DEVELOPER’s BLOG
技術ブログ
SRE実践の盲点: 多くのチームが見落とす5つのポイント

- SRE導入後のよくある課題と本記事の目的
- 盲点①:ポストモーテムの形骸化
- 盲点②:モニタリングのカバレッジ不足
- 盲点③:自動復旧の未整備
- 盲点④:改善サイクルの不在
- 盲点⑤:カオスエンジニアリングの未導入
- まとめ
1.SRE導入後のよくある課題と本記事の目的
Site Reliability Engineering(SRE)の導入は、サービスの可用性や信頼性を高めるための有効な手段として多くの企業に取り入れられています。しかし、導入後しばらくして「思ったより効果が出ない」「障害が減らない」「チームが疲弊している」といった課題を感じ始めるケースも少なくありません。多くの場合、その原因はSREの原則やツールセットそのものではなく、実践の中で見落とされがちな"運用上の盲点"にあります。特に、形式化したポストモーテムや適切でないモニタリング設計、自動復旧の不備などは、信頼性向上を妨げる大きな要因になり得ます。
本記事では、SREを導入しているにもかかわらず期待する効果を得られていないチーム向けに、見落とされやすい5つの実践上のポイントを取り上げ、それぞれの問題と対策を具体的に解説していきます。この記事を通じて、SREの真の価値を再発見し、継続的な信頼性向上へとつなげるヒントを得ていただければ幸いです。
2.盲点①:ポストモーテムの形骸化
SREの重要な実践の一つであるポストモーテム(障害の事後分析)は、学習文化の促進と信頼性向上のための鍵となるプロセスです。しかし、多くのチームではこのポストモーテムが単なる形式的な作業となってしまい、本来の目的である「根本原因の特定と共有」「継続的な改善」につながっていないケースが目立ちます。 たとえば、「誰が悪かったか」に焦点が当たってしまったり、テンプレートだけを埋めて終わるような対応では、同様の障害が再発し続ける危険性があります。さらに、学習した内容がナレッジとして蓄積・共有されなければ、組織全体での運用知識の向上も期待できません。
解決策:文化としてのポストモーテムを根付かせる
-
責任追及ではなく学習重視の文化醸成
ブレームレス(責任追及をしない)ポストモーテムを明示的に導入することで、誰もが安心して障害の経緯や判断ミスを共有できるようになります。 -
ナレッジ共有と振り返りの場を制度化
障害報告書は社内Wikiなどにアーカイブし、定期的なレビューや振り返り会議を開催することで、学びの再利用が促進されます。 -
再発防止タスクの可視化とフォローアップ
改善アクションはJIRAやNotionなどのツールにタスクとして登録し、追跡可能な状態に保つことが再発防止の鍵です。
3.盲点②:モニタリングのカバレッジ不足
SREにおけるモニタリングは、システムの状態を定量的に把握し、インシデントの早期検知や原因特定を可能にする基盤です。しかし現場では、「とりあえず監視ツールを導入したが、アラートが出ない」「通知は来るが何を意味しているのかわからない」など、モニタリング設計そのものに抜けや偏りがあるケースが多く見受けられます。
