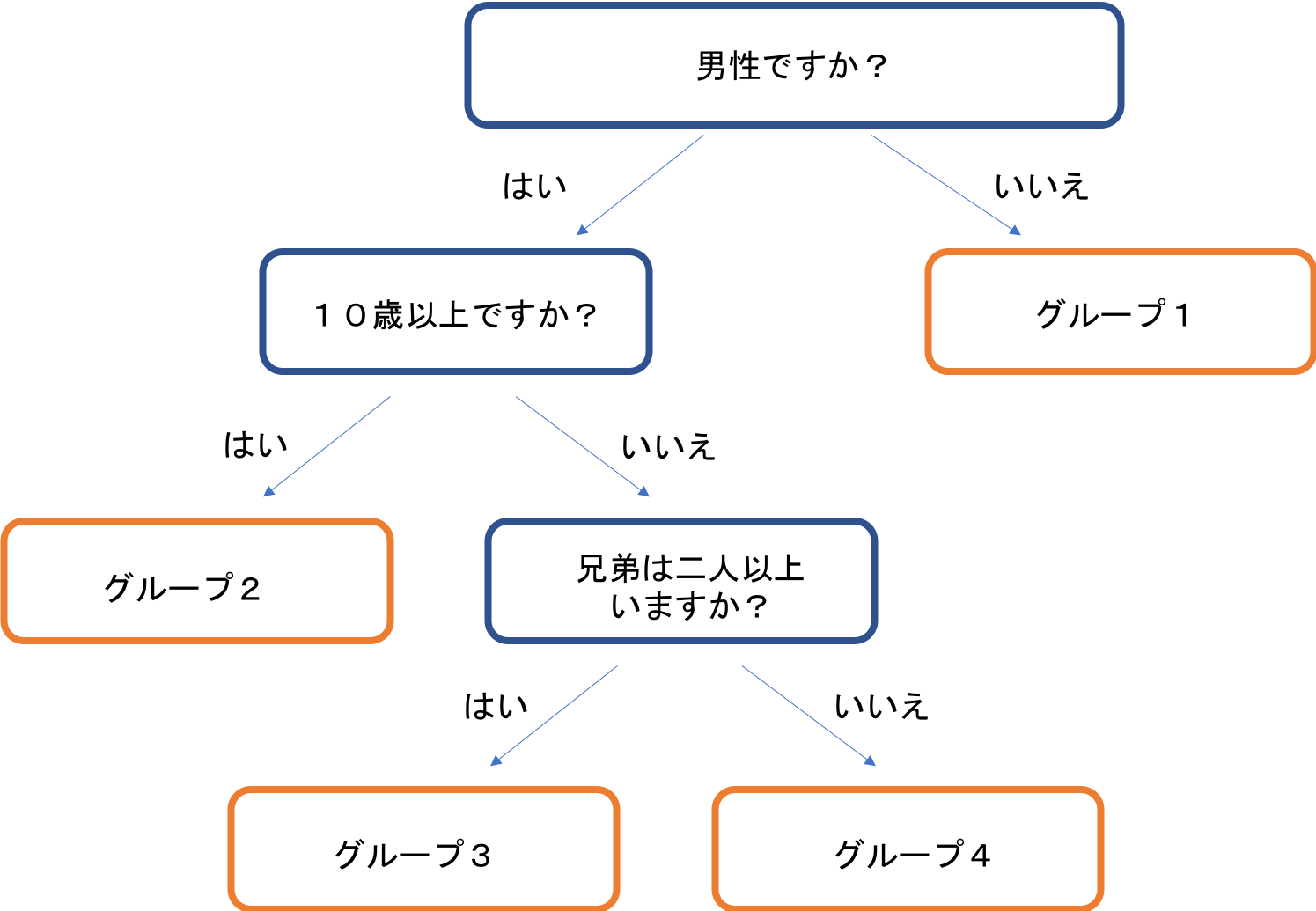
木が深いほど細かく分類ができますが、計算負荷が増えるので、回帰に使用する場合は深さをn=5にするのが良いとされています。
このような木を複数集めて、結果を平均したものを最終結果として決定するのが、フォレストモデルです。計算負荷の少ない小さな木を複数使って最終的な判断を総合的に行う、このような学習モデルをアンサンブル学習と言います。
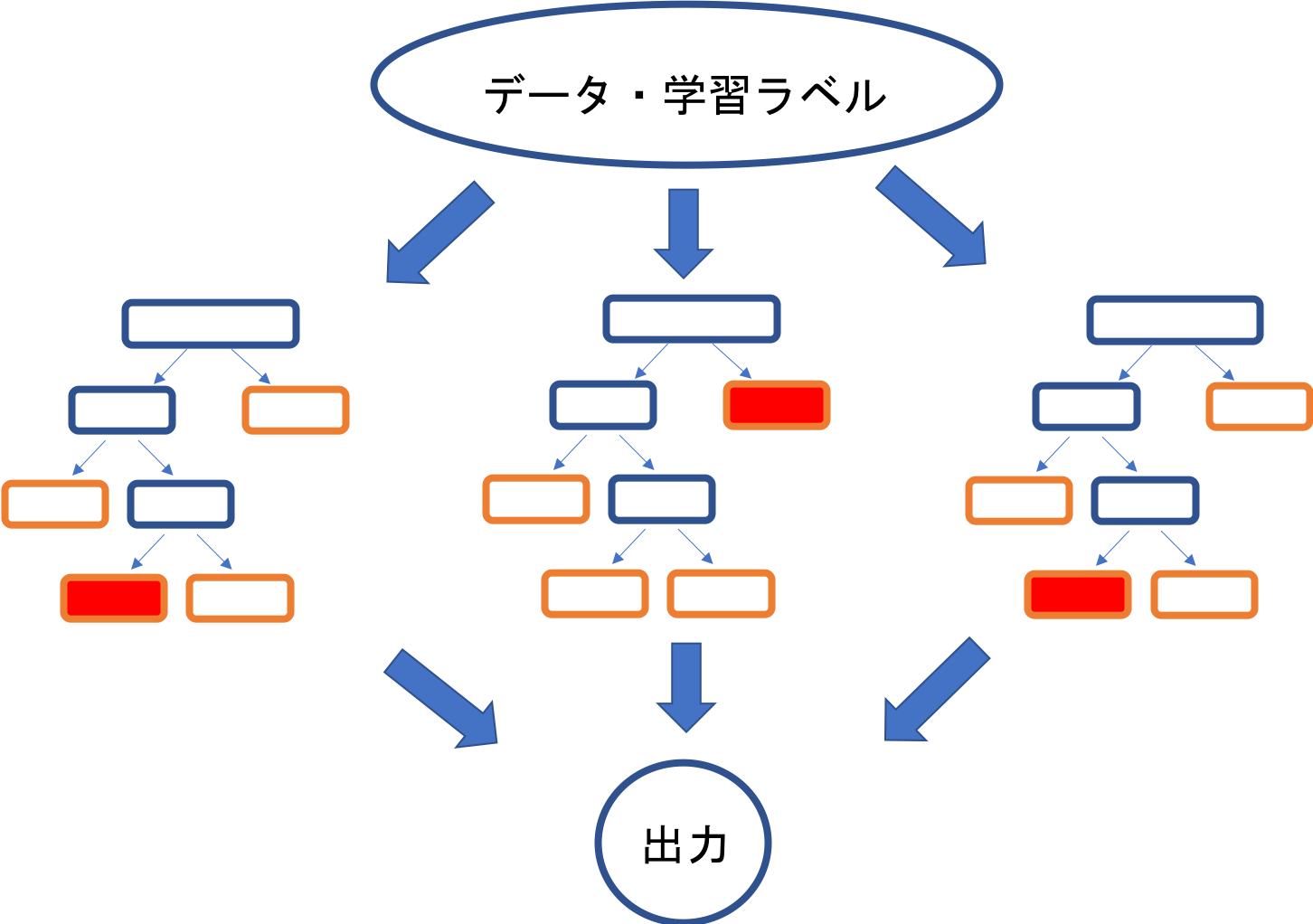
(もっと知りたい人向け)
各ツリーにおける分岐の分割条件の計算方法も様々あり、回帰モデルか分類モデルかによって変わります。
ここで扱う回帰モデルの場合、最小二乗法が使われますが、分類モデルの場合、
- エントロピー
- ジニ不純度
- 分類誤差
の3つがよく使用されます。詳しい内容は次の記事をご参照ください。
決定木の2つの種類とランダムフォレストによる機械学習アルゴリズム入門
2.二つのランダム
計算処理が早いツリーを組み合わせるフォレストモデルですが、一つ大きな問題があります。もし個々の木が全く同じようにデータを処理するのであれば、データ全体の特徴を反映することができません。一つの小さな木を使ってるのと同じになってしまいます。つまり、木によって分岐条件が違わなければ分類制度が低くなってしまいます。そこで、
