DEVELOPER’s BLOG
技術ブログ
機械学習活用事例|パーソナルカラー診断システム

概要
自分に似合う色、引き立たせてくれる色を知る手法として「パーソナルカラー診断」が最近流行しています。
パーソナルカラーとは、個人の生まれ持った素材(髪、瞳、肌など)と雰囲気が合う色のことです。人によって似合う色はそれぞれ異なります。
パーソナルカラー診断では、個人を大きく2タイプ(イエローベース、ブルーベース)、さらに4タイプ(スプリング、サマー、オータム、ウィンター)に分別し、それぞれのタイプに合った色を知ることができます。
パーソナルカラーを知るメリット
- 自分をより好印象に見せることができる
- 自分に合うものを知って、買い物の無駄を減らせる
- 本来の魅力を発見できる
現在、「パーソナルカラー診断」と検索すると、膨大な量のページが見つかります。しかしそれらのほとんどは設問に自分で答える自己申告タイプでした。
ほんとにこれで合ってるの?と疑問に感じることもあるでしょう。
専門家に見てもらうにはお金も時間もかかるし正直面倒臭い。写真や動画で、自宅で気軽に判断できたらいいのに...なんて思いませんか?
今回は、「パーソナルカラー診断サービス」を機械学習を用いて製作しました!
どうやるの? 機械学習のしくみ
今回の作業の流れです。
①画像を収集→②パーソナルカラー(4パターン)の正解を付け→③モデルを作成→④モデルに②の画像を学習
→⑤学習させたモデルに新たな画像を投入(テスト)→⑥画像に対してパーソナルカラーを判定→⑦精度向上のための考察
この作業で大まかには正解のパーソナルカラーを予測できるシステムが作成できました。
技術を詳しくご紹介します。
訓練データの確保
[芸能人の名前 パーソナルカラー] で調べると、その人のパーソナルカラーが分かります。それを参考にして判定用のモデルを作成しています。
学習をイチからするためには相当量のデータが必要なので、今回は予め学習されたモデルの一部を基にして層を追加する転移学習という手法でモデルを作成しました。
実装はkerasを用いて行います。kerasでは様々な事前学習済みモデルが用意されています。
ImageNet検証データでのスコアがそれぞれ出ていますが、どのモデルが今回のケースに一番うまくマッチしてくれるかは試すまでわからないのでひとまずVGG16と、ここでのベンチマークで一番精度の高いInceptionResNetV2を選びました。
InceptionV3という別のモデルもありますが、所々 InceptionResNetV2をInceptionモデルと略すところがあります。
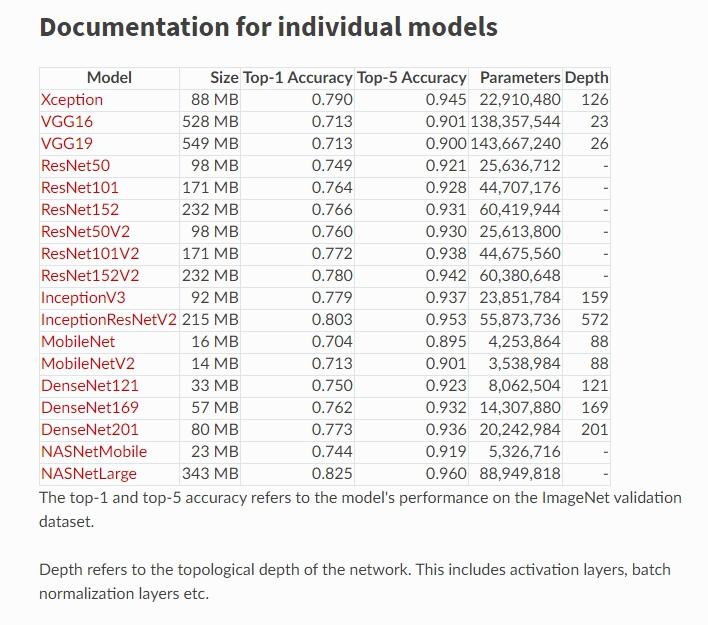 (引用)https://keras.io/applications/
(引用)https://keras.io/applications/
├─personal-color │ ├─data │ ├─images │ │ ├─autumn │ │ │ └─original │ │ ├─spring │ │ │ └─original │ │ ├─summer │ │ │ └─original │ │ └─winter │ │ │ └─original │ ├─scripts
というフォルダ構造で季節ごとに階層を分け、収集してきた画像をoriginalに格納しています。この時、画像の名前は、通し番号のみで管理しています。
この後学習させるにあたってパーソナルカラーを決める上で重要な要素となる顔の形や目だけにトリミングして別画像として保存することを考えたため、originalという形で保存しています。
収集した画像から顔を切り取るのに加えて、目だけ、口だけを切り取るために、dlibのランドマーク検出を使います。
ランドマーク検出とは、顔から要所となる点を検出するものです。
 (引用)https://docs.opencv.org/master/d2/d42/tutorialfacelandmarkdetectioninanimage.html
(引用)https://docs.opencv.org/master/d2/d42/tutorialfacelandmarkdetectioninanimage.html
import logging
import os
import shutil
import cv2
import dlib
import numpy as np
from PIL import Image, ImageFilter
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential, Model
from keras.layers import Input, Dense, Dropout, Activation, Flatten
from keras import optimizers
from keras.applications.vgg16 import VGG16
from sklearn.model_selection import train_test_split
LABELS = ['spring', 'summer', 'autumn', 'winter']
PARTS = ['face', 'eyes', 'mouth']
for season in LABELS:
pathList = ['../images', season, 'original']
rootPath = os.path.join(*pathList)
files = os.listdir(rootPath)