典型的な問題としては以下のようなものがあります。
重要なサービスレベル指標(SLI)が定義されていない
アプリケーションやエンドユーザーの体験に関するメトリクスが監視対象外
ノイズの多いアラートにより本当に重要なアラートが埋もれている
これでは、障害の兆候を事前に捉えたり、根本原因を迅速に特定することが難しくなります。
解決策:SLO設計とアラート最適化の再構築
-
SLI/SLOベースのモニタリング設計
システムの信頼性を定義するSLI(例:成功率、レイテンシ)と、ユーザーに約束するSLO(目標値)を明確にすることで、「何を監視すべきか」が見えてきます。 -
ブラックボックス・ホワイトボックス両面の指標を整備
外部から見た応答性(ブラックボックス)と、内部状態(CPU使用率やキュー長など)をバランスよくカバーする必要があります。 -
アラートの重要度整理とルール見直し
アラートは「すぐに対応が必要なもの」と「後で確認すればよいもの」に分類し、優先順位を明確に。誤検知の多いアラートはしきい値や条件を再検討します。
4.盲点③:自動復旧の未整備
多くのSREチームでは障害対応の効率化を目指していますが、実際のインシデント対応が依然として人手頼りであることが少なくありません。障害発生時にオペレーション担当者が手作業で再起動や設定変更を行い、その対応が属人化してしまっていると、復旧までの時間が延び、運用負荷も高止まりします。 このような状況では、夜間や休日のオンコール対応の負担も大きくなり、チームの疲弊につながりかねません。さらに、人による操作はミスのリスクも伴い、信頼性の面でも課題が残ります。
解決策:自動復旧(Self-Healing)の段階的導入
-
Runbookの整備と自動化候補の洗い出し
まずは、よくあるインシデントへの対応手順(Runbook)を明文化し、自動化が可能な部分をリストアップします。 -
スクリプトやオーケストレーションツールによる部分自動化
例えば、「特定ログが出たらプロセスを再起動する」「メモリ使用率が一定値を超えたらスケーリングを実行する」といった単純対応から自動化を始めます。 -
リスクを抑えた段階的な導入戦略
すべてを一気に自動化するのではなく、影響範囲の小さいサービスやテスト環境から導入し、安全性と効果を検証しながら本番へ適用していくことが重要です。
自動復旧は単なる効率化ではなく、SREが目指す信頼性の"自律化に向けた基盤でもあります。
5.盲点④:改善サイクルの不在
SRE導入初期は熱量を持って様々な施策に取り組んでいたものの、時間が経つにつれて活動が惰性になり、改善のサイクル(PDCA)が回らなくなるケースは多くの現場で見られます。 SLI/SLOの設定をしたまま見直されていなかったり、障害対応後の改善策が放置されたりと、継続的改善を阻む"惰性"が定着してしまうと、SREの本質的な価値が発揮されません。このような状態では、組織としての信頼性は徐々に低下し、「SREを導入した意味がない」と評価されてしまうリスクもあります。
解決策:信頼性向上のためのPDCAフローを制度化
-
定期的なSLOレビューと指標の見直し
