DEVELOPER’s BLOG
技術ブログ
リッジ(Ridge)回帰・ラッソ(Lasso)回帰の違い

線形モデル(linear model)は、実用的に広く用いられており、入力特徴量の線形関数(linear function)を用いて予測を行うものです。
まず、説明に入る前に言葉の定義から紹介します。
線形回帰
データがn個あるとした時にデータの傾向をうまく表現することができるy=w_0×x_0+....+w_n×x_n というモデルを探し出すこと
正則化
過学習を防いで汎化性を高めるための技術で、モデルに正則化項というものを加え、モデルの形が複雑になりすぎないように調整している
(モデルの係数の絶対値または二乗値が大きくなってしまうと、訓練データのモデルに適合しすぎて、テストデータのモデルの当てはまりが悪くなる過学習という現象が起こるので、過学習を避けるために正則化項をつけている)
重み
説明変数(求めたいものに作用する変数)が目的変数に与える影響度合いを表現したものです。例えば上の線形回帰モデルでいえばw1やw2など説明変数の係数が重みに当たる
コスト関数
構築したモデルがどれだけ悪いかを測定する関数
機械学習の分野ではコスト関数を最小化することがモデル構築では重要となる
モデルの比較
Ridge回帰とLasso回帰は大きな差があるわけではありません。
根本の考えは同じだが、視点を変えてみたようなものです。
まずは根本の考えについて(E:誤差関数 , λ:正則化パラメータ)
S=E+λ(Lpノルム) について考えます。
p=1の時がRidge回帰、p=2の時Lasso回帰である
ノルムの定義は以下の通りです。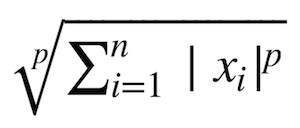
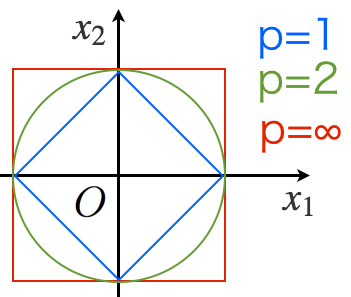
モデルの特徴をノルムの次元数から推測すると以下のことがわかります。
1.L1ノルムはパラメータの一部を完全に0にするため、モデルの推定と変数選択を同時に行うことができる
2.次元数>>データ数の状況で強力
3.L2ノルムは微分可能であり解析的に解けるが、L1ノルムは 解析的に計算出来ない
4.L1ノルムには様々な推定アルゴリズムが提案されている
以上のことから、常にどのノルムが一番優れているということはほとんどありません。
L1ノルムはパラメータが0になりやすく、正則化の影響が非常に強いことに対してL2ノルムは過学習になりやすく、正則化の影響が少し弱いです。
Ridge回帰は他と余りにもかけ離れたデータの重みを0にする事で、学習用データから削除するもの
Lasso回帰は他と余りにもかけ離れたデータの大きさに応じて0に近づけて、学習結果を滑らかにするもの
ということが分かりました。
つまりRidge回帰は訓練データに対する精度は高いですが、テストデータに対する精度は少し低くなります。
一方、Lasso回帰は訓練データに対する精度はRidge回帰に比べ低くなりますが、テストデータに対する精度はRidge回帰よりも高くなります。
実際に使う場合には、この 2 つのうちではRidge回帰をまず試してみると良いでしょう。しかし、特徴量が多く、そのうち重要なものは僅かしかないことが予測されるのであれば、Lasso が適しています。
同様に、解釈しやすいモデルが適している際は、重要な特徴量のサブセットを選ぶLasso のが理解しやすいモデルが得られます。
関連記事

はじめに 昨日まで開催されていたKaggleの2019 Data Science Bowlに参加しました。結果から言いますと、public scoreでは銅メダル圏内に位置していたにも関わらず、大きなshake downを起こし3947チーム中1193位でのフィニッシュとなりました。今回メダルを獲得できればCompetition Expertになれたので悔しい結果となりましたが、このshake downの経験を通して学ぶことは多くあったので反省点も踏まえて

〜普及に向けた課題と解決策〜に続き 私が前回作成した記事である「海洋エネルギー × 機械学習 〜普及に向けた課題と解決策〜」では、海洋エネルギー発電の長所と課題とその解決策について触れた。今回はそこで取り上げた、 課題①「電力需要量とのバランスが取りにくい」、課題③「無駄な待機運転の時間がある」への解決策 ~発電量・電力需要量予測~ ~機械学習を用いた制御~ を実装してみる。 繰り返しにはなるが、この「発電量・電力需要量予測」と「機械学習を用いた制御」

回帰分析とは 先ず回帰分析とは、あるp個の変数が与えられた時、それと相関関係のあるyの値を説明、予測することである。ここで変数xを 説明変数 、変数yを 目的変数と呼ぶ。p=1、つまり説明変数が1つの時を単回帰、またp>=2、つまり説明変数が2つ以上の時を重回帰と呼ぶ。 単回帰分析 今回はp=1と置いた 単回帰分析 について説明する。 このとき、回帰式は y=ax+b(a,bは 回帰係数 と呼ばれる)となり直線の形でyの値を近似(予測)できる。 単回帰分析

はじめに 今回はロジスティック回帰についてやっていこうと思います。まずはロジスティック回帰の概要を説明して、最後には実際にAzureでiris(アヤメ)のデータでロジスティック回帰を使っていこうと思います。 勾配降下法 ロジスティック回帰でパラメータの値を決めるときに勾配降下法を用いるので、簡単に説明をしておきます。 勾配降下法は、ある関数J(w)が最小となるwを求める際に、あるwでの傾き(勾配)を求めて、降下の方向(傾きが小さくなる方)にwを更新し