- 学習データ
- 初期説明変数
をランダムで設定することで学習制度を向上させています。学習データの選定はブートストラップ法と呼ばれ、それぞれの決定木に関して毎回母体データからランダムに一部を選び取ります。初期説明変数も同様に、全体の説明変数から毎回ランダムにいくつか選び、決定木の説明変数として使用します。
3.長所と短所
最後に、ランダムフォレストはどのような利点・欠点があるのでしょうか。
長所としては、
- 説明変数が多数であってもうまく働く
- 学習・評価が高速
- 決定木の学習は完全に独立しており、並列に処理可能
- 説明変数の重要度(寄与度)を算出可能
などがあります。
短所は、
- 説明変数のうち意味のある変数がノイズ変数よりも極端に少ない場合にはうまく働かない
というものです。つまりデータの分類・予測に有用な変数が少なければ、学習がうまくいかないことになります。
実践編
では、実際Random Forest Regressionを使って学習をしていきましょう。今回はMicrosoft Azure MLを使って説明します。
今回使うデータセットはブログに関するデータで、タイトル、お気に入り登録者数などの情報が入っています。今回はこのデータセットから、
「どのような名前が人気のブログになりやすいのか」
を回帰してみたいと思います。
0.データ処理
まず初めに、使うデータを綺麗にします。通常、空白になっている部分があったりして、処理がすぐにはできないようになっています。
そこで、データを前処理する必要があります。今回は、
- 必要な列を選ぶ
- 空白の値があるデータを取り除く
の二つの処理を行いました。
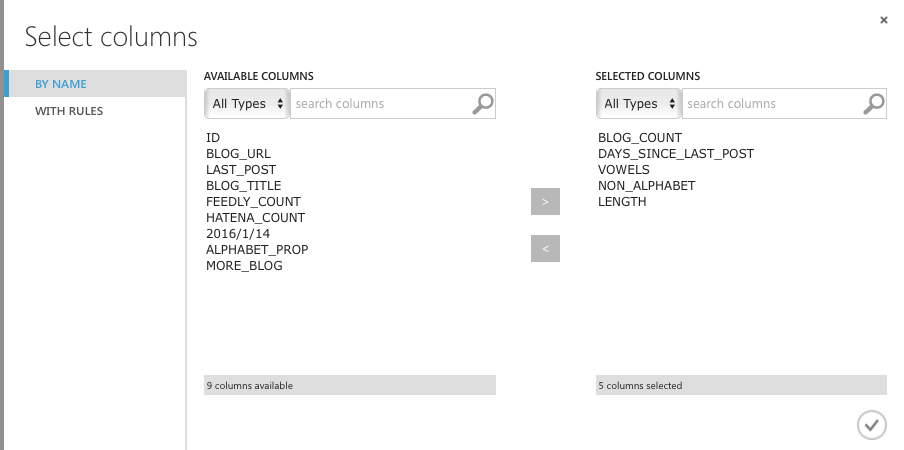
今回の目的はどういう名前が読者を集めやすいのか、というのを知りたいので、
メインの変数:BLOG_COUNT (読者数)
説明変数:
- DAYSSINCELAST_POST (最後に更新されてから何日経っているか)
- VOWELS (アルファベットの母音がいくつあるか)
- NON_ALPHABET (日本語の文字がいくつあるか)
- LENGTH (タイトルが何文字か)
を選びたいと思います。
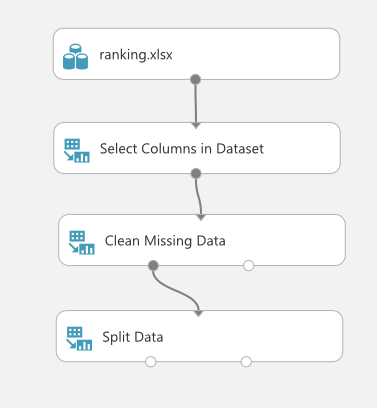
1.データの分割
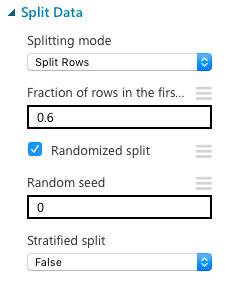