files.remove('.DS_Store')
for file in files:
filePath = os.path.join(rootPath, file)
img = cv2.imread(filePath)
rects = detector(img, 1)
PREDICTOR_PATH = ('../data/shape_predictor_68_face_landmarks.dat')
logging.debug('--- fetch each coordinates from settled index ---')
for rect in rects:
face = rect
predicted = predictor(img, rect).parts()
left_eye = predicted[36:42]
right_eye = predicted[42:48]
mouth = predicted[48:]
partsList = [left_eye, right_eye, mouth]
logging.debug('--- trimming and save images ---')
savePart() # 上で求めた領域をそれぞれトリミングする。
一部略
モデルの作成
画像を入力用に再度加工し、モデルを作っていきます。
訓練用データは少し水増しを加え、テストデータはそのまま使います。前述の通り今回はVGG16とInceptionResNetV2を使っています。
def imagePreprocess(self):
trainDataGen = ImageDataGenerator(rescale=1 / 255,
shear_range=0.2,
zoom_range=0.2,
rotation_range=60,
brightness_range=[0.8, 1.0],
horizontal_flip=True,
vertical_flip=True)
self.trainGenerator = trainDataGen.flow_from_directory(directory=self.trainFolder,
target_size=(
self.IMG_HEIGHT, self.IMG_WIDTH),
color_mode='rgb',
classes=LABELS,
class_mode='categorical',
batch_size=self.BATCHSIZE,
shuffle=True)
testDataGen = ImageDataGenerator(rescale=1 / 255)
self.testGenerator = testDataGen.flow_from_directory(directory=self.testFolder,
target_size=(
self.IMG_HEIGHT, self.IMG_WIDTH),
color_mode='rgb',
classes=LABELS,
class_mode='categorical',
batch_size=self.BATCHSIZE,
shuffle=True)
def vgg16Model(self, summary=False, name='model', verbose=1, lr=1e-4, epochs=25, freezefrom=0, optimizer='RMSprop'):
input_tensor = Input(shape=(self.IMG_HEIGHT, self.IMG_WIDTH, 3))
vgg16 = VGG16(include_top=False, weights='imagenet',
input_tensor=input_tensor)
if summary:
vgg16.summary()
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(len(LABELS), activation='softmax'))
self.model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
if summary:
self.model.summary()
vgg16.trainable = True
if freezefrom == 0:
for layer in vgg16.layers:
if layer.name == 'block5_conv1':
layer.trainable = True
else:
layer.trainable = False
else:
for layer in vgg16.layers[:freezefrom]:
layer.trainable = False
if optimizer == 'RMSprop':
self.model.compile(loss='categorical_crossentropy',
optimizer=optimizers.RMSprop(lr=lr), metrics=['acc'])
if optimizer == 'SGD':
self.model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=lr), metrics=['acc'])
history = self.model.fit_generator(self.trainGenerator, steps_per_epoch=25, epochs=epochs, validation_data=self.testGenerator,