サービスの成長や顧客要件の変化に応じて、SLOの内容や基準値を見直す体制を設けることが重要です。 -
改善アクションのトラッキングと可視化
ポストモーテムや定例会議で出た改善案をJIRAやBacklogなどでタスク化し、進捗管理の対象とします。経過が見えることで責任感と継続性が生まれます。 -
SREチームの成果をKPI化して経営と接続
改善活動の成果を「平均復旧時間(MTTR)の短縮」や「エラーバジェットの消化率」といった指標で定量化し、経営層と共有することで活動の正当性を担保できます。
改善サイクルは、SREが単なる運用改善活動で終わらず、組織全体の信頼性戦略へと発展させるための土台です。
6.盲点⑤:カオスエンジニアリングの未導入
多くのSREチームは障害対応に力を入れている一方で、「そもそもどのような障害が起こり得るか」を予測的に検証する仕組みが存在しないことがしばしばあります。特に本番環境では、実運用に近い形で障害シナリオを試す文化が根付いていないため、想定外の障害に対して脆弱なシステム構成のままになっていることが多いです。 こうした課題に対処するための有効なアプローチが「カオスエンジニアリング」です。Netflixなどの先進企業が実践しているこの手法は、意図的に障害を発生させることで、システムの耐障害性(レジリエンス)を高めることを目的としています。
解決策:スモールスタートでのカオス実験導入
-
低リスク環境での障害注入から開始
いきなり本番で実施するのではなく、まずはステージング環境などでネットワーク遅延やサービス停止といったシナリオを試します。 -
事前に回復戦略とモニタリング体制を整備
カオス実験は「壊すこと」が目的ではなく、期待通りに回復できるかを検証することが目的です。そのため、事前に復旧手順やアラート設計が整っていることが前提です。 -
結果をポストモーテム形式で記録・活用
実験の結果を分析し、復旧の遅れや設計ミスがあれば改善タスクとして明確化します。これにより「準備された障害」にも強くなります。
カオスエンジニアリングは導入のハードルが高く感じられるかもしれませんが、段階的な導入と振り返りの仕組みがあれば、日常的な信頼性強化の一部として定着させることが可能です。
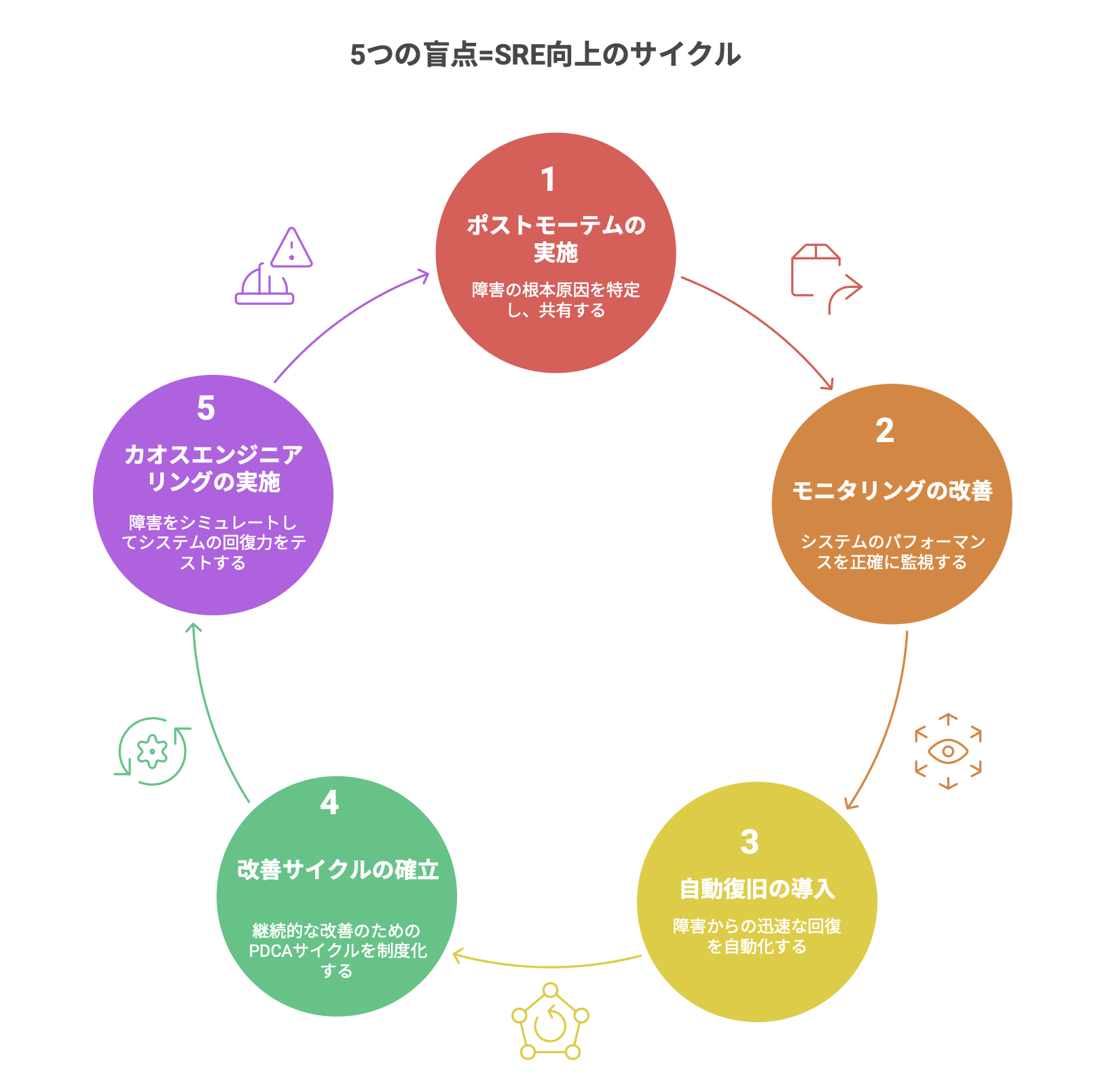
7.まとめ
SREの導入はスタートに過ぎず、真の効果を引き出すためには、日々の運用に潜む"盲点"を一つひとつ潰していくことが不可欠です。
<本記事で紹介した5つの盲点>
①ポストモーテムの形骸化
②モニタリングのカバレッジ不足
③自動復旧の未整備
④改善サイクルの不在
⑤カオスエンジニアリングの未導入
これらは、多くのチームが直面しながらも見過ごしがちな落とし穴です。アクセルユニバースでは、これらの盲点を診断・整理し、継続的な改善を実現するためのSRE支援サービスを提供しています。自社の信頼性向上を次のレベルへ引き上げたいとお考えの方は、ぜひお気軽にお問い合わせください。
X(旧Twitter)・Facebookで定期的に情報発信しています!
Follow @acceluniverse