学習をするにあたって、機械を学習させるための学習データ(training data)と、その学習を評価するデータ(evaluation data)の2種類が必要になってきます。そこで、元のデータをランダムに分割する"Split Data"を使います。今回は元データの60%を学習データに使用することにしました。もちろん、この値は調節可能です。
2.モデルの選択
今回はRandom First Modelを使ってみたいので、標準的なLinear Regressionと比べてみることにします。
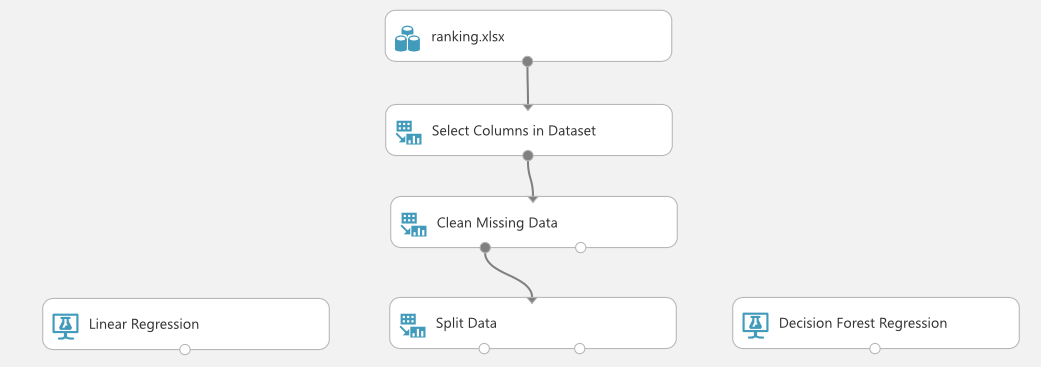
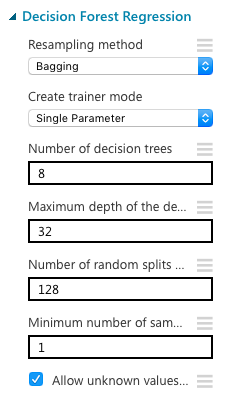
モデルのパラメーターは初期設定のままにしました。下の画像からもわかるように、決定木が8本あり、最高でn=32の深さまで木を作ることができます。
3.学習
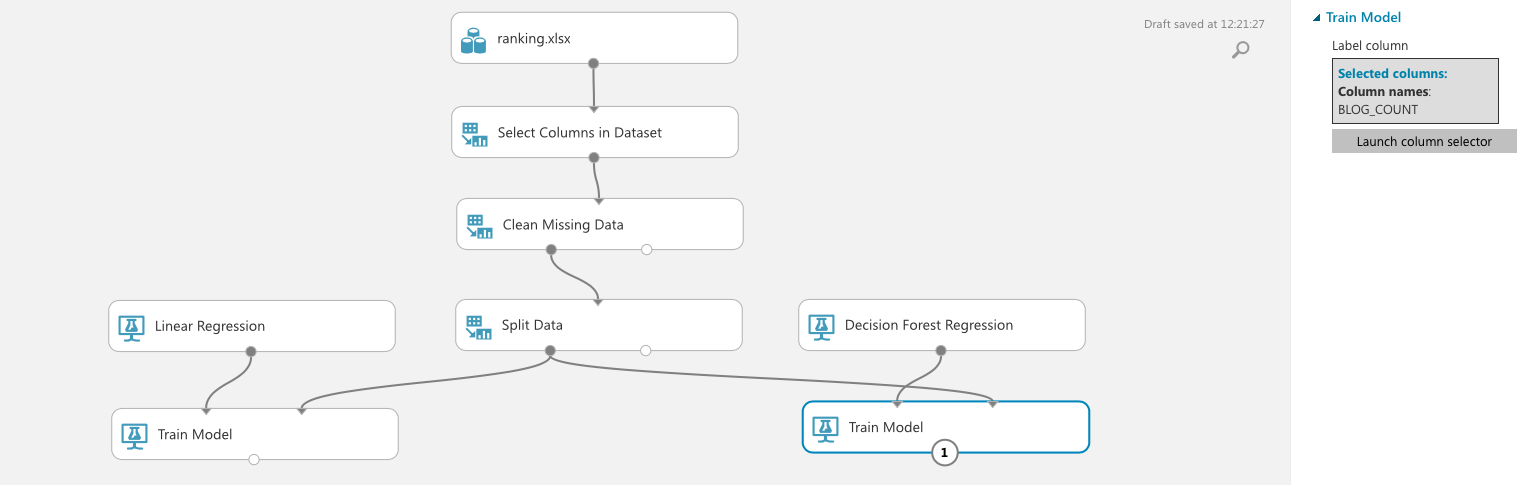
実際の学習モジュールを追加していきます。ここでは、それぞれの"Train Model"モジュールに対して、どの変数を予測したいか、を指定しなければなりません。人気のブログを予測したいので、BLOG_COUNTを選びます。
また、分割したデータのうち、学習用のデータ(左側)を入力として指定します。
4.評価と比較
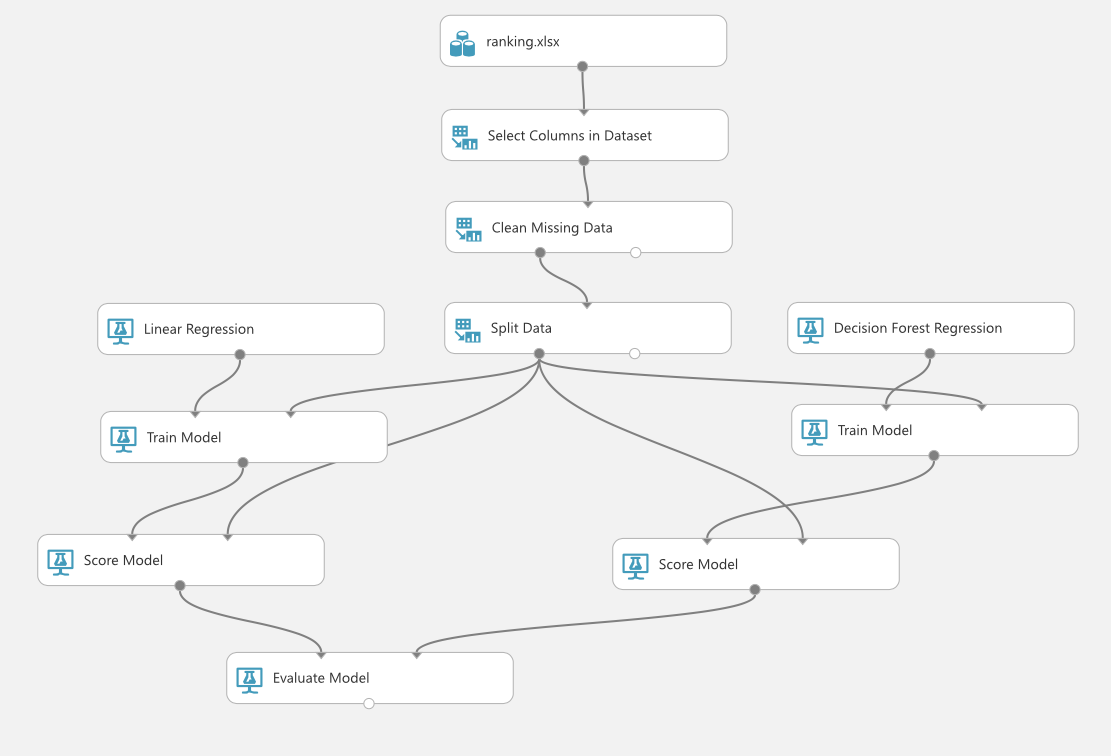
