DEVELOPER’s BLOG
技術ブログ
BERTやAttentionでの口コミ分析で顧客の本当の声を見つけよう

サービスへのお客様の評価はその場では気付きにくく、特にネガティブなものは直接伝えてはくれません。
しかしお客様の声を知ることはより満足してもらうためには必須です。
今回は口コミサイトに投稿されたレビューを分析し、お客様の本当の声を知るためのサービスを紹介します。
0.サービス紹介_口コミ分析
Web上で集めた口コミ(レビュー)をAIが精査し、ネガティブな口コミはネガティブな原因を特定します。
数が少ないうちは手作業で評価の精査が出来ますが、数が多くなってくるとそういう訳にもいきません。
大量の口コミを一から全て見ていくとなると大量の人手、時間がかかります。
そのコスト削減に向けて口コミ文章をAIに評価させネガティブなものだけを選別し、改善のための時間を創出しましょう。
前回のブログでosetiというライブラリを用いて口コミをネガポジ分析しましたが、これには問題点がありました。
- 日本語評価極性辞書に載っていない単語が出現した際、それらを定量的に評価できない。
- 極性辞書の単語の評価には作成者の感情が入っているので、客観的な評価が完璧にできない。
- 1文ごとにネガポジ判定を行うので、文章全体で見たときに文脈を読み取れない。
特に3.について、1つの口コミ全体で見た時にそれがかなりポジティブなものであっても、トータルで見た時に「かなり」の部分をAIは読み取れませんでした。
また、全体的にポジティブなレビュー(=口コミ) でも、一部ネガティブな内容が含まれているケースもあります。
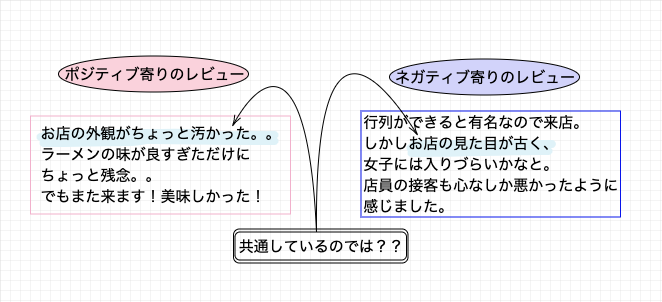
このような "ポジティブ寄りのレビュー" 中に含まれるネガティブな内容について、このように仮定しています。
ポジティブ寄りのレビューにもネガティブな内容を含んでいるものがあり、「自店のネガティブなイメージを発見したい」という目標を達成するためには、これらも発見しなければなりません。
そこで、図のような関係があると仮定し、今回はネガティブ寄りのレビューを発見していくことにします。
1.口コミの抽出
ランダムに抽出した東京都内にあるラーメン店で、約800件のレビューをGoogle口コミから抽出しました。一部です。

このように約800件のレビューを抽出し、ポジティブは「1」ネガティブは「0」とラベリングを行いました。
2.そもそもBERTとは?
