DEVELOPER’s BLOG
技術ブログ
AWS責任共有モデルの誤解によるリスク─セキュリティ事故から見えた教訓

- はじめに
- 責任共有モデルにおける責任範囲
- EC2・S3・IAMにおける共通の設定ミスとリスク
- IAM権限エスカレーション攻撃の典型的な流れ
- 複合的なクラウド侵害シナリオ事例
- SREによる包括的なクラウドセキュリティ改善
1. はじめに
AWSなどクラウドは、提供事業者と構築ベンダーや利用者による責任共有モデルに基づいています。責任共有モデルがセキュリティなど、双方の守るべき範囲を示してくれています。しかし、このモデルを正しく理解していないと、「クラウドだから安全」という誤解が設定ミスを招きます。クラウド環境は一見デフォルトで安全に思えるかもしれませんが、セキュリティ責任は明確に分担されています。
もし利用者側の設定ミスがあれば、攻撃者はそれを利用してクラウド環境に不正アクセスをし、深刻な被害を及ぼす可能性があります。例えば、侵入を許してしまった環境では、設定ミスを足がかりにクラウド内で機密データの漏洩などを引き起こすおそれがあります。
本記事では、具体的な設定ミスと改善策を紹介します
2. 責任共有モデルにおける責任範囲
AWSの責任共有モデル(Shared Responsibility Model)では、クラウドのセキュリティ責任が「クラウドのセキュリティ(AWS)」と「クラウド内のセキュリティ(お客様)」に分かれます。
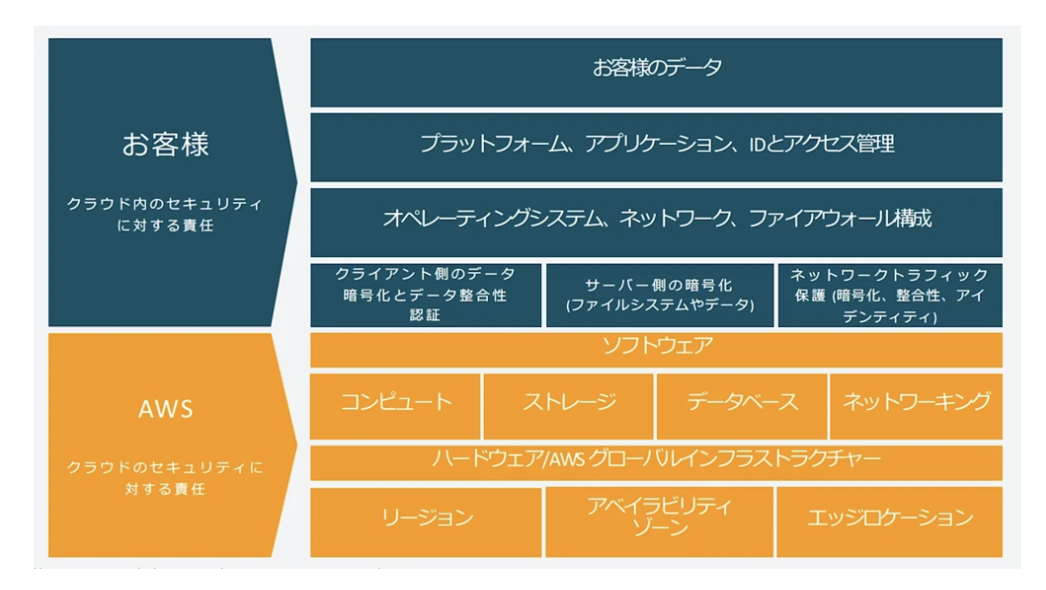 図1:AWSにおける責任共有モデル (引用:責任共有モデル)
図1:AWSにおける責任共有モデル (引用:責任共有モデル)
以降は、AWSの図にならい、利用者をお客様と表現します。
AWSはデータセンター施設やハードウェア、基盤インフラなどクラウド自体の防御を担う一方で、お客様はOSやアプリケーションの設定、データの保護などクラウド上で稼働させるものの防御を担います。
言い換えれば、たとえAWSがインフラを高度に保護していても、お客様が自分の責任範囲の対策を怠った場合、データ漏洩などのセキュリティインシデントが起きてもお客様側の責任となります。
