DEVELOPER’s BLOG
技術ブログ
自然言語処理の予測理由を説明する WT5?! Training Text-to-Text Models to Explain their Predictions

概要
今回は、以前ブログで紹介したText-to-Text Transfer Transformer(T5)から派生したWT5(Why? T5)を紹介します。
Text-to-Text Transfer Transformerとは、NLP(自然言語処理)のタスクをtext-to-text(テキストを入力して、テキストを出力する)形式として考えたもので、様々なタスクでSoTA(State of the Art=最高水準)を獲得しました。こちらの記事で詳しく紹介しています。Googleが発表した自然言語処理モデルText-to-Text Transfer Transformer(T5)とは?
このT5を改良したWT5のポイントは、"Why T5?"という名前にもある通り、予測に対してその予測の根拠となる説明を与えるということです。
近年、大規模な事前学習モデルをはじめとするニューラルネットワークをNLPタスクに使用することで、人間を超えるような性能を達成するようになってきました。しかし、ニューラルネットワークの問題点として、なぜモデルがそのような予測をしたのかが分からない、いわゆる「ブラックボックス」になっているということが挙げられます。この問題を解決するためにWT5では、タスクの答えに加えて根拠を説明する文も与えています。この背景には、人間も意思決定の理由もブラックボックスになってはいるが、求めると理由を説明できるため、機械にも同じことを求めています。
手法
解釈可能性と説明生成
予測の根拠を与える方法として採用されている3つを紹介します。
ルールベース
予測をするルールをあらかじめ与えて、そのルールの基づいて予測をする手法です。たとえば、「ひどい」という単語が入っていたらnegativeと判定するとしたら、「あの選手のプレーはひどかった」という文はnegativeと判定されます。この方法はあらかじめルールがあるので、予測の根拠は明らかになっていて解釈可能性は高いです。ただ、「あの選手のプレーにひどく感動した」のような文までnegativeと返してしまうことがあるので性能としてはあまりよくありません。
説明抽出
判定の根拠となる説明を入力の文字列からそのまま抽出してくる手法です。上の例でいうと「ひどかった」「ひどく感動した」を説明として抽出するイメージです。この手法だと、英語での"they"や日本語での「あれ」というような単語を含む文を抽出すると、単語が何を指しているのかわからないという問題が起こる可能性があります。
説明生成
言葉の通り入力を受けて判定する根拠を「説明抽出」のような制限なしに生成します。直感的に分かるような説明生成を正確におこなうことにより、人間に近い判断ができるようになります。
WT5では、基本的に説明生成を行いますが、説明抽出のタスクにも対応できるようにしています。
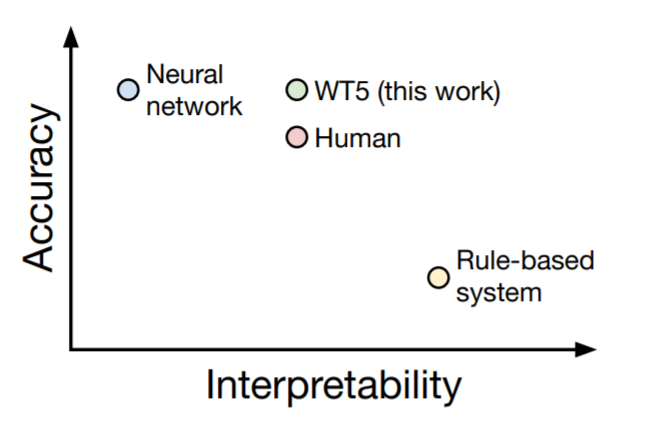
ここで解釈可能性と性能について、ルールベースの手法・従来のニューラルネット・WT5(提案手法)・人間で比べた図を見てみます。上で紹介したようにニューラルネットワークは性能は高くても解釈可能性は低く、ルールベースは性能が低くも解釈可能性は高いことが分かります。説明生成のWT5は人間と同等の解釈可能性を持ちながら、人間を超える性能を出しています。この図を見るだけでWT5の良さが分かります。
モデルのフォーマット
WT5モデルがテキストを入力してテキストを出力する様子を図を使って説明します。WT5のもととなったT5の入出力を見てみます。