ではBERTにこれらのデータを学習させ、評価をしていきましょう。BERTについて簡単に説明をします。
BERT
BERT ( Bidirectional Encoder Representations from Transformers )は2018年にGoogleが発表したNLPモデルであり、その翌年には検索エンジンにも導入されました。この導入に対しては「過去最大のアップデート」と呼ばれ、メディアにも大きく取り上げられました。
このBERTの特徴はなんといっても「(文章における) 文脈を理解できる 」ことでしょう。
BERTが発表される以前のNLPモデルでは、「魚介じゃないラーメン」と「魚介 ラーメン」がほぼ同じように認識されていました。 これまでのモデルは「魚介」「じゃない」「ラーメン」と個別に理解できることは可能でしたが、「じゃない」という単語が「魚介」にかかっていることを認識できずに、結果文章の中で意味が明確な「魚介」「ラーメン」の二語が強調されてしまうことが原因でした。
しかしこのBERTでは、「魚介じゃないラーメン」のうち、「じゃない」という単語が「魚介」にかかるという文法上の構造を理解することができるのです。 このようなBERTの処理能力の高さは、今回例にした「魚介じゃないラーメン」のような短いワード以上に、「銀座駅で10分以内に魚介じゃないラーメンを食べたい」などの文章となった場合に、より力を発揮すると推測されます。
Googleが導入したBERTとは?誰でもわかるBERTの特徴を解説より引用
このBERTについての詳しいアルゴリズムについては、本記事のレベルを逸脱するため割愛します。(7.参考文献を参照)
3.口コミ分析の実装
BERTについては、こちらのサイトにあるBERT日本語Pretrainedモデルを用い、コーディングはBERTを用いたネガポジ分類機の作成を参考に実装しました。
この日本語Pretrainedモデルは、日本語全てのWikipediaの文章約1,800万文のテキストから、32,000語の語彙を事前学習したモデルです。
