DEVELOPER’s BLOG
技術ブログ
【物体検出】SSD(Single Shot MultiBox Detector)の解説

概要
先日の勉強会にてインターン生の1人が物体検出について発表してくれました。これまで物体検出は学習済みのモデルを使うことが多く、仕組みを知る機会がなかったのでとても良い機会になりました。今回の記事では発表してくれた内容をシェアしていきたいと思います。
あくまで物体検出の入門ということで理論の深堀りや実装までは扱いませんが悪しからず。
物体検出とは
ディープラーニングによる画像タスクといえば画像の分類タスクがよく挙げられます。例としては以下の犬の画像から犬種を識別するタスクなどです。
ディープラーニングで識別してみると
- コーギー: 75%
- ポメラニアン: 11%
- チワワ: 6%
- ...
のようにどの犬種か、確率としては出てくるものの画像内に犬が2匹以上いた場合は対応できなくなってしまいます。

この問題を解決するために物体検出のアルゴリズムが開発されました。物体検出の技術を使えば画像中の複数の物体の位置を特定して矩形(バウンディングボックス)で囲み、更にそれぞれの矩形について物体の識別を行うことが可能になります。
物体検出の例が以下になります。犬と猫がバウンディングボックスで囲まれ、それぞれ犬か猫か識別されていることがわかります。

物体検出モデルの歴史は深くR-CNNから始まりFast R-CNN、Faster R-CNNと精度と処理速度が改善されてきました。これらの手法は基本的に以下の動画のようにバウンディングボックスを画像内で色々と動かして物体が検出される良い場所を見つけ出そうというものでした。

物体検出についての歴史まとめより引用
その後、精度と処理速度とともにFaster R-CNNを上回るSSD(Single Shot Multibox Detector)が提案されました。
今回の勉強会ではこのSSDを解説してくれましたので、復習がてらこちらで私が解説させていただきます。
SSD (Single Shot Multibox Detector)
R-CNNではバウンディングボックスを色々と動かしてそのたびにCNNによる演算を行っていたので、1枚の画像から物体検出を行うのにかなりの処理時間がかかっていました。一方でSSDでは"Single Shot"という名前が暗示しているように、1度のCNN演算で物体の「領域候補検出」と「クラス分類」の両方を行います。これにより物体検出処理の高速化を可能にしました。
全体の構造

SSD: Single Shot MultiBox Detectorより引用
SSDのネットワークは最初のレイヤー(ベースネットワーク)に画像分類に使用されるモデルを用いています。論文ではVGG-16をベースネットワークとしています。ベースネットワークの全結合層を切り取り、上のように畳み込み層を追加したものがSSDの構造になります。
予測の際はそれぞれのレイヤーから特徴マップを抽出して物体検出を行います。具体的にはそれぞれの特徴レイヤーに3×3の畳み込みフィルタを適用してクラス特徴と位置特徴を抽出します
検出の仕組み

SSD: Single Shot MultiBox Detectorより引用
(a)が入力画像と各物体の正解ボックスです。(b)と(c)のマス目は特徴マップの位置を表しており、各位置においてデフォルトボックスと呼ばれる異なるアスペクト比の矩形を複数設定します。各位置の各デフォルトボックスについてスコア(confidence)の高いクラスを検出します。
訓練時には各クラスの誤差と、デフォルトボックスと正解ボックスの位置の誤差を元にモデルの学習を行います。
勉強会のスライドがわかりやすかったのでこちらも参考にしていただければと思います。

様々なスケールの物体を検出する仕組み
検出の仕組みを示した上の図で(b)と(c)を見ると4×4の特徴マップの方がデフォルトボックスが大きく、各特徴マップではデフォルトボックスの大きさが異なることがわかります。
SSDでは、サイズの違う畳み込み層をベースネットワークの後に追加することで様々なスケールで物体を検出することができます。

以下のように各特徴マップにおいてクラス特徴量と位置特徴量を算出します。

そして各畳み込み層で違うスケールで物体検出を行います。

これにより各層からの検出結果が得られるので次の図のように重複が生じてしまいます。

そこで次のような手順を踏んで重複を除去します。
- スコアが高いデフォルトボックスのみ抽出。
- 各クラスごとにデフォルトボックスの重なり率IoUを計算
- IoUが高い場合はスコアの低いデフォルトボックスを除去
この処理の結果、1つの物体に複数のバウンディングボックスが付与されることを回避できます。