今回はRandom Forest ModelとLinear Regressionの精度を比べますが、2種類の比べ方をしたいと思います。
一つ目は、「与えられた学習データをどれだけ正確に学習できたか」という基準です。理想的には、入力に使ったデータなので100%予測してほしいものなのですが、現実的にはそうもいきません。そこで、2種類のモデルがどの程度精度をあげられたのかをまず比較します。
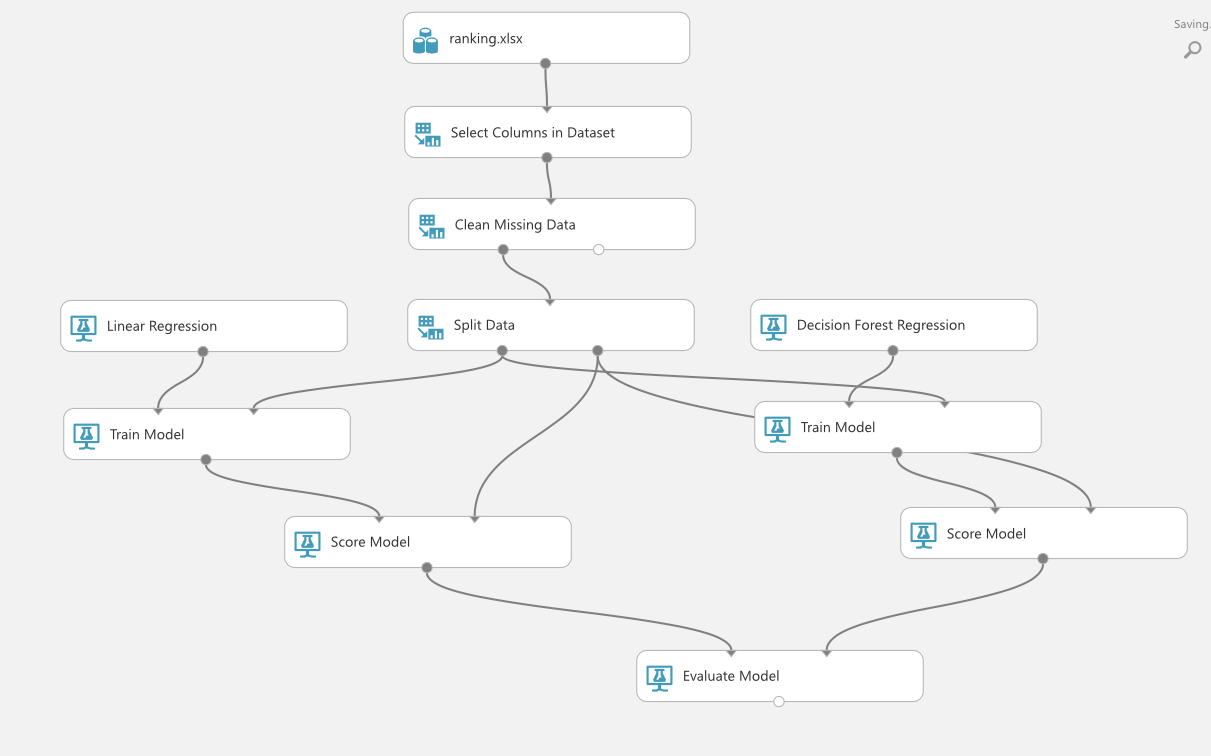
二つ目は、「見たこともないデータをどれだけ正確に予測できたか」という基準です。ここで最初に分割しておいた評価データを使うことになります。
5.結果
以上を全て組み合わせると、以下のような図になります。
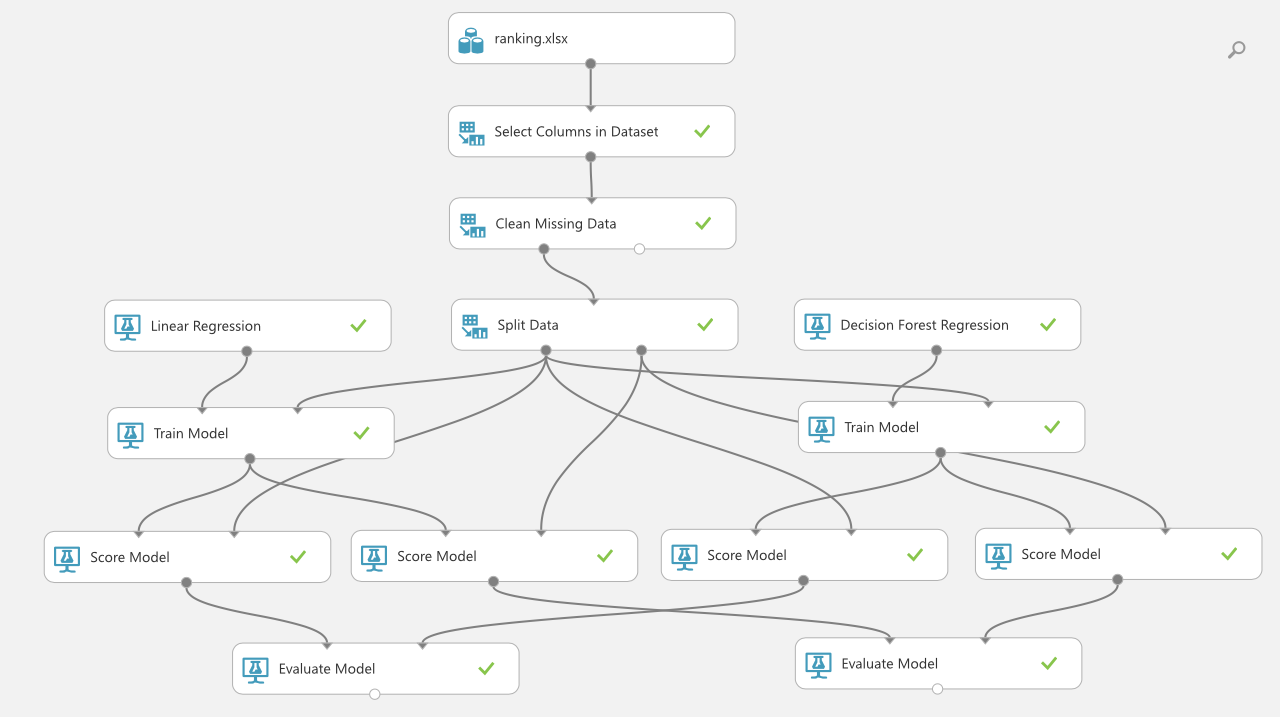
そして学習データの結果を比べると、下の図のように、

誤差がRandom Forest Regression (2列目)の方が小さいことがわかります。 同様に評価データについても、Random Forest Regressionの方が精度が良いことがわかります。

今回は説明変数も少なかったのですが、説明変数が非常に多い場合、比較的速く学習できるモデルとしてRandom Forest Regressionは有用です。
