DEVELOPER’s BLOG
技術ブログ
機械学習活用事例|エントリーシート採点サービス

機械学習を利用して「エントリーシート自己PR分析サービス」を作成しました。
エントリーシートの評価や言いたいことが伝わるか、心配ですよね。
また、企業の採用担当者は膨大な数のエントリーシートを確認することはかなりの業務量かと思います。
「エントリーシート自己PR分析サービス」では、自己PRの内容を入力すると点数や頻出単語を表示します。
[2020年2月21日追記:デモ動画]
機能追加しました!
・自己PRそのものの採点ができるようになりました。
サービスのポイント
- 文章の特徴を可視化する
- キーワードとの適合度を判定
- 文章のカテゴリーを判定
- 過去合格した自己PRと比較して採点
サービス内容を紹介します。
エントリーシート自己PRの例
私は、アルバイトの中で最も時給がアップしたという実績を持っています。
コンビニエンスストアで3年間勤務していますが、ただ働くのではなく、計画性を持って働くことができるという点が時給アップにつながりました。
具体的には、3つのポイントがあります。
お店の繁忙期をプライベートの予定と照合し、あらかじめお店が忙しい時にはいつでも残業できるようにしていたことです。一緒に働くスタッフの性格を把握しておき、一緒にシフトに入る人によって、自分の立ち位置を変えていたことです。集中力が必要となる発注作業がある日の前後には、徹夜するなどの無理なことはせず、身体的にも余裕をもっておくことです。
これら3つをすべて実行することで、他のスタッフは通常1度に30円しか昇給しないところ、前例のない100円の昇給に成功しました。
この計画性を活かし、御社でも先を見据えたスケジューリングと自己管理で、生産性の向上だけではなく、業務のクオリティをあげることにもつなげて参りたいと考えております。
(【例文多数掲載!】自己PRで計画性を伝えるときのポイントをご紹介から引用したものを少し修正)
ワードクラウド