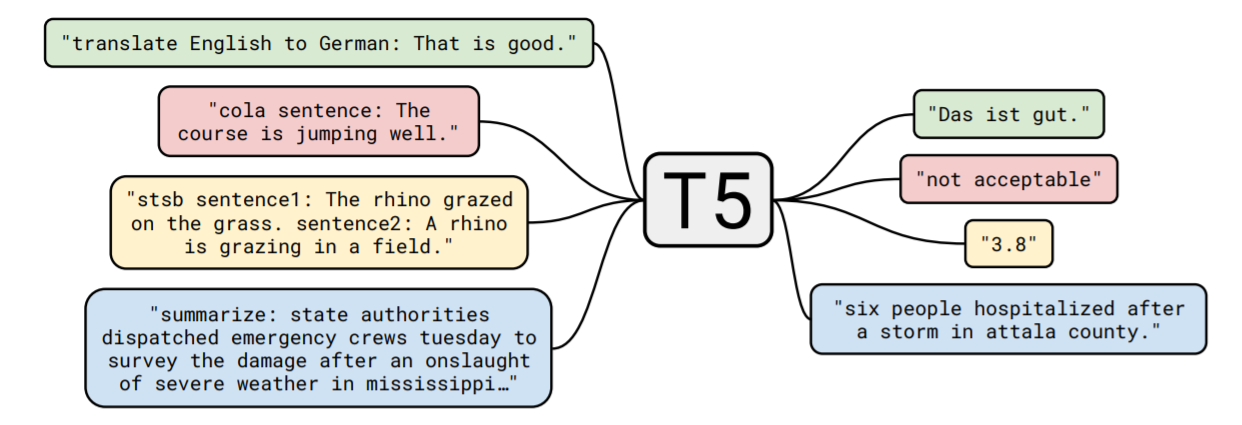
入力では先頭に"translate English to German"などタスクを表すテキストが与えられて、その後ろに"That is good."などのタスクを行う入力を与えています。出力は、単に入力に対しての答えのみを返します。
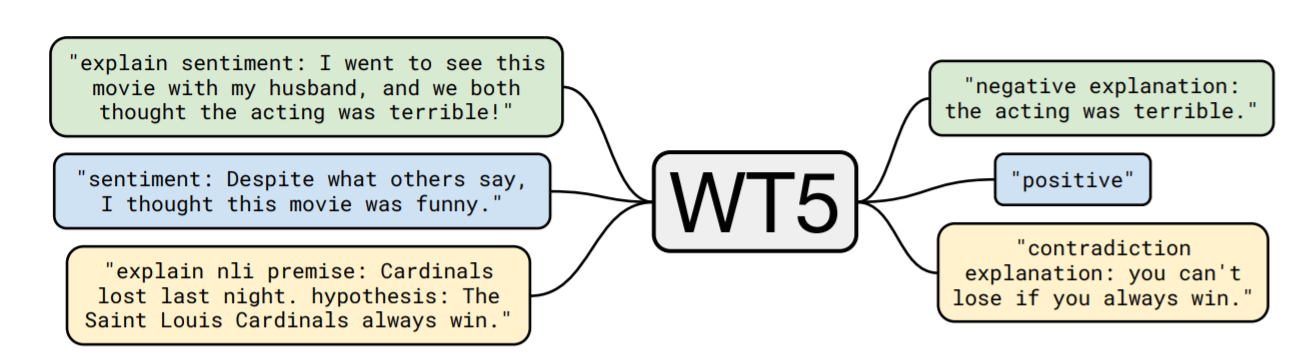
それに対してWT5では、説明文を生成したい場合、入力の先頭に"explain sentiment"など、"explain"+タスクという形式のテキストを与えることで、出力では"negative explanation"+説明ような、タスクの答え+"explanation"+根拠となる説明という形式のテキストを返して、タスクの答えとともに根拠となる説明も同時に返します。 また、説明は出力せずにタスクの答えのみを出したい場合には、図の青い部分のように、入力の先頭にタスク名のみを与えればその答えのみを与えられるようにモデルを構築しています。
説明生成だけでなく説明抽出のタスクにも対応でき、その場合は入力の先頭の"explain"の部分を"explanation"変えることで、説明文を抽出するように訓練されています。
訓練
訓練に使用するデータセットは次の4つです。
e-SNLI
SNLIデータセット(前提と仮説が与えられて、前提に対して仮説が正しいのかを判定。それぞれのデータに対して正しい(entailment)、矛盾(contradiction)、どちらでもない(neutral)の中からいずれかがラベルとしてついている)について、それぞれのラベルに対する根拠となる説明テキストをアノテーションしたデータセット
Cos-E
Commonsense Question-Answering(CQA)データセット(一般常識についての質問応答セットで、質問に対して選択肢とその中から回答が与えられている)に、選択の根拠となる説明テキストをアノテーションしたデータセット
Movie Reviews
映画レビューの感情分析データセット(一つの映画レビューに対して、positive/negativeのラベルがついている)に、判定の根拠となるテキストを説明抽出によりアノテーションしたデータセット
MultiRC
MultiRCデータセット(文章が与えられて、その文についての質問と答えの候補が与えられていて、候補それぞれTrue/Falseのラベルが与えられている)に、説明抽出による説明がアノテーションされている
モデルの学習は、2種類のT5モデルを使ってファインチューニングを行います。一つは2億個のパラメータを持つBaseモデルで、もう一つが110個のパラメータを持つ11Bモデルを使います。ファインチューニングの方法としてはT5モデルの際と同様のダウンストリームタスクにより行っています。
学習率・バッチサイズ等、訓練の詳しい設定については論文をご覧ください。
評価
評価に使用する指標は、分類精度に対してはMultiRCのみF1スコアを採用して、それ以外はAccuracy、生成された文に対しては量的な評価として、説明抽出を行うタスク(Movie Reviews, MultiRC)についてはF1スコア、説明生成を行うタスク(e-SNLI, CoS-E)についてはBLUEを使用しています。 また、量的は指標だけでは説明の質についてが十分に評価することができないので、質的な評価として人間による評価も行っています。NLPのタスク、特に対話や今回のような文章を生成する際には人間の評価が重要になることがあるので、そこも注意深く見ていく必要があります。
実験
まずは、それぞれのデータセットでどうなるのかを見ていきます。