例えばAmazon EC2等(IaaS)ではAWSはハードや仮想化基盤までを守りますが、その上で動くOSやミドルウェアの更新・パッチ適用、ファイアウォール設定、データ暗号化やアクセス制御(IAMポリシー設定)などはお客様の責任です。一方、Amazon S3のようなマネージドサービスではインフラやOSはAWSが管理しますが、格納するデータの分類・暗号化やIAMによる適切なアクセス権設定はお客様側の責務です。
この境界を誤解すると「AWSが全部守ってくれる」と思い込んで自分の役割を怠り、結果として脆弱性を生むことになります。サービスごとに境界が異なるため、本記事の3章以降では、利用頻度が高いサービスを取り上げて「やってしまいがちな誤解や設定ミス」を紹介します。
3. EC2・S3・IAMにおける共通の設定ミスとリスク
責任共有モデルのお客様責任において、特に人為的ミスによる設定不備がクラウドリスクを高める典型例です。以下にAWS環境で頻発する設定ミスの例と、それによるリスクを紹介します。
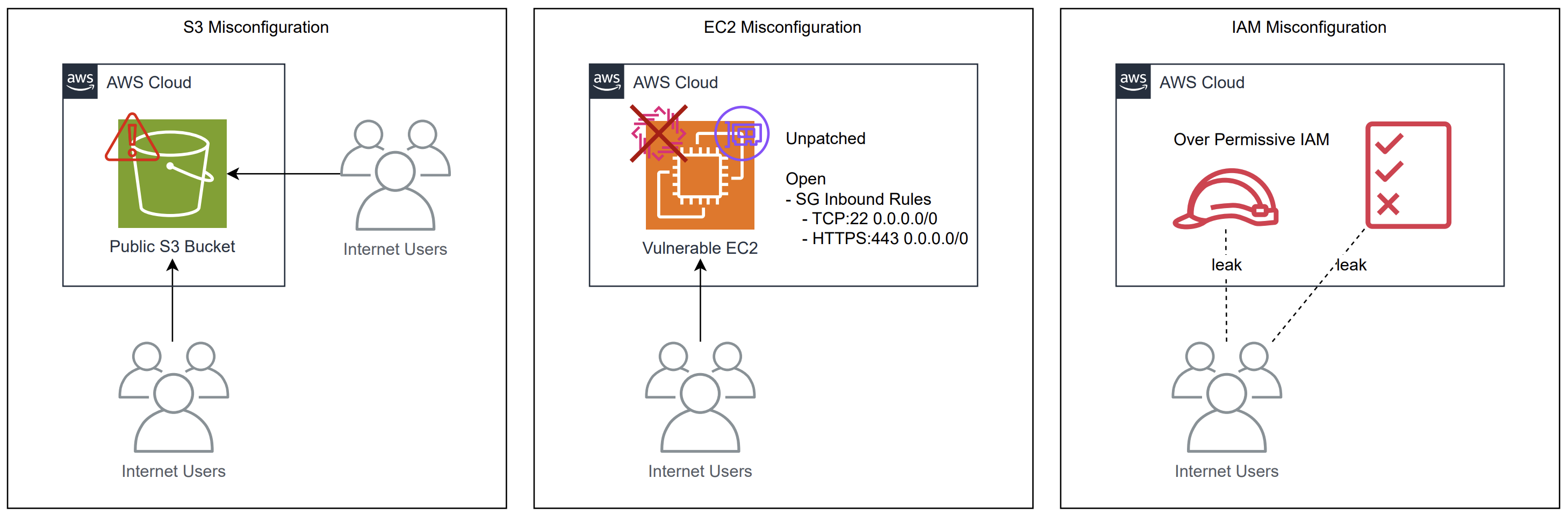 図2: AWSにおける一般的な設定ミスとそれによるリスク
図2: AWSにおける一般的な設定ミスとそれによるリスク
クラウド利用者に多いミスの代表例とその影響を模式的に示した図です。
Amazon S3の公開設定ミス
誤ってS3バケットやオブジェクトをインターネットから誰でも読める状態にしてしまうミスです。その結果、機密データが第三者に漏洩するリスクがあります。実際、世界中でこの種の設定ミスによるデータ漏洩事故が相次いでおり、過去数年でも広範な被害が報告されています。
EC2インスタンスの脆弱性放置や公開範囲のミス
仮想サーバであるEC2のOSやミドルウェアにセキュリティパッチを適用しなかったり、ファイアウォールであるセキュリティグループの許可範囲を過度に開放したりするミスです。結果としてインターネットからそのインスタンスに攻撃が届き、侵入・乗っ取りを許す可能性があります。一度EC2が攻撃者に侵害されると、そのインスタンスから横展開され、最悪の場合クラウド環境全体が踏み台にされかねません。
IAM(Identity and Access Management)の権限設定ミス
ユーザーやロールに不必要に広い権限を与えてしまうミスです。本来は最小権限の原則に従うべきところを誤って管理者同等のポリシーを付与してしまうと、万一そのクレデンシャルが漏洩・悪用された際に一挙に環境全体が危険に晒されます。IAM権限は非常に細かな粒度で制御できる反面、わずかな設定ミスがアカウント全体の権限エスカレーション(不正な権限昇格)に直結するため注意が必要です。
