DEVELOPER’s BLOG
技術ブログ
機械学習におけるパラメータとその決定法

このブログはそもそもパラメータという言葉をよく耳にするが、どのように決定しているのか知りたい人(機械学習の初歩的な数学の理論を知りたい人)向けです。少し数学的な計算も入ってきます。
学習とは、仮定から導き出した誤差関数を最小に,あるいは尤度関数や事後分布を最大にするパラメータを求めることでした。そのうち今回は尤度関数と勾配法について説明していきたいと思います。
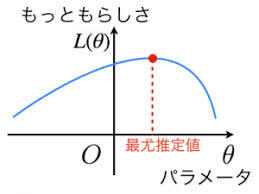
パラメータとはどういう設定値や制限値で機械学習の予測モデルを作るのかを示すものです。イメージとして、あとで定義する尤度関数が下のグラフのようになっている時、尤度関数の最大値を取るθを求めるという作業です。
目次
最尤推定法
勾配法
最尤推定法と勾配法の問題点
1.最尤推定法
確率分布は既知ですが、ある母数(パラメータθ)が未知な母集団を考えます。
この場合、この確率分布が連続型であるならば、確率分布はθに依存する関数と考えられ、f(x,θ)と表します。
この母集団から独立にn個標本を抽出した時のデータがx1,x2,....,xnの値をとる確率は、L(θ)=f(x1,θ)f(x2,θ)....*f(xn,θ)と考えられ、L(θ)を尤度関数といいます。
まず具体例を見てみましょう。
正規分布の平均、分散の最尤推定
X~N(μ,σ^2)とします。(N(μ,σ^2)は平均μ、分散σ^2の正規分布)
すると以下のように平均と分散の最尤推定値が求められます。
正規分布の確率密度関数を以下のように与えられます。
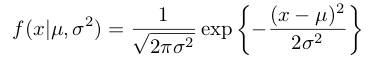
(x1,.....,xn)というデータが与えられたとすると、尤度関数は次のようになります。
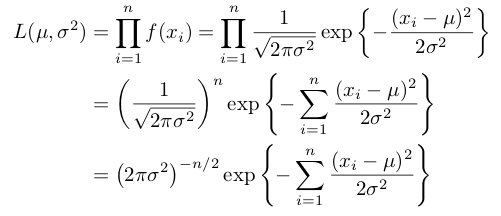
なので両辺に自然対数を取ると、以下のように対数尤度関数が導かれます。
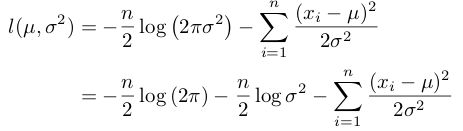
これから平均μを最尤推定法により推定します。対数尤度関数をμに関する関数と見て偏微分し、その結果が0となる値を求めます。
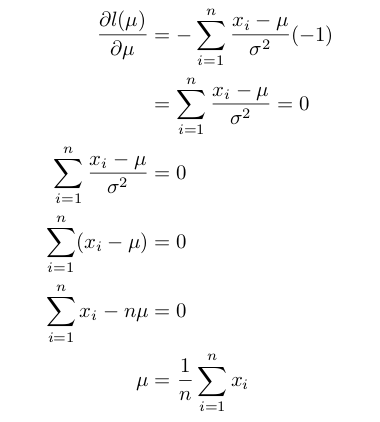
次に、分散σ^2を最尤推定法により推定します。対数尤度関数をσ^2に関する関数と見て偏微分し、その結果が0となる値を求めます。
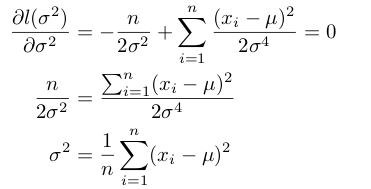
以上が最尤雨推定法の概要です。
2.勾配法
勾配法は最小値や最大値を求めるためのアルゴリズムで、解析的に解くことが困難な問題に用いられます。
「解析的に解けない」とは、ある関数に対してうまく微分ができない状態や実際に数値として表すには禁じせざるを得ない状況のことです。
勾配法は解析的に解くのが困難な時に有効なアルゴリズムで、最適化問題などに用いられます。 具体的な方法を解説していきます。
適当に初期点を決める
今いる位置における関数の値が最も小さくなる方向を計算する
その方向に微小単位で移動する
その後は、2,3の手順をひたすら繰り返し、収束した場合、この繰り返しを終了します。
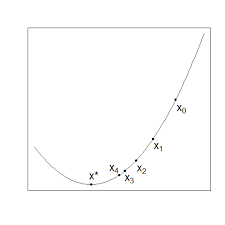
この例は解析的にも解けますが、勾配法を使って説明するとまずはじめにx0という点を初期値として選択します。
次に、今いる位置における関数が小さくなる方向を計算します。これは図からわかる通り、x1の方向に近づく方向になります。
ここからは今までの操作の繰り返しです。
すると、図からX*という点で今まで同様左側に移動すると関数の値が大きくなってしまいます。
つまり、図の範囲でパラメータとして最も良いものはx*ということになります。
3.最尤推定法の問題点
データ数が少ない時に偏りがあることです。
この例としてコインの裏表を3回投げるという試行を考えます。 もし、表が三回連続で出てしまった時、表の出る確率は最尤推定法で求めると1となりますが、本来表の出る確率は1/2であるはずです。 これがデータ数が少ないことによるパラメータの偏りです。
サンプルから構造を推測する モデルにおいては適していません。
例えば、混合正規分布、混合2項分布、神経回路網、ベイズネットワーク、 隠れマルコフモデルなどのもウール構造を持つモデルについては最尤推定法は適していません。 つまり、「尤度関数が最尤推定量の近傍でだけ 大きな値になる」という条件が最尤推定が安全に使えるための条件です。
また、尤度関数は常に解析的に解けるものではないので、最尤推定以外の方法でパラメータを求める必要があります。(勾配法など) 必ずしも全ての試行が確率分布に従うとは限らず、確率密度のある点における接線の傾きを測る勾配符が用いられるケースがあります。
関連記事

ご挨拶 AWS全冠エンジニアの小澤です。 今年の目標はテニスで初中級の草トーナメントに優勝することです。よろしくお願いいたします。 本記事の目的 本記事では、生成AIでVOC分析を行うことで得られた知見を共有したいと思います。 昨今、生成AIの登場など機械学習の進歩は目覚ましいものがあります。一方、足元では自社データの利活用が進まず、世の中のトレンドと乖離していくことに課題感を持たれている方も多いかと思います。また、ガートナーの調査(2024年1月)による

なぜ機械学習で双対問題を学ぶのか 結果から述べるのであれば、SVM(サポートベクトルマシーン)の原理で双対問題を使いたいからです。 これから実際どのように双対問題が使われているのか、また、双対問題の簡単な具体例を交えて説明していきたいと思います。 まずSVMについて簡単に説明したいと思います。 予測には過去のデータを使います。 しかし、外れ値のような余計なデータまで使ってしまうと、予測精度が下がるかもしれません。 そこで「本当に予測に必要となる一部のデータ

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数

目次 機械翻訳とは 機械翻訳の手法 現在の機械翻訳の欠点 欠点が改善されると 今後の展望 機械翻訳とは 機械翻訳という言葉を理解するために2つ言葉を定義する。 系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。 系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。 この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)