DEVELOPER’s BLOG
技術ブログ
強力な物体検出M2Detで動画の判別する(google colaboratory)
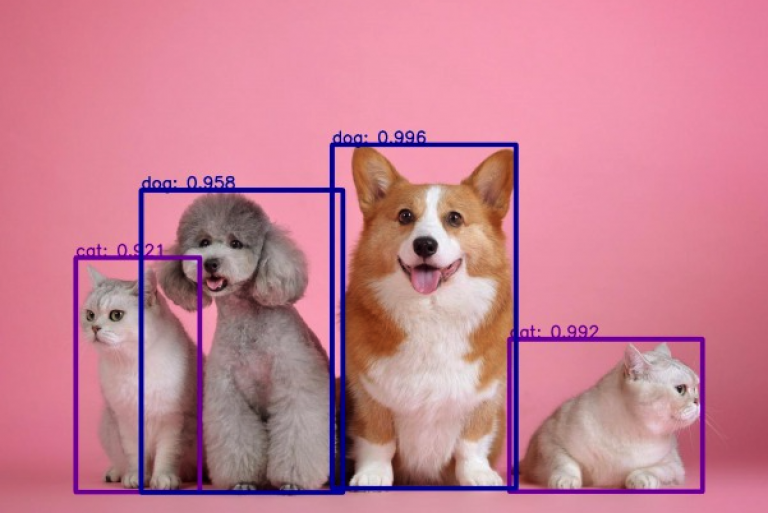
はじめに
この記事では物体検出に興味がある初学者向けに、最新技術をデモンストレーションを通して体感的に知ってもらうことを目的としています。今回紹介するのはAAAI19というカンファレンスにて精度と速度を高水準で叩き出した「M2Det」です。one-stage手法の中では最強モデル候補の一つとなっており、以下の図を見ても分かるようにYOLO,SSD,Refine-Net等と比較しても同程度の速度を保ちつつ、精度が上がっていることがわかります。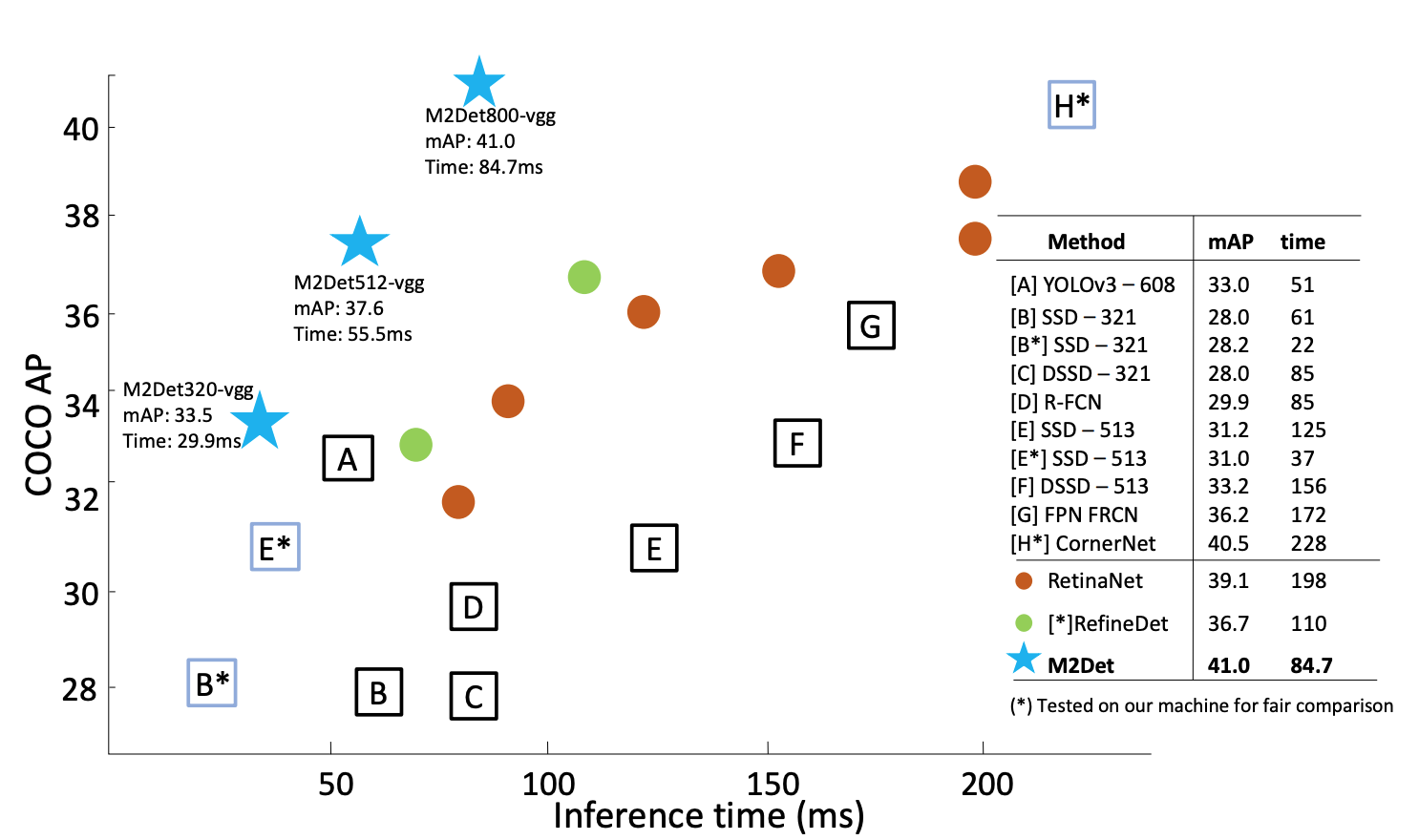
※https://arxiv.org/pdf/1811.04533.pdfより引用
物体検出デモ
それではM2Detでの物体検出をしていきたいのですがひとつ問題が
著者がgithubに公開しているソースコードはCUDAを使用する前提のため、NVIDIAのGPUが搭載していない私のPCではすぐに動かす事ができません。
そのため今回はGPUなしでも動かせる環境を提供してくれるGoogle先生の力をお借りします!
ということでGoogle Colaboratoryを使ってM2Detを動かしていきます。
例のごとくqijiezhao/M2Detの説明を参考に進めていきます。
Step1.前準備
Google Colaboratoryを開いたら先ずハードウェアのアクセラレータをGPUに設定しましょう。メニューバーの「ランタイム」→「ランタイムのタイプを変更」をクリック。「ハードウェア アクセラレータ」のプルダウンからGPUを選択して「保存」します。これで設定は完了です。
それではコードを書いていきます。必要なモジュールをインストールし、上記githubからクローンを作成します。M2Detファイルに移動したらシェルを以下のように実行します。
!pip install torch torchvision
!pip install opencv-python tqdm addict
!git clone https://github.com/qijiezhao/M2Det.git
%cd M2Det
!sh make.sh
Step2.学習済モデルをGoogle Driveからダウンロードする(引用)
次に学習済モデルを入手します(とてつもなく学習に時間がかかるので出来合いのものを使用させていただきます)。githubの説明にも書いてあるようにbackbornはVGG-16とし、指定のGoogle Driveからダウンロードしてきます。ダウンロードが簡単にできる便利なもの(nsadawi/Download-Large-File-From-Google-Drive-Using-Python)を見つけたので引用させていただきます。
#引用開始
import requests
def download_file_from_google_drive(id, destination):
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params = { 'id' : id }, stream = True)
token = get_confirm_token(response)
if token:
params = { 'id' : id, 'confirm' : token }
response = session.get(URL, params = params, stream = True)
save_response_content(response, destination)