未知語抽出によるデータの前処理
この事前学習済みモデルはWikipediaの文章から単語を学習しているため、「おいしかった」「不快だった」などの感情を表す客観的な言葉が未知語として認識されています。そのため、未知語を抽出しvocab2というBERT語録辞書に入っている意味の似た単語と未知語を交換します。
例えば、「めっちゃ」を「とても」に、「不快だった」を「悪かった」などといったように変換していきます。
import re replaced_pos = [] replaced_neg = [] for i in range(len(pos)): replaced_pos.append(re.sub(r'おいしい', 'うまい', pos[i])) for i in range(len(neg)): replaced_neg.append(re.sub(r'不味い', 'ひどい', neg[i])) for i in range(len(neg)): replaced_neg[i] = re.sub(r'おいしい', 'うまい', replaced_neg[i]) for i in range(len(pos)): replaced_pos[i] = re.sub(r'らーめん', 'ラーメン', replaced_pos[i]) for i in range(len(neg)): replaced_neg[i] = re.sub(r'らーめん', 'ラーメン', replaced_neg[i]) . . .
レビューの評価に影響するであろう「味」「接客態度」「店内の雰囲気(衛生面など)」の3つに注目し変換しました。
サンプルの文章による推論とAttentionの可視化
レビューの評価にあたりAIが注目した箇所を色付けします。
前述したPretrainedモデルの utils/predict.py に学習済みモデルのビルド( buildbertmodel )と推論( predict )のメソッドを定義してあるので、