上記のように、設定ミスによる脅威パターンはいくつか類型化できます。次章では特にIAM権限の誤設定から生じる権限エスカレーション(Privilege Escalation)攻撃の流れに注目します。
4. IAM権限エスカレーション攻撃の典型的な流れ
IAMの設定ミスは権限エスカレーション(本来持つべきでない高権限を不正に得ること)に直結します。権限の誤設定によっては、攻撃者が一般ユーザー権限を起点にクラウド管理者権限まで上り詰めることさえ可能です。その典型的なシナリオの一つが、IAMポリシーの誤設定を悪用して自身に管理者ポリシーを付与する方法です。
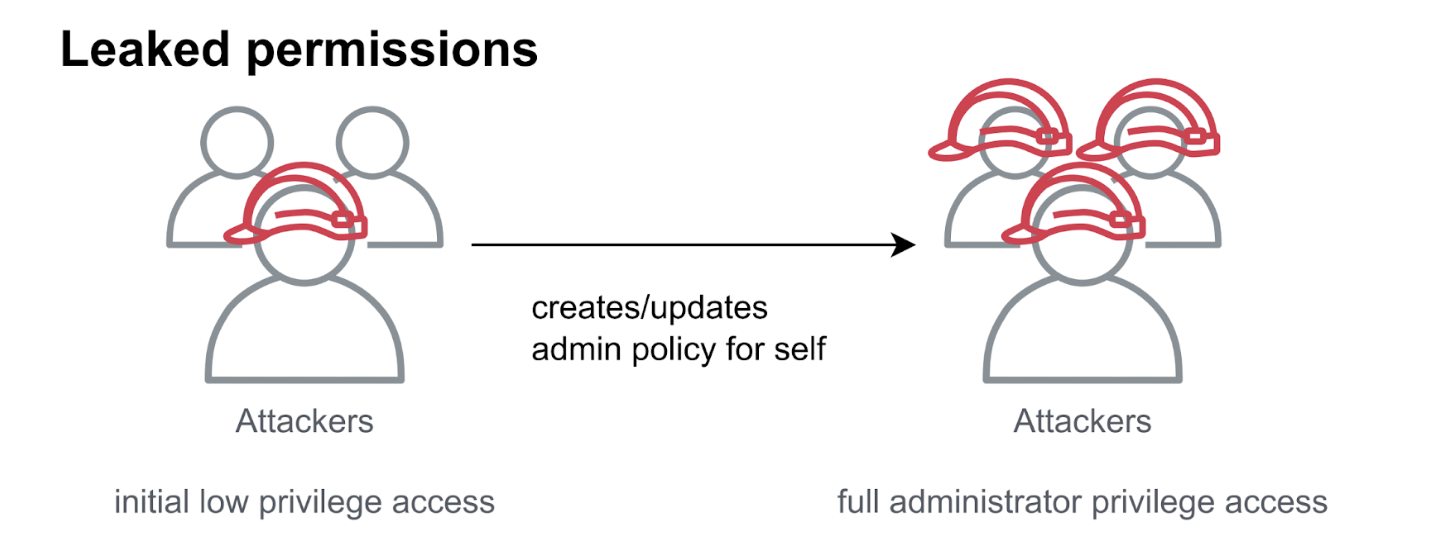 図3:IAMの設定ミスによる権限エスカレーションの一例
図3:IAMの設定ミスによる権限エスカレーションの一例
(低権限の攻撃者が誤設定されたIAM権限を利用して管理者権限を取得する流れ)
まず攻撃者は何らかの方法で侵害した低権限ユーザー(例:mallory)のAWSアクセス権を入手します。
次にそのユーザーに付与されたIAMポリシーを調べ、例えばiam:CreatePolicyVersionといったポリシー更新権限が含まれていれば、それを悪用します。攻撃者は管理者権限を与える内容のポリシードキュメントを用意し、自分に紐づく既存ポリシーの新バージョンとして作成・適用します(--set-as-defaultフラグを使用してデフォルトバージョンを更新)。本来この操作にはiam:SetDefaultPolicyVersion権限も必要ですが、CreatePolicyVersionでフラグを指定すれば自動的に新バージョンをデフォルトにできる抜け穴を突いた攻撃です。
こうして攻撃者は自身のユーザーに管理者相当のポリシーを上書きしてしまい、AWSアカウント内のフルアクセス権限を手に入れます。
このような手口以外にも、IAMに関するエスカレーション手法は多数報告されていますが、いずれも「本来与えるべきでない強力な権限をうっかり与えてしまう」ことが根本原因です。
5. 複合的なクラウド侵害シナリオ事例
ここまで見てきた各種設定ミスと攻撃手法は、単独に留まらず組み合わさって発生することも多くあります。 その典型例が2019年のCapital Oneの大規模情報漏洩事件で、この攻撃ではネットワーク、EC2、IAM、S3にまたがる複合的なミスの連鎖が悪用されました。
