DEVELOPER’s BLOG
技術ブログ
機械学習で為替予測(FX)をしてみる

こんにちは。
皆さんはFXでお金を稼ぎたいと思ったことはあるでしょうか?もしFXでこれまでの生活を一変させるような額のお金を稼ぐことができたら夢のようですよね?
今回はそんな夢を目指して、為替の値動きを機械学習で予測してみたというお話をしたいと思います。
目次
- 概要
- 手順
- 結果
- 今後の課題
1 概要
使用したデータセット:OANDA APIを用いて取得
https://www.oanda.jp/fxproduct/api
(デモ口座を開設することにより、無料でAPIを利用することができます)使用したモデル:LSTM
データセット
米ドル円の2016年9月22日から2020年7月20日までの1000個の日足データを取得し利用します。
今回は、open(始値)、close(終値)、high(高値)、low(安値)、volume(取引量)という基本的な特徴量を用います。
LSTMとは?
LSTMは時系列予測をするためのライブラリです。
LSTM(Long short-term memory)は、RNN(Recurrent Neural Network)の拡張として1995年に登場した、時系列データに対するモデル、または構造の1種です。その名前は、Long term memory(長期記憶)とShort term memory(短期記憶)という神経科学における用語から取られています。
ニューラルネットワークは過去の出来事を考慮することができず、RNNは長い記憶に対応できないという欠点があります。そこで長い過去の記憶を考慮できるように、LSTMが開発されました。
今回は5日分のデータを1セットとしてLSTMで予測をしました。
つまり、5日間の為替レートのデータを1セットとして、それを何セットも学習することで、新しい5日間のデータからその次の為替レートを予測していきます。
2 手順
今回為替予測をするにあたって行った手順について簡単に説明します。
データセットの準備
OANDA APIを用いて取得するデータの加工
・データセットの「time」の部分が特殊な形(「ISO 8601」)を日本時間に直す
・データを学習データと訓練データに分割する
・LSTM用にデータを変換する
絶対的な為替価格ではなく、どのように為替価格が変化し、どの程度価格が変動するかを見る変化率に直す
・PandasのデータフレームからNumpy配列へ変換するLSTMのモデル構築と学習・予測
・機械学習ライブラリのKerasを利用してモデル構築を行う
(Kerasについてはこちらをご覧くださいhttps://keras.io/ja/)
・モデルの訓練を行う
・作成したモデルを用いて、予測をする
3 結果
2のところで紹介した手順で為替の予測を行ってみました。結果をチャートにしたものがこちらです。
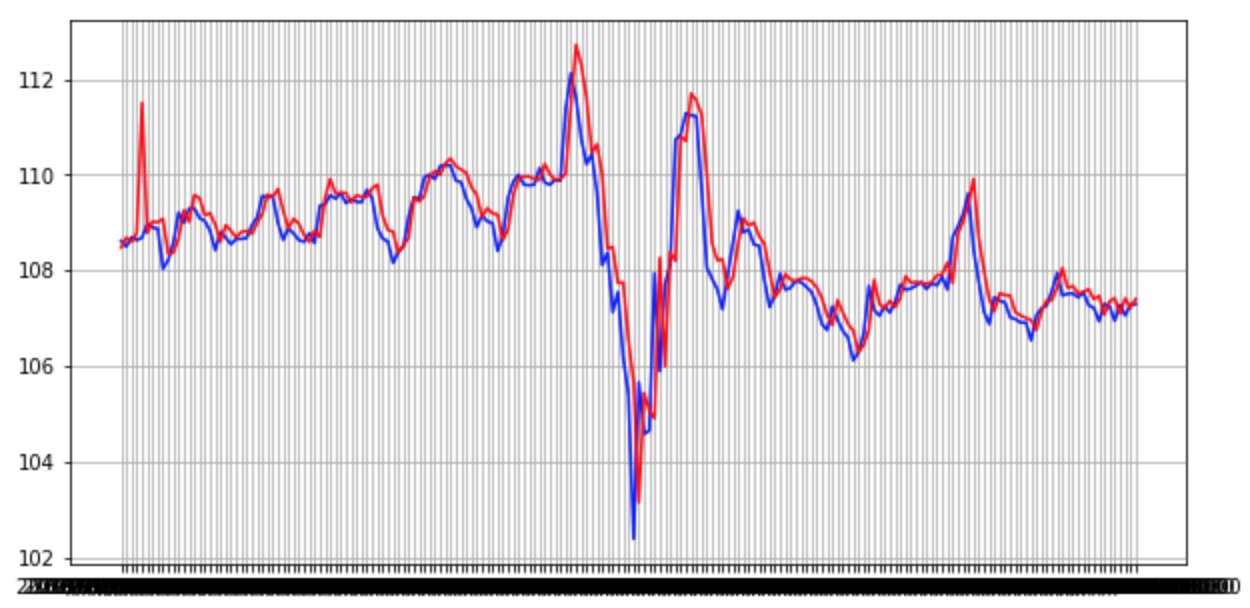
青のラインが実際の為替の値動き、赤が今回予測した為替の値動きです。
どうでしょうか。それっぽいものができていると思いますが、チャートをみてみると最初の方で大きく外しているほか、気になるのが、実際の値動きの後に遅れて予測したものが動いている点です。実際にレートが動いてから予測結果が出るため、エントリーのタイミングを逃してしまう可能性があり、各個人での判断が必要となってしまいます。
4 今後の課題
今回は一日の為替価格のみのデータで分析をしました。為替の値動きは、様々な経済指標やトランプ大統領の発言、1日の中の時間帯によっても変わっていくので、そのようなニュースの情報やTwitterなどの情報も取り入れたらさらに精度の高いものが出来上がるのではないかと思います。
FXトレーダーは、自分なりにチャートを分析し、何らかの基準を持ってトレードをしています。彼らのノウハウや経験をうまく機械学習に落とし込めれば、同等、またはそれ以上の精度で予測できるのではないかと個人的には思います。
引き続き機械学習を用いた為替予測を頑張っていきたいです!
関連記事

ご挨拶 AWS全冠エンジニアの小澤です。 今年の目標はテニスで初中級の草トーナメントに優勝することです。よろしくお願いいたします。 本記事の目的 本記事では、生成AIでVOC分析を行うことで得られた知見を共有したいと思います。 昨今、生成AIの登場など機械学習の進歩は目覚ましいものがあります。一方、足元では自社データの利活用が進まず、世の中のトレンドと乖離していくことに課題感を持たれている方も多いかと思います。また、ガートナーの調査(2024年1月)による

なぜ機械学習で双対問題を学ぶのか 結果から述べるのであれば、SVM(サポートベクトルマシーン)の原理で双対問題を使いたいからです。 これから実際どのように双対問題が使われているのか、また、双対問題の簡単な具体例を交えて説明していきたいと思います。 まずSVMについて簡単に説明したいと思います。 予測には過去のデータを使います。 しかし、外れ値のような余計なデータまで使ってしまうと、予測精度が下がるかもしれません。 そこで「本当に予測に必要となる一部のデータ

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数

目次 機械翻訳とは 機械翻訳の手法 現在の機械翻訳の欠点 欠点が改善されると 今後の展望 機械翻訳とは 機械翻訳という言葉を理解するために2つ言葉を定義する。 系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。 系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。 この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)