これらを利用してサンプルの文章をインプットし、予測値(Positive or Negative)とAttentionを可視化します。
from utils2.config import *
from utils2.predict import predict, create_vocab_text, build_bert_model
from IPython.display import HTML, display
input_text = "サンプルの文章を入力"
net_trained = build_bert_model()
html_output = predict(input_text, net_trained)
print("======================推論結果の表示======================")
print(input_text)
display(HTML(html_output))
結果は以下のようになります。(例としてPositiveとNegativeを1つずつ)


ここで[UNK]は未知語を、[CLS]は文の開始を表しています。また、Attentionの重み値が大きいほど背景色が濃い赤で表示されています。Attentionによって、AIは判定に必要であろう単語に"注目"していることが分かります。
Attentionについては参考文献でも紹介しています。
4.結果及び考察
最後にテストデータで実際に判定をします。 今回は全てのデータを「訓練データ:テストデータ=7:3」に分け、ハイパーパラメータ(バッチサイズ、エポック)は適宜変更して学習させていきます。
バッチサイズを8、16、32としそれぞれエポックを1~100まで設定した結果は以下のようになりました。
- 正解率 : 全サンプルのうち、正解したサンプルの割合
- 適合率(精度) : positiveと予測された中で、実際にpositiveであった確率
- 再現率 : 実際にpositiveであるデータに対して、positiveと予測された確率
- F値 : 適合率と再現率の調和平均