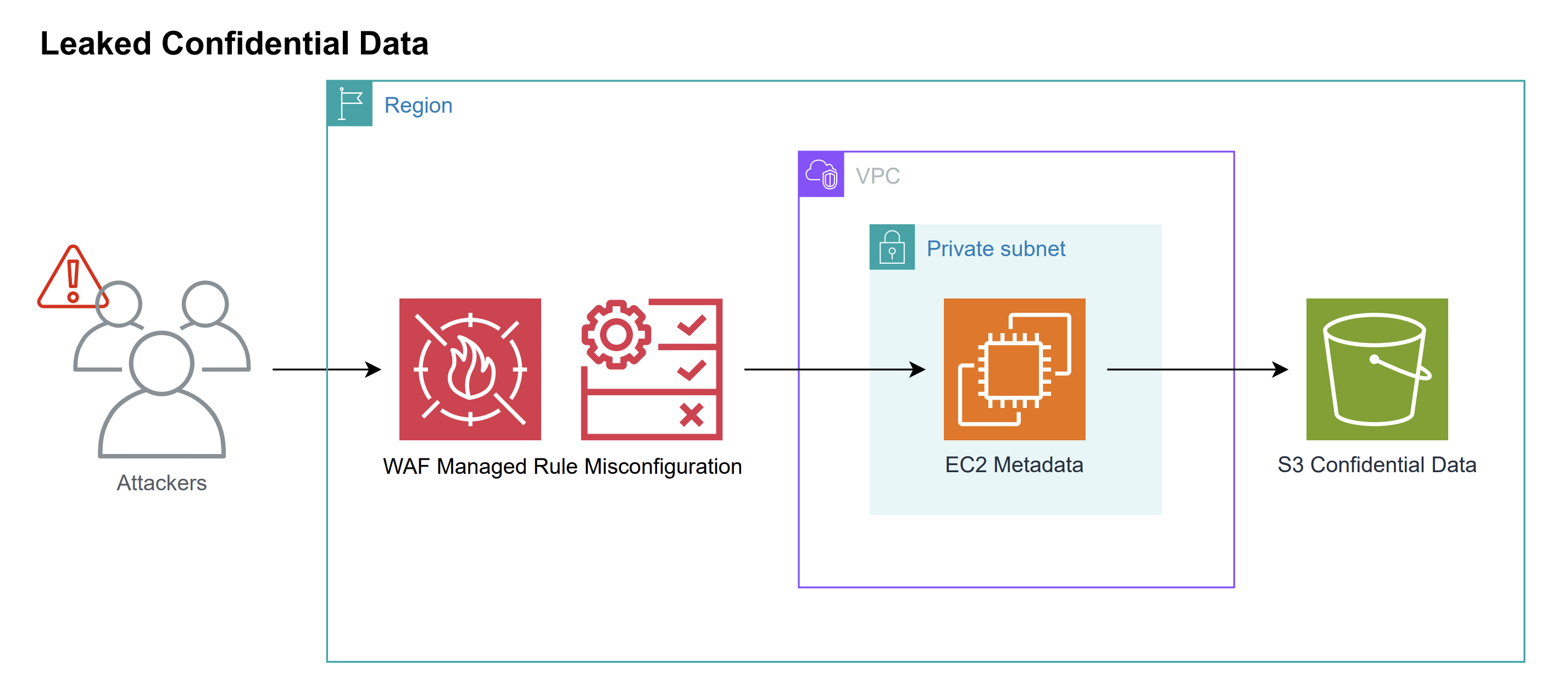 図4:複数の設定ミスが連鎖したクラウド侵害シナリオの一例(引用:Capital One事例)
図4:複数の設定ミスが連鎖したクラウド侵害シナリオの一例(引用:Capital One事例)
この攻撃ではまずWebアプリのWAF設定ミスが発端でした。攻撃者はその誤設定を突いて当該EC2インスタンスのメタデータサービスにリクエストを送り込み、IAMロールの一時認証情報を取得しました。
次にその資格情報を用いて当該ロールでアクセス可能なS3バケットの一覧を取得し、機密データを含むバケットを発見しました。
最後にAWS CLIのsyncコマンドを使って、そのバケット内のデータを丸ごとダウンロード(大量漏洩)しています。
このように、一つ一つの設定ミスが組み合わさることで被害が拡大することに注意が必要です。実際Capital Oneの事例では1億件以上の顧客情報が流出し、クラウドの誤設定リスクが社会的にも大きく報じられることとなりました。クラウドの設定ミスは重大なインシデントに直結します。
このような人為的ミスや運用上の穴を低減するためにSite Reliability Engineering (SRE)のアプローチを導入・徹底しています。
6. SREによる包括的なクラウドセキュリティ改善
SREは本来、サービスの信頼性(Reliability)を高めるためのエンジニアリング手法ですが、その原則や文化をセキュリティ運用に適用することで設定ミスの予防・検知からインシデント対応まで包括的な改善が期待できます。以降では、SREのアプローチを中心にクラウドセキュリティ向上のための対応を紹介します。
アラートと監視:
SREの基本であるシステム監視は、セキュリティ面でも重要です。クラウドの各種ログ(CloudTrailやVPC Flow Logs等)や設定状況を常時モニタリングし、異常を検知したらアラートを上げる仕組みを整備します。例えば「公開状態のS3バケットが作成・変更された」「IAMポリシーにワイルドカード(*)が含まれた」等を自動検出して通知することで、設定ミスの放置を防ぎます。人手に頼らずソフトウェアツールによる自動監視を重視しており、大規模システムでも持続可能な運用が可能です。こうした自動監視により、人的ミスの早期発見と是正が促進されます。
監視体制を統合することで、単なる監視精度の向上にとどまらず、以下のような将来的な全社IT戦略への展開も視野に入れることができます。