def get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def save_response_content(response, destination):
CHUNK_SIZE = 32768
with open(destination, "wb") as f:
for chunk in response.iter_content(CHUNK_SIZE):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
#引用終了
%mkdir weights
directory = '1NM1UDdZnwHwiNDxhcP-nndaWj24m-90L'
adress = './weights/m2det512_vgg.pth'
download_file_from_google_drive(directory, adress)
これでM2Detフォルダの中に学習済モデルm2det512_vgg.pthがダウンロードできました。
Step3.判別の閾値を設定する(任意)
ここで一旦パラメータの調整を挟みます。YOLOでは判別の閾値が0.5以上の時にアノテーションすることにしていたのでM2Detでも同じ値にします。demo.pyの63行目を確認すると
def draw_detection(im, bboxes, scores, cls_inds, fps, thr=0.2):
thrの値がデフォルトで0.2になっているのでこの値を0.5に以下のように書き換えます。
!sed -i -e "63c def draw_detection(im, bboxes, scores, cls_inds, fps, thr=0.5):" demo.py
Step4.Google Driveにアップロードした動画ファイルをM2Detフォルダの指定ディレクトリにコピーする
後は判別させたい画像または動画をGoogle Driveからimgsフォルダに移動させてきましょう。なのでご自分で予めGoogle Driveに画像または動画をアップロードしておきましょう。今回は動画を使用しているので以下のようにマウントした後、任意の動画をコピーします。実行の際にオースコード(Auth code)が要求されるのでURLをクリックして表示されるコードを貼り付けます。
from google.colab import drive
drive.mount('/content/drive')
!cp /content/drive/My\ Drive/*.mp4 ./imgs #動画用

これで必要なものは全て揃いました。
Step5.デモ
ここでdemo.pyの引数について確認してみます。demo.pyの17行目から24行目を確認すると以下のように記述されています。
parser = argparse.ArgumentParser(description='M2Det Testing')
parser.add_argument('-c', '--config', default='configs/m2det320_vgg.py', type=str)
parser.add_argument('-f', '--directory', default='imgs/', help='the path to demo images')
parser.add_argument('-m', '--trained_model', default=None, type=str, help='Trained state_dict file path to open')
parser.add_argument('--video', default=False, type=bool, help='videofile mode')
parser.add_argument('--cam', default=-1, type=int, help='camera device id')