以上、Random First Regressionの理論と実践でした。
その他のMicrosoft Azure Machine Learning Studioでやってみた記事も参考にしてください!
決定木アルゴリズムCARTを用いた性能評価
ロジスティクス回帰を用いた Iris Two Class Dataの分類
分位点回帰を用いた飛行機遅延予測
パラメーターチューニングを行う
参考文献:
決定木の2つの種類とランダムフォレストによる機械学習アルゴリズム入門
関連記事

ここでは今は去りしデータマイニングブームで頻繁に活用されていた決定木について説明する。理論的な側面もするが、概念は理解しやすい部類であるので参考にしていただければと思う。 1 決定木(Decision Tree) 決定木とは木構造を用いて分類や回帰を行う機械学習の手法の一つで段階的にある事項のデータを分析、分離することで、目標値に関する推定結果を返すという方式である。データが木構造のように分岐している出力結果の様子から「決定木」との由来である。用途としては

はじめに 今回はロジスティック回帰についてやっていこうと思います。まずはロジスティック回帰の概要を説明して、最後には実際にAzureでiris(アヤメ)のデータでロジスティック回帰を使っていこうと思います。 勾配降下法 ロジスティック回帰でパラメータの値を決めるときに勾配降下法を用いるので、簡単に説明をしておきます。 勾配降下法は、ある関数J(w)が最小となるwを求める際に、あるwでの傾き(勾配)を求めて、降下の方向(傾きが小さくなる方)にwを更新し

分位点回帰は、普通の直線回帰とは少し変わった、特殊な回帰ですが、正規分布に従わないデータを処理する際、柔軟な予測をすることができる便利なモデルです。今回は、理論編・実践編に分けて、分位点回帰を解説していきたいと思います。 理論編 1.回帰 回帰とはデータ処理の方法の一つで、簡単に言うとデータを予測するモデルを作る際に、「モデル化=簡略化」に伴う損失を最小限にすることです。そしてこの「損失」を定量化するためにモデルごとに様々な「損失関数」を定義します。「損失

今回は特定のモデルではなく、パラメーターチューニングというテクニックについて解説したいと思います。 パラメーターチューニングとは、特定のモデルにおけるパラメーター(例:Decision Forest Model における決定木の数)を調節することで、モデルの精度を上げていく作業です。実際にモデルを実装する際は、与えたれたデフォルト値ではなく、そのデータで一番精度が出るようなパラメーターを設定していくことが重要になります。その際、一回づつ手動で調節するのでは