構成管理と自動化:
人為的ミスの多くは手作業の構成変更から生じます。SREでは、IaC(Infrastructure as Code)やCI/CDパイプラインを通じた構成のコード管理と自動デプロイを推進します。例えばAWS環境の設定をTerraformやAWS CloudFormationでコード化し、変更はコードレビュー&自動テストを経て適用するようにすれば、不注意によるミスを減らせます。またOSパッチ適用やIAMポリシーのポリシーリンター(lint)によるチェックなども自動化し、セキュリティホールを継続的に潰します。ソフトウェアによる自動化こそSREの中核であり、手作業より信頼性・再現性の高い運用を実現します。結果として、設定不備の予防につながるのです。
ポストモーテム(事後検証)と継続的な改善:
SRE文化の重要な要素にポストモーテム(事後検証)があります。インシデントや障害が発生した際、ミスを責めるのではなく、再発防止のための教訓を最大化することにフォーカスします。セキュリティインシデントについても同様で、発生した原因と経緯をチームで振り返り、改善策をドキュメント化して共有知見とします。例えば「なぜ特定のS3バケットが誤って公開されていたのか」「検知を逃した要因は何か」といった根本原因を洗い出し、必要なプロセス改善(レビューの強化や自動チェック追加など)を実施します。ポストモーテム資料をナレッジ化し、将来似た問題が生じた際に迅速に対処できるようにしています。この継続学習の文化が、組織全体のセキュリティ耐性を高めていきます。
セキュリティ文化の醸成:
最後に、技術面の対策以上に組織としての意識・文化が重要です。SREは開発と運用の橋渡し役として協調的でオープンな文化を育むことを重視しますが、これをセキュリティにも拡張し、「セキュリティは全員の責任」というマインドセットをチームに根付かせます。具体的には、開発者がセキュリティを他人事にせず自ら考慮する仕組み(Security Champion制度の導入など)や、失敗に対して懲罰ではなく改善の機会と捉える姿勢の徹底です。SREの文化の下では、インシデント情報や脆弱性情報をチーム内で積極的に共有し、異常を見つけたら速やかに議論・対策する雰囲気が醸成されます。その結果、「設定ミスを報告しづらい」「属人的な運用で知見が共有されない」といった状況を防ぎ、組織全体でセキュリティ品質を継続的に向上させていくことが可能になります。