結果を見ると、WT5-11Bがかなり高い性能を出しており、分類精度では2つ、説明文の評価では3つのタスクでSoTAを獲得しています。また、WT5-Baseでもそれなりのスコアを出せています。この結果はT5のときと似たような感覚です。
説明文の評価を見てみると、説明生成というタスクの性質を考えると量的なスコアが低めに出るのは必然なのかなと思います。ただ、論文中でも述べられているように、Cos-Eタスクの値は他と比べてもかなり低くなっていて、これはアノテーションした説明文の質があまりよくないことが原因ではないかとされています。人間が生成した説明文に対する人手による評価も低めに出ているので、そもそも人による説明がブレるようなタスクに対しては、性能が上がりにくいのかもしれません。
MultiRCでも、人による評価については同じような傾向があるようにも見えるので、個人的には、一般常識や読解など人により考えが変わるようなタスクでは、説明が難しくなってくるのかなと思います。ただ、この辺の評価はどう捉えるのかが難しい部分も出てくるので一概には言えないと思います。
実際にWT5(11B)が生成・抽出した説明文です。

説明文を減らしての実験
次に、教師データとなる説明文を減らした場合にモデルの性能がどうなるのかを評価しています。
目的は、アノテーションをして説明文を付与する手間が省けるのかどうかを確認するためです。もし性能が変わらなければ、他のデータセットも簡単に使うことができる可能性があります。