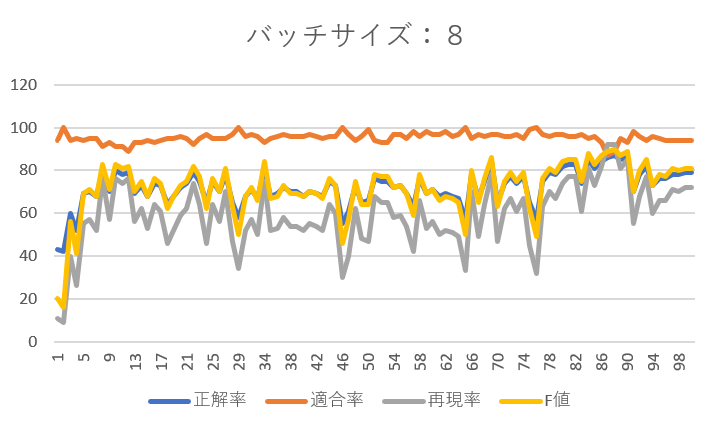
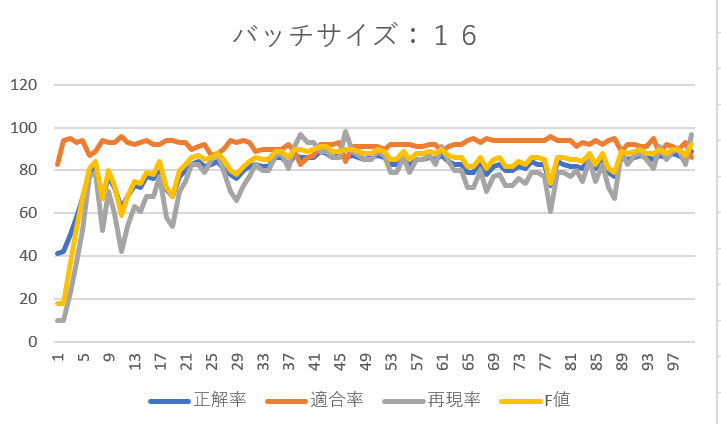
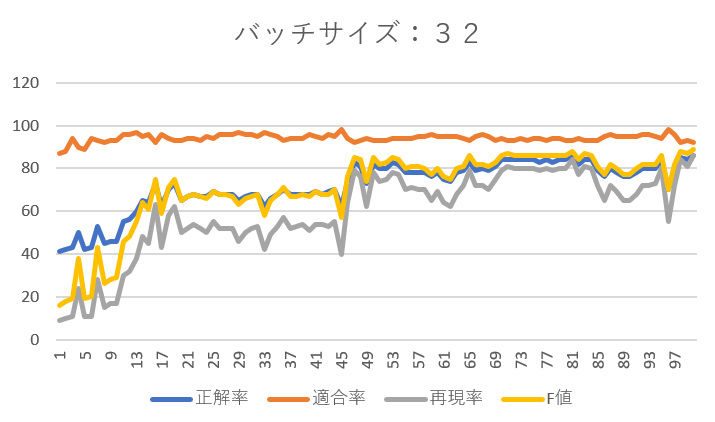
全体として適合率は90%前後と高い結果です。かなりの高精度でネガティブなレビューを抽出できています。(ネガティブが抽出できるということはポジティブも自ずと抽出できています。)
バッチサイズが8の時は再現率に波があり、エポック数を増やしても再現率が40%を下回るときがありました。そこでバッチサイズを16に変更したところ、エポック数の増加に伴い再現率もかなり向上しました。
次にバッチサイズを32として学習を進めると、エポック数45までは再現率70%前後でその後急低下、再び上昇し最終的には90%近くまで上がるという興味深い結果が得られました。
一見するとバッチサイズ16の時が一番学習が上手くいくように見えますが、3つのバッチサイズでは全体的に最終的なF値は90%前後で頭打ちとなる結果となりました。
参考までに訓練データに対する損失と正解率も見てみましょう。
- trainloss : 訓練データの損失(学習の時点でほぼ0)
- trainacc : 訓練データの正解率(学習の時点でほぼ1)
- valloss : バリデーションデータの損失(低い方が良い)
- valacc : バリデーションデータの正解率(高い方が良い)
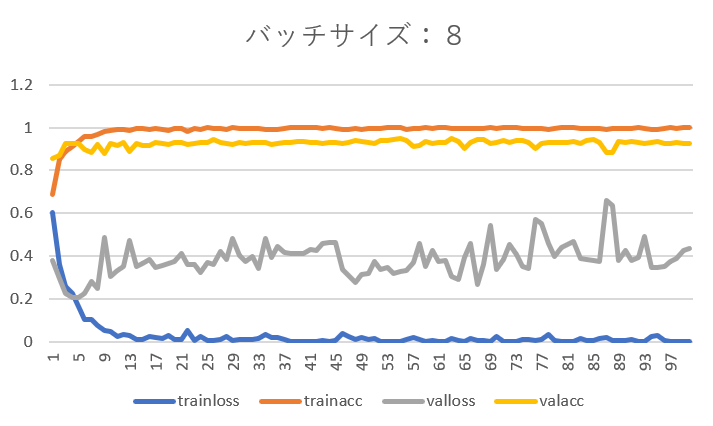
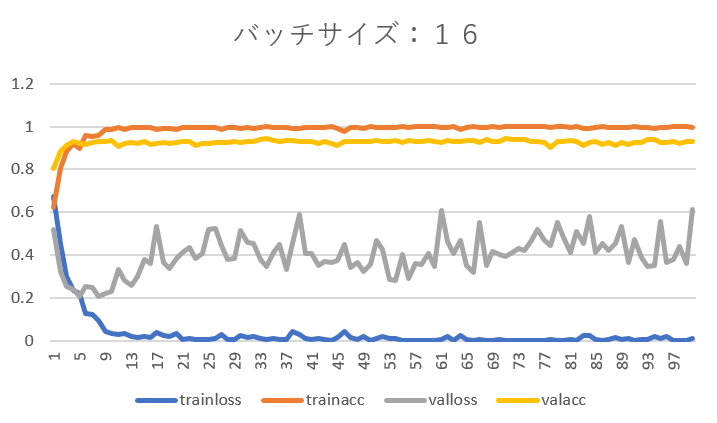
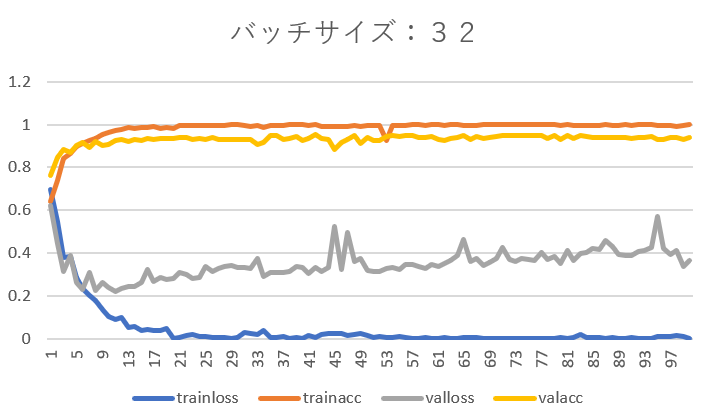
trainlossとtrainaccについては、訓練データで学習を行っているので自明の結果といって良いでしょう。
バリデーションデータの損失の山になっている(急上昇している)ところでは、それに対応して再現率は下がっていることが分かります。学習がうまく出来ていないということです。