validation_steps=10, verbose=verbose)
self.history.append(history)
self.model.save(os.path.join(
*[self.baseDir, 'data', name + '.h5']), include_optimizer=False)
def inception_resnet(self, name='model', lr=1e-4, epochs=25, trainFrom=0):
resnet_v2 = InceptionResNetV2(include_top=False, weights='imagenet',
input_tensor=Input(shape=(self.IMG_HEIGHT, self.IMG_WIDTH, 3)))
model = Sequential()
model.add(Flatten(input_shape=resnet_v2.output_shape[1:]))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(LABELS), activation='softmax'))
if trainFrom == 0:
resnet_v2.trainable = False
else:
for layer in resnet_v2.layers[:trainFrom]:
layer.trainable = False
self.inception_model = Model(
input=resnet_v2.input, output=model(resnet_v2.output))
self.inception_model.compile(
loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
hist = self.inception_model.fit_generator(
self.trainGenerator, epochs=epochs, validation_data=self.testGenerator, steps_per_epoch=25)
self.history.append(hist)
self.inception_model.save(os.path.join(
*[self.baseDir, 'data', name + '.h5']), include_optimizer=False)
結果は?
目と口のみで学習させたモデルの結果はval accが0.25に非常に近いものでした。4クラス問題なので、これでは全く意味がありません。
一方顔全体での結果は以下の通りでした。
Inception Epoch 25/25 25/25 [==============================] - 18s 709ms/step - loss: 0.7033 - acc: 0.7200 - val_loss: 2.7571 - val_acc: 0.4781 VGG16 Epoch 25/25 25/25 [==============================] - 11s 458ms/step - loss: 1.0617 - acc: 0.5225 - val_loss: 1.2682 - val_acc: 0.4230
学習時間はColab Tesla T4でInceptionが約10分、VGGが5分ほどでした。
決して非常に高機能なモデルとは言えませんが、目のモデルと比べると顔全体を使用したモデルが良さそうです。何より、私自身がパーソナルカラー診断をしたら確実に0.25を下回るくらい難しい分類だったので満足の行く結果に見えます。過学習していなければですが。
ということで過学習に震えながら別のテストをすると、内実は惨憺たるものでした。
VGGモデルに関しては、少し夏と冬が多くあとはほぼランダムな出力でした。上振れでテストスコアが上下するような感じです。
一方Inceptionモデルは、夏と冬のテストに関しては約8割ほどの正解率でした。しかし、春と秋はほとんどが夏、冬と回答されていて、春か秋と答えられたのは、100件中2件ほどでした。オリジナルデータ数はこの時すべて同じ枚数で設定していたのでこのような偏りはすごい不思議なものでした。
どうしてこうなったのか原因を考えていきます。
精度向上のための原因考察
仮説その1 パラメータに問題がある
ハイパーパラメータに問題があって過学習している可能性を考え、learning rateを1e-2 - 1e-5まで変化させてテストをしました。また、ファインチューニングという新しいモデルを追加するだけではなく、以前のモデルの一部を学習時に用いるという手法も試しました。
結果として、概してval accの結果が良いのは1e-4のときでした。
1e-5では、25epochsだと少したりないような印象を受けました。上述のスコアも1e-4にしたときのスコアです。しかし、スコアの微小な上下はあれど、本質的な偏りの修正には至りませんでした。
仮説その2 モデルがそもそもあっていない
人間の顔をその雰囲気から分類するというタスクがこれらのモデルにあっていないのではないか。しかし、これを言ってしまうと本末転倒です。
もともと訓練データを集めづらい分野において、予め学習してあるモデルを転用するというコンセプトが転移学習ですし、一旦考えなかったことにします。
仮説その3 訓練画像の質が悪い
画像の質と言っても、様々な要素があります。
画質、水増しでゴミができていないか、正しいクラスに分類されているかetc...