ちなみに重なり率IoUは次のように計算されます。

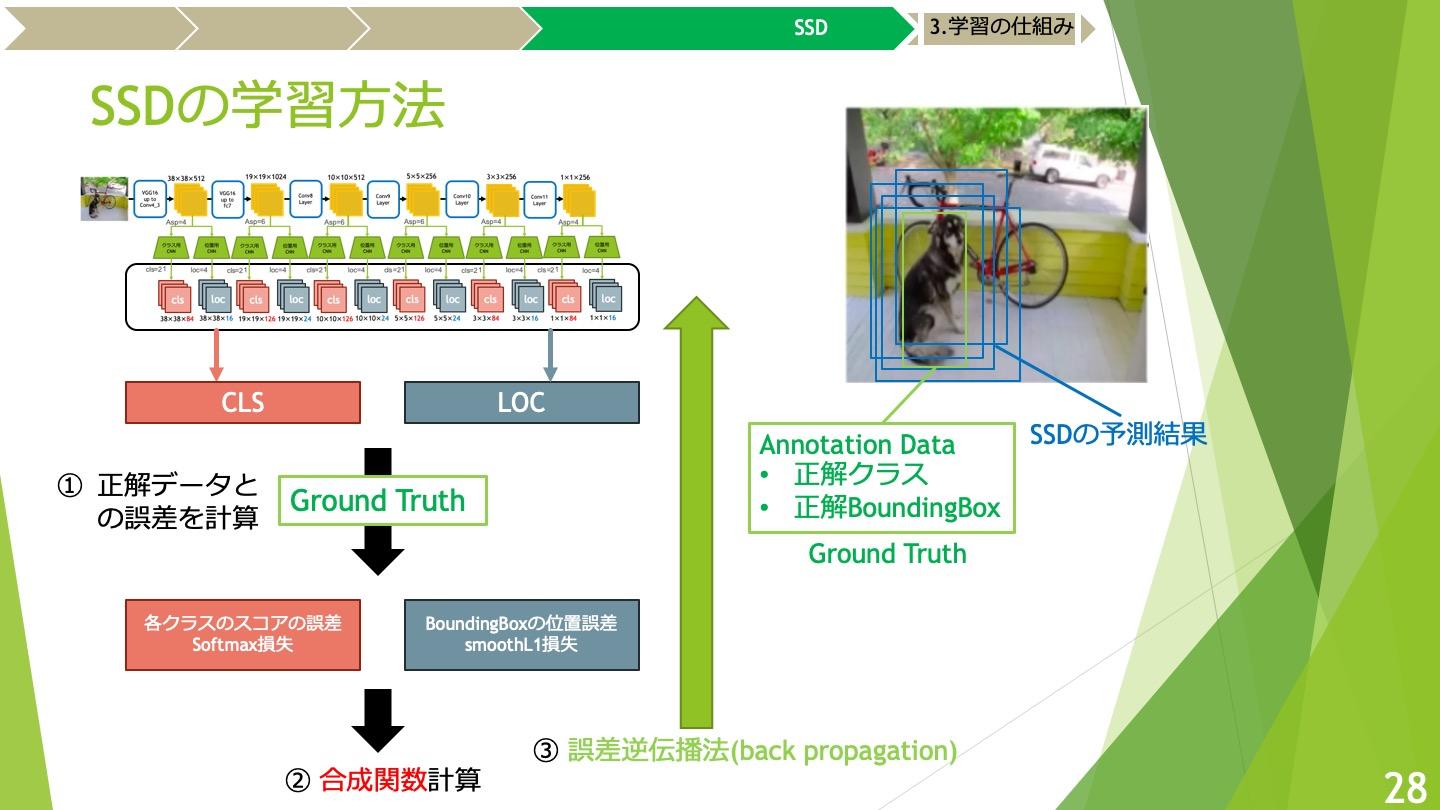
学習の仕組み
各特徴マップについて各クラスのスコアの誤差と、デフォルトボックスの位置誤差との合成関数から正解データとの誤差を計算します。クラス誤差と位置誤差それぞれの具体的な計算は論文を参照していただきたいですが、最終的な損失関数は2つの損失関数を重み付けしたものになります。
この計算結果を元に誤差逆伝播法によりモデルの重みを更新します。
まとめ
個人的に勉強会が行われた時期に物体検出の技術を使っていたので非常に勉強になりました。やはり使っている技術の中身を知ることは大切ですので、SSD以前の物体検出の手法についても勉強していきたいですね。次回はSSDと並んでよく利用されるYOLOの解説と実装をしてくれるとのことで楽しみです。
参考文献
- Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016, October). Ssd: Single shot multibox detector. In European conference on computer vision (pp. 21-37). Springer, Cham..
- その他特に言及のない画像は勉強会のスライドより引用
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

はじめに このブログは前回、ドーナツの無人レジ化に向け機械学習をどのように用いるかを紹介しました。今回は、その中で出てきたドーナツ検出器の中身について紹介します。 目次 はじめに 検出器を作るために必要なもの どのような流れで作るか 実際に作る まとめ 必要なもの ドーナツ検出器を作るために、ドーナツの画像データを訓練とテストを用意します。 今回は、「6種類のドーナツを検出し、合計金額を出す」ことが目標として、6種類のドーナツそれぞれの写真を50枚ずつ撮影

概要 物体検知の分野ではCOCOと呼ばれるデータセットを使って、検知手法の精度に関して数値的な評価が行われます。2020年1月現在、トップの正解率を示しているのが、2019年9月に発表されたCBNetを用いた手法です。 今回は物体検知に関して全くの初心者の方でも理解できるように、この論文を解説していきたいと思います。(原著論文はこちら) 目次 前提知識 Backbone CNNベースの物体検知 モデルの評価 CBNetの構造 AHLC SLC ALLC D