5.【参考】口コミのグルーピング
今回の目的であったネガティブな口コミの選定は達成できることがわかりました。次にネガティブなレビューの原因を特定しましょう。
「clerk(店員の態度)」「shop(店内の雰囲気)」「taste(味)」「noodle(麺)」「soup(スープ)」「ingredients(具材)」の6つ(重複あり)に分けて棒グラフにします。
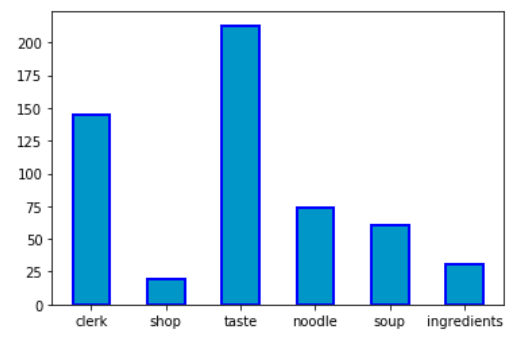
それぞれが原因のレビューの数です。味はもちろん、店員の態度も重要な要因なことが分かります。
EmbeddingProjectorを用いた可視化
EmbeddingProjectorを用いて可視化します。
知りたいカテゴリーを絞り込んでレビューを確認できるので、改善点をより発見しやすくなり、口コミを活かした業務改善が効率よく行えるでしょう。
EmbeddingProjectorは口コミの文章をword2vecによってベクトル化し、その後PCAによる次元削減を行い2or3次元空間上にマッピングすることによって可視化できます。
今回は「店員」「味」の2つを3次元空間に落とし込んでみます。まずはデータをロードし、下の画面右側のSearchのところで「店員」と検索します。
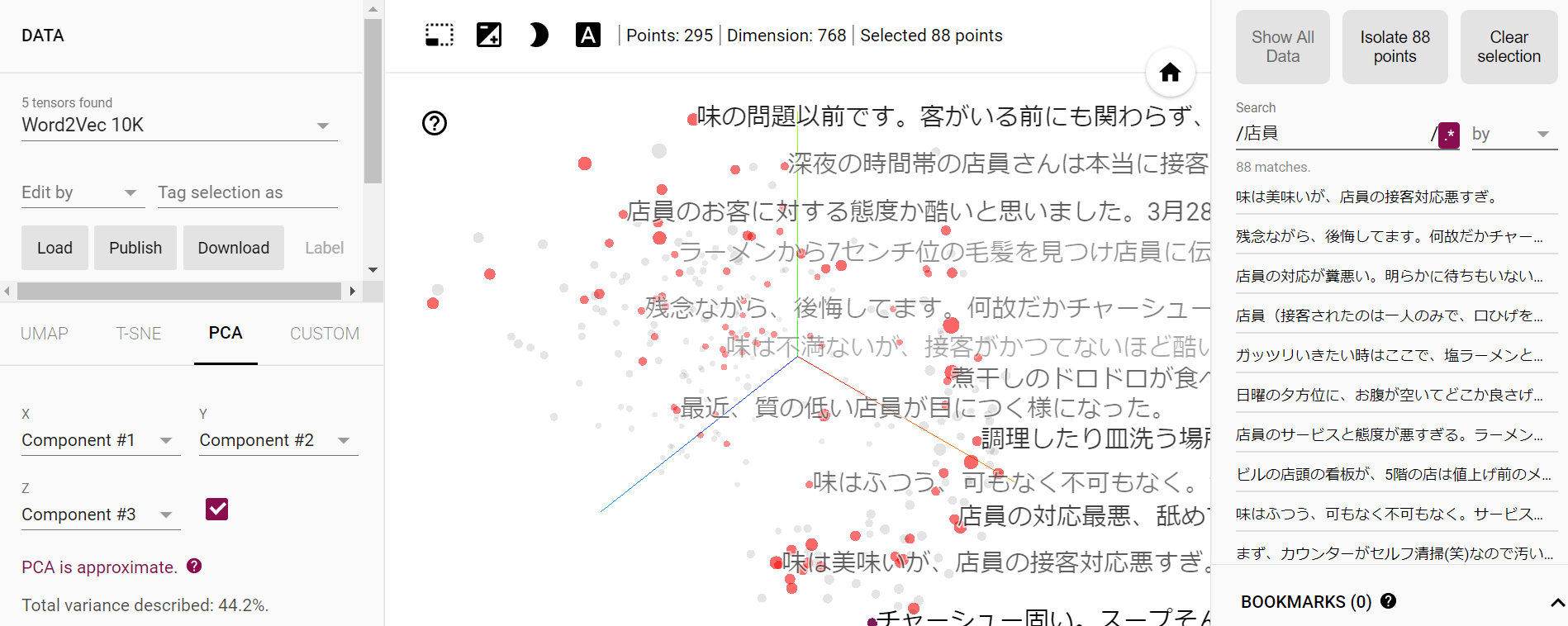
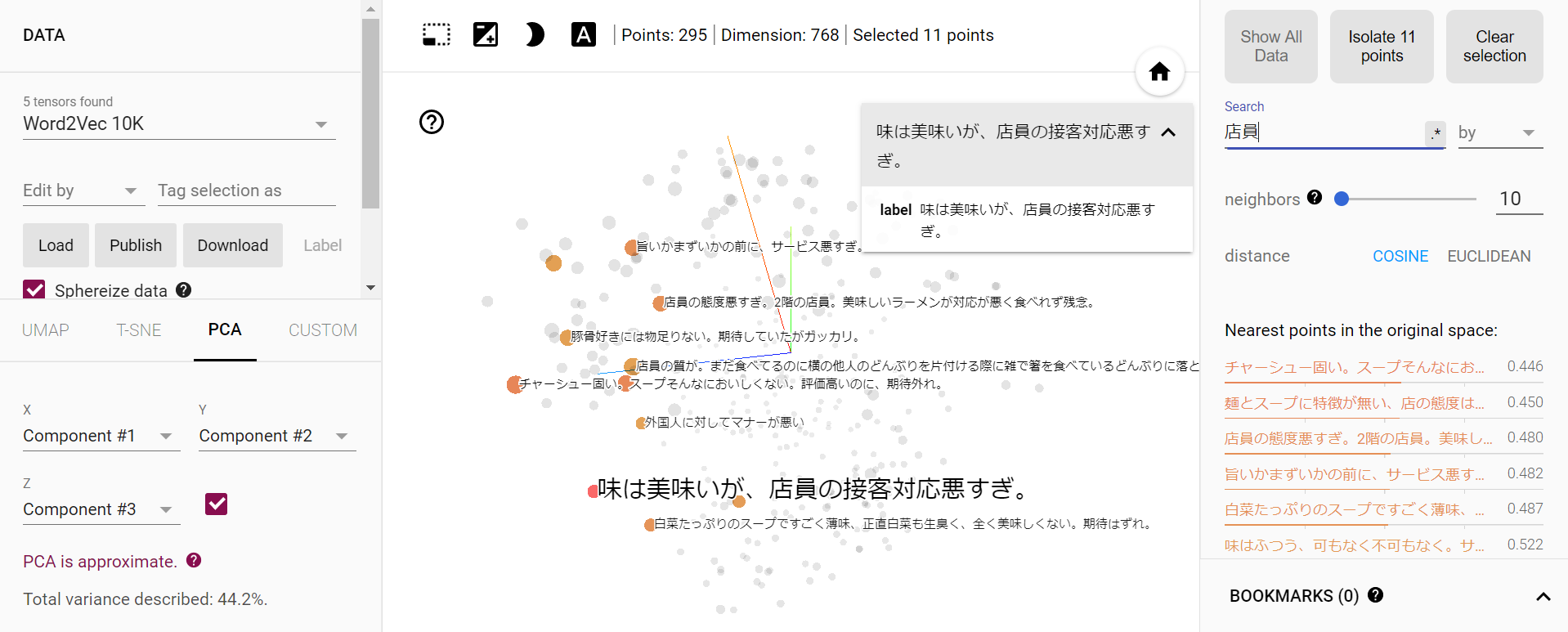
「店員」と含まれている口コミが計88件あり、3次元空間上にきちんとマッピングできています。 その中で基準となる口コミを一つ選択し、下の画面右側のneighbor(近傍)を10などと設定すると、基準となる口コミから距離の近い(意味の近い)口コミが10個マーキングされます。
同じように「味」についてもみていきましょう。
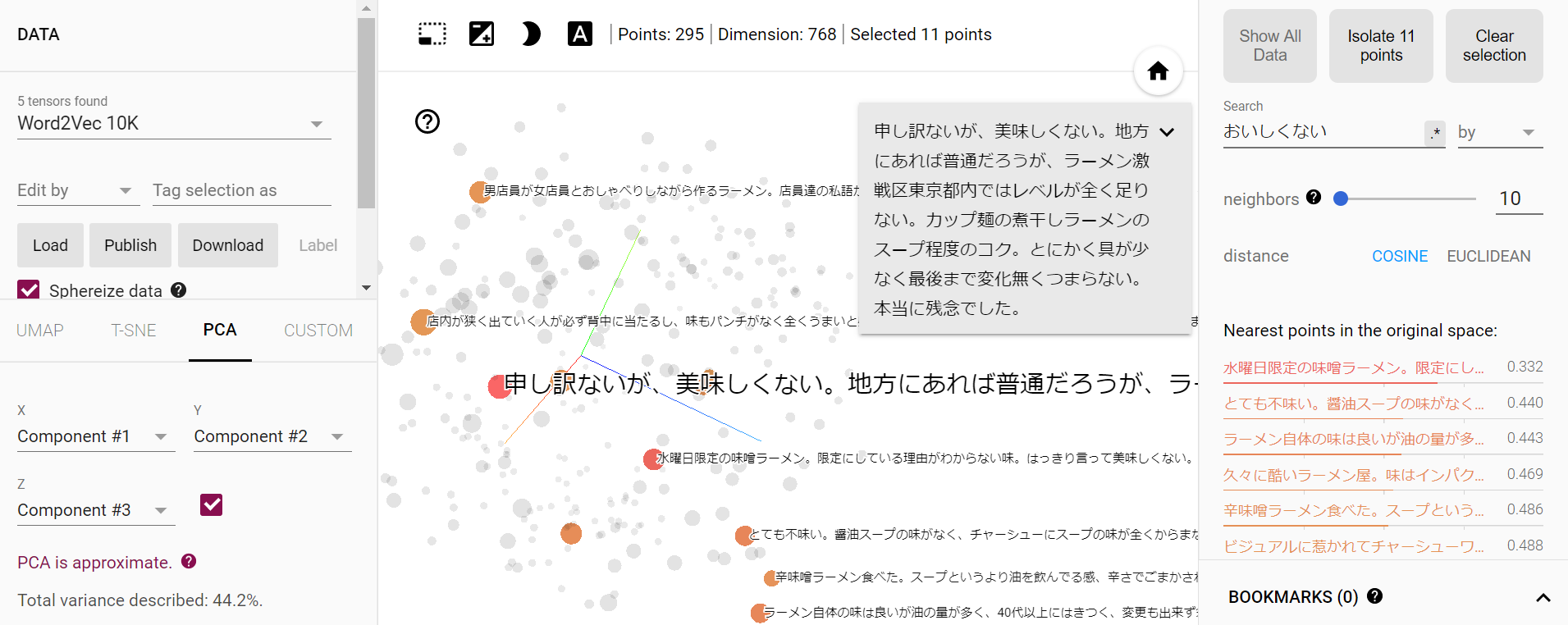
棒グラフでみた店員と味に絞って「何が悪いか」を更に深堀りしました。
6.総評
今回はBERTを用いて口コミ分析をしました。