以上のように、SREの考え方はクラウドセキュリティの強化に寄与します。クラウドの利点を享受するためには責任共有モデルを正しく理解し、自社の責任部分を疎かにしないことが大前提です。
その上で、SREの導入によって人間のミスを最小化しつつ迅速な検知・対応体制を築くことで、安全かつ信頼性の高いクラウド運用を実現できます。
関連記事

目次 はじめに 進め方概要 ステップ① コスト削減 コスト最適化支援 施策実施 ステップ② 継続運用の体制を構築 運用設計支援 監視基盤構築 AWS Cost Anomaly Detection とは ステップ③ 予防処置の体制を構築 運用設計支援 AWS Budgets とは AIを活用した予兆検知基盤構築 おわりに はじめに みなさんこんにちは。インフラエンジニアの伊達です。 やはり何事もコストは最小限で済ませたいものですよね。 システムは大きな問題も

はじめに シナリオ:ネットワーク制御要件を満たすための設計 適材適所の判断をする コスト最適化の視点 まとめ はじめに AWSでは、あらゆるユースケースを支える豊富なサービス群が提供されています。 しかし、その選択肢の多さゆえに「本当に必要な要件以上のサービスを導入してしまう」ケースも少なくありません。 特に、非機能要件に対して、必要以上に複雑な構成を採用してしまうと、以下のようなデメリットにつながることがあります。 AWSコ

はじめに 1. EC2 × ALB × CloudFront でインフラコストを削減 2. API Gateway × Lambda × CloudFront で動的コンテンツでもコスト最適化 3. 単一リージョン × CloudFront でグローバル配信をシンプルに まとめ:CloudFrontは単なる「CDN」ではない! はじめに AWSでシステムを構築する時、「とりあえずEC2インスタンスを建てて終わり」としていませんか?もし

はじめに SSM統合コンソールによる一元管理 OSなど構成情報の可視化 Patch Managerによるパッチ運用の標準化 証明書有効期限の集中監視と自動通知 導入効果と業務改善イメージ 導入時の設計上の留意点 継続的改善を支える「運用の仕組み化」 1.はじめに クラウド活用が拡大し、AWS環境が複数アカウントで利用されたり、複数システムにまたがって利用されることは、システム運用における構成の一貫性を維持することの難易度を