今回訓練に使ったのは芸能人の画像でした。もともと、化粧や照明の影響で印象が変わることは危惧していましたが、とりあえずモデルに投入していました。
今一度初心に帰り、これらを見直すことにしました。
基準が私では判断ができないので、当社腕利きのパーソナルカラー診断士が人の目で答えがわかっているテスト画像を再度精査をしました。
すると驚くことに、VGGモデルで、学習機の導き出していた答えが人の目の意見と一致するものが多々ありました。
人の目でも即座に判断できるものは正解しており、判断が難しいものに関しては、イエローベース、ブルーベースの2択までは絞り込めるという感覚でした。
つまり、テストデータとして与えていたラベルが間違っていただけで学習機は頑張って学習していたのに、画像を収集する際にこの人はこの季節、とその写真のときの状態を見ずに決めてしまっていたため引き起こされてしまったのです。
この結果を受けて、再度すべての画像を再分類することにしました。
VGGモデルでは偏りが減り、正解率も微小ながら上がりました。しかし、Inceptionモデルでは逆に夏と冬しか結果として出力されないようになってしまいました。
このモデルは(他もそうですが特に)非常に複雑なモデルなので、難しい学習の果てに夏と冬だけに焦点をあてた方が精度が上がると判断されてしまったのかもしれません。データ数に不均衡はないので今回は仮説その2として切り上げます。
(参考)https://qiita.com/koshian2/items/20af1548125c5c32dda9
まとめ
一番の原因がデータ処理が甘かったというなんとも情けのないものでした。
色々なところで色々な人が機械学習の8割は前処理といったことを口を酸っぱく言っている意味を再度認識しました。
また、とんでもなく巨大なBiTという新モデルが2019年の12月に発表されたので、次回はこれも試してみたいです。
(参考)https://qiita.com/omiita/items/90abe0799cf3efe8d93d
AI・機械学習を活用したシステムが少しずつ普及しています。今回のように画像を用いた判定・予想は人の手をシステムに代替するために便利な手法です。
例えば、人がおこなっている不良品チェックを機械学習でおこなったり、複数の散乱している物をなにであるか判定し金額を表示することで無人レジを作成したり...。
リモートワークや自由な働き方が進んでいる中、人間とシステムが上手に共生する社会がすぐそこまで迫ってきています。
当社ではAI・機械学習を活用したソリューションを提案しています。
アクセルユニバースの紹介
私達はビジョンに『社会生活を豊かにさせるサービスを提供する。』ことを掲げ、このビジョンを通して世界を笑顔にしようと機械学習・深層学習を提案しています。
ミッション(存在意義)
私達は、情報通信技術を使って万物(全ての社会、生物)の暮らしをよりよくすることに貢献し、 それを加速させることを使命とします。ビジョン(目標とする姿)
社会生活を豊かにさせるサービスを提供する。バリュー(行動規範)
- 変化を求め、変化を好み、変化する
- 自分の高みを目指してどんどん挑戦する
- お客様と一蓮托生でプロジェクトを進める
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 実装前の課題 採用した技術と理由 実装した内容の紹介 改善したこと(抑制できたコスト) 実装前の課題 SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。 弊社では2021年2月からSRE活動を行っており、セキュリ

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数