前回の「単語」のみに着目した評価では、辞書に載っていない単語の評価が出来なかったり、文章全体の文脈を理解出来ていないという問題点がありましたが、BERTを用いることで、人間に近い判断基準をモデルに学習させることが出来、大幅に精度が向上しました。 口コミの中でネガティブな評価を選定し、グルーピングをすることで今まで発見できていなかった課題点も見つけやすくなります。
最後に、これから更に改善できる点です。
- BERTのpretrainedモデルは日本語のwikipediaを対象に事前学習していたため、口コミ特有のワードへの対応が不十分であった
- データの前処理の方法はさらに検討できる
- 対象となるターゲットを広げたときに口コミの文章や書き方にバラツキがでるため、良い精度を出すためにさらに検討が必要
これらの課題を解決するにはSNSの事前学習モデルを使ったり、様々な工夫を考えて分類器を作成することが重要となってくるでしょう。
BERTでもかなりの精度を出せると思いますが、他の新しいNLPモデルも次々と発表されているので、これらを用いてまだ企業が利活用出来ていない口コミやSNSの書き込みなどを分析することで、顧客満足度向上に繋げられると思います。
7.参考文献
BERTとは何か?Googleが誇る最先端技術の仕組みを解説!
【論文】"Attention is all you need"の解説
BERTを用いたネガポジ分類機の作成
BERTを理解しながら自分のツイートを可視化してみるハンズオン
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 実装前の課題 採用した技術と理由 実装した内容の紹介 改善したこと(抑制できたコスト) 実装前の課題 SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。 弊社では2021年2月からSRE活動を行っており、セキュリ

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数