結果を見ると、e-SNLIについては、Accuracyはほとんど変わらず、BLUEに関しては説明文を減らしていくと値が低下するものの、100まで減らしても従来のSoTAよりも高い数値を出しています。
Cos-Eについてもほとんど値は変化せず、説明文を減らしても影響は見られません。
それに対して、Movie Reviewsに関しては説明文を減らしていくとかなり性能が落ちていることが分かります。
また、グラフにはないですが、MultiRCもMovie Reviewsと同じような性能の低下があることから、説明抽出を行うタスクには説明文の教師データがそれなりに必要であることが分かります。
データセット間での転移
説明生成のタスクでは説明文の教師データ説明文が少なくても性能が下がらないことが分かったので、同じタスクの説明文を持たない他のデータセットを合わせて使用してうまくいくかを見ていきます。
具体的にはe-SNLIデータセットとMNLIデータセットを合わせて使用した場合と、Movie ReviewsとIMDb、Amazon Reviewsを使用した場合を見ます。MNLIとIMDb、Amazon Reviewsはそれぞれe-SNLIとMNLIよりもより多くのドメインを含んでいます。
それぞれの場合について今までと同様に学習させて、タスクの分類精度は上と同様の評価で、生成した説明文については人による評価を行います。
分類精度は、MNLI:91.5%・IMDb:97.2%・Amazon Reviews:98.1%とかなり良く、説明文の評価もMNLI:82%・IMDb:94%となっていて説明文生成もうまくいっていることが分かります。このことから、ドメインの異なる文章に対しても対応できることが分かります。
このような説明文が生成・抽出されます。

タスク間での転移
最後に、異なるタスクのデータセットに対して学習を行ってもうまくいくのかを見ていきます。
具体的には、説明文ありのe-SNLIデータセットと説明文なしのe-SNLIデータセット、説明文なしのCoS-Eデータセットを使ってファインチューニングして、CoS-Eに対して説明文が生成できるかを見ます。e-SNLIとCoS-Eは全く違うタスクで、CoS-Eについては説明文を一つも与えていないので"zero-shot"になっています。
結果としては、完全にうまくいったとは言えないようですが、下のようにうまくいったものもあるのでタスク間での転移も可能だろうとしています。この辺は残った課題としていますね。 また、詳細については述べませんが、"bean-search decoding"を使うと説明の信頼性が改善されたようです。

まとめ
今回はText-to-Text Transfer Transformer(T5)をもとにした、予測と説明文を生成するWT5(Why? T5)について紹介しました。
まだ改善の必要があるものの、説明文生成などができればブラックボックスなものが解消されますし、アプローチはかなり異なってきます。将来的にはNLPだけでなく、他の分野のタスクでも説明文生成することができれば説明可能なAIの開発につながっていくかもしれません。 これからもtext-to-textの広がりに注目したいです。
参考文献
WT5?! Training Text-to-Text Models to Explain their Predictions
WT5?! Text-to-TextモデルでNLPタスクの予測理由を説明する手法!
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 機械翻訳とは 機械翻訳の手法 現在の機械翻訳の欠点 欠点が改善されると 今後の展望 機械翻訳とは 機械翻訳という言葉を理解するために2つ言葉を定義する。 系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。 系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。 この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)

フェイクニュースは珍しいものではありません。 コロナウイルスの情報が凄まじい速さで拡散されていますが、その中にもフェイクニュースは混ざっています。悪意により操作された情報、過大表現された情報、ネガティブに偏って作成された情報は身近にも存在しています。 これらによって、私たちは不必要な不安を感じ、コロナ疲れ・コロナ鬱などという言葉も出現しました。 TwitterやInstagramなどのソーシャルメディアでは嘘みたいな衝撃的なニュースはさらに誇張な表現で拡散

Googleが発表したBERTは記憶にも新しく、その高度な性能はTransformerを使ったことで実現されました。 TransformerとBERTが発表される以前の自然言語処理モデルでは、時系列データを処理するRNNとその発展形であるLSTMが使われてきました。このLSTMには、構造が複雑になってしまうという欠点がありました。こうしたなか、2017年6月に発表された論文「Attention is all you need」で論じられた言語モデルTran

最近はGoogleを始めとする翻訳サービスにも機械学習が取り入れられ、翻訳精度が向上しています。 しかし、完璧な翻訳を求めるには精度が足りず、確認作業に時間がかかったり、翻訳されたものが正しいのか見極めるスキルが必要なケースがほとんどです。 このような課題がある中、高精度な翻訳ができる「DeepL」が、日本語と中国語の翻訳に新しく対応したので、日本語での翻訳機能を試してみました。 DeepLとは DeepLはドイツのケルンで開発された深層学習(ディープラー