結果を見ると「時給」や「計画」「アップ」などの頻度が高いことがわかります。
ワードクラウドとは与えられた文章を元に、出現頻度が高い単語ほど大きなサイズで表示するものです。文章内使われた単語を視覚的に捉えることで、エントリーシートなどの文章作成でも役立ちます。
キーワードと自己PRの適合度を判定
キーワード: 計画性 昇給
点数:77.7 点
キーワード:真面目 研究
点数:24.9 点
言いたいことを表現しているか採点するために文章内の頻出単語と自分で付けたキーワードを照合します。
就活において自分の強みなどを記述する際は、「計画性」や「行動力」、「部活」や「研究」などキーワードとなる言葉を意識して文章を組み立てますよね。これがどれぼど的確に出来ているかを採点するために、ワードクラウドの結果 (単語の頻度) とキーワードとなる単語との類似度を点数化しました。
例えば先程の自己PRでは、計画性やアルバイトに関するキーワードを選ぶと点数が高くなり、部活や協調性など関係のないキーワードを選ぶと低い点数になります。
単語の分散表現
キーワードとの適合度を判定するために単語の分散表現を用いました。
分散表現とは簡単に言うと単語を200次元などの高次元のベクトルで表現したものです。分散表現では似た単語同士は類似度が高く算出されます。
さらに、単語の意味も捉えることもできるため、
king - man + woman = queen
といった分散表現の足し引きをすることも可能です。
分散表現を使って、入力文章中の上位10個の頻出単語とキーワードを比べ、最大の類似度から点数を算出しています。
より適切に採点するために、類似度は文章中の出現頻度によって重み付けをしています。例えば、最も頻度が高い単語とキーワードの類似度は計算結果の値をそのまま使い、単語の頻度が1位の半分の場合は、類似度も計算結果の半分の値を使います。
キーワードも複数設定できるようにし、ユーザーの意図を汲み取りやすくしています。
自己PRを100点満点で点数化
自然言語処理において強力なBERTを使って自己PRを点数化しました。
ざっくりとしたBERTの解説については以下の記事をご参照ください。
Googleを理解する!文脈を読み取る最新の機械学習(BERT, ELMo)
自己PRを点数化する方針は良い自己PRを1とラベル付けし、悪い自己PRを0とラベル付けした後に2値分類を行います。2値分類の結果は0以上1以下の連続値で得られるので、その値に100をかけて点数化しました。
このときBERTをいちから学習させようと思うと大量のデータが必要になります。しかし、手元にあるデータ量は限られていたため事前に学習されたモデル(BERT日本語Pretrainedモデル)を利用しました。
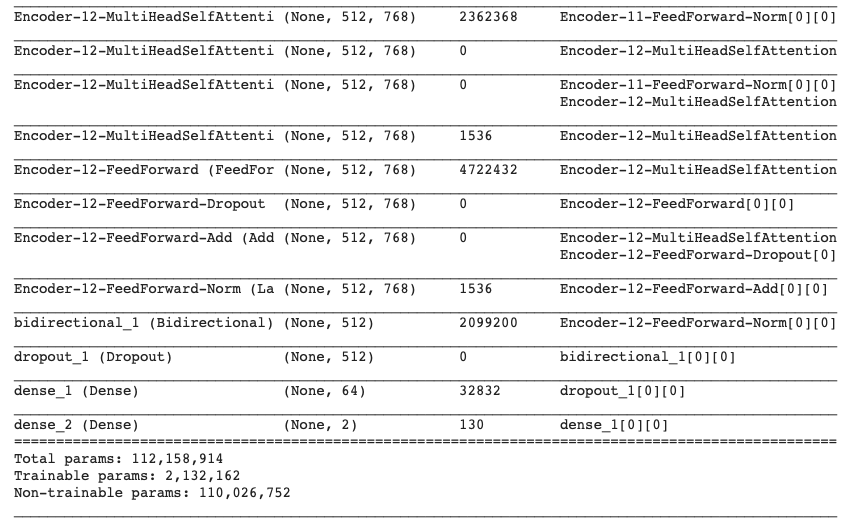
最終的なモデルの構成は以下のようになりました。
BERTのEncoder-12-FeedForward-Norm層までを取り出しBidirectional層とDropout層を加えた後、全結合層を追加し2値分類できるモデルを作成しました。
自己PRの点数化
上で例示した自己PRの点数を出してみましょう。
点数:84 点
次に悪い自己PRの例を用いて点数を出してみましょう。
エントリーシート自己PRの悪い例
私の強みは辛いことも諦めずに立ち向かう粘り強さです。わたしは大学の時にコンビニエンスストアでアルバイトをしていました。
コンビニでは担当する業務が思ったより多く、なかなかすべてを覚えることができなかったので、最初は店長やアルバイトの先輩に叱られてばかりでした。何度も辞めてしまいたいと思うことがありましたが、せっかく始めたからには諦めたくないという気持ちが強く、もっと前向きに仕事に取り組もうと考えました。
そこで、家に帰ってからもアルバイト先で学んだことをしっかり復習し、どの仕事も任せてもらえるような知識を身に付けました。また、気持ちよくお客様に接する事を心掛けて、どんなに疲れている時でも、どんなに忙しい時でも笑顔を絶やさないようにしてきました。今では店長や他のアルバイトの人にも認めてもらえるようになり、そのアルバイトを続けていくことができています。
これからもどんな仕事も諦めずに取り組む姿勢を大事にしたいです。
(自己PRの例文【悪い例:400文字、コンビニでのアルバイト①】から引用)
この自己PRはマイナスなことを書いている部分が多かったり、数字や具体的な内容が欠けておい良くない自己PRだと言えます。実際に点数を出すと
点数:52 点
冒頭の自己PRと比べて30点以上も低い点数となりました。
今回は良い自己PRと悪い自己PRの例をそれぞれ約50件ずつしか用意できなかったにも関わらず、2値分類のAccuracyでは75%以上の良い性能を出すことができました。やはり自然言語処理においてBERTは強力ですね。
まとめ
まだデータ量が少ないので精度にバラツキはありますが、大量のデータがあれば更に実用的なサービスになります。
現在はMicrosoft社などが提供するAPIを利用すれば機械学習を用いた様々なサービスを作ることが可能です。今後も多くのサービスがリリースされていくと予想されます。
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 実装前の課題 採用した技術と理由 実装した内容の紹介 改善したこと(抑制できたコスト) 実装前の課題 SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。 弊社では2021年2月からSRE活動を行っており、セキュリ

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数