parser.add_argument('--show', action='store_true', help='Whether to display the images')
args = parser.parse_args()
parser.add_argumentの直後に記述されている引数を実行の際に記述することで様々な使い方ができるようです。別途ダウンロードしてきた学習済モデルで動画を判別させるので以下のように実行します。
!python demo.py -c=configs/m2det512_vgg.py -m=weights/m2det512_vgg.pth --video VIDEO #動画用
実行すると動画のディレクトリを指定するように出てくるのでディレクトリを指定します(Step4でimgsフォルダにコピーしたならimgs/(ファイル名))
後は各フレーム毎に物体検出をしてくれるので待ちましょう。
Step6.ファイルをダウンロードする
残念ながらmp4をchrome上で再生する術を知らないため、ローカルにダウンロードして再生することにします。以下のように2行で簡単にファイルのダウンロードができます。
from google.colab import files
files.download('imgs/<ファイル名>')
実装例
おわりに
今回M2Detを使用して動画の物体検出を行ってみました。リアルタイムの識別を検討する場合は限られた時間内に一定以上の精度を保証する信頼性がより重要となり、M2Detはこれを達成する一歩になるのでは無いかと思いました。YOLOやSSDについてもまだまだ改良されていくと予想しているので、引き続きリサーチしたいと思います。また、物体検出を利用した異常検知や店の空席率把握などに使えそうなので実装できたらまたブログ書こうと思います。
実装コード
https://colab.research.google.com/drive/1oSPhiGmZC-IeLnyoR2l-UIKIquP1i51g
その他、ドーナツを検知し、無人レジの実現に向けて検証もしており、現在、当社では技術の実用化に向けて様々な検証をしています。
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

ディープラーニングを使って、人の顔の画像を入力すると 年齢・性別・人種 を判別するモデルを作ります。 身近な機械学習では1つのデータ(画像)に対して1つの予測を出力するタスクが一般的ですが、今回は1つのデータ(画像)で複数の予測(年齢・性別・人種)を予測します。 実装方法 学習用データ まず、学習用に大量の顔画像が必要になりますが、ありがたいことに既に公開されているデータセットがあります。 UTKFace というもので、20万枚の顔画像が含まれています。ま

概要 自分に似合う色、引き立たせてくれる色を知る手法として「パーソナルカラー診断」が最近流行しています。 パーソナルカラーとは、個人の生まれ持った素材(髪、瞳、肌など)と雰囲気が合う色のことです。人によって似合う色はそれぞれ異なります。 パーソナルカラー診断では、個人を大きく2タイプ(イエローベース、ブルーベース)、さらに4タイプ(スプリング、サマー、オータム、ウィンター)に分別し、それぞれのタイプに合った色を知ることができます。 パーソナルカラーを知るメ

はじめに まずは下の動画をご覧ください。 スパイダーマン2の主役はトビー・マグワイアですが、この動画ではトム・クルーズがスパイダーマンを演じています。 これは実際にトム・クルーズが演じているのではなく、トム・クルーズの顔画像を用いて合成したもので、機械学習の技術を用いて実現できます。 機械学習は画像に何が写っているか判別したり、株価の予測に使われていましたが、今回ご紹介するGANではdeep learningの技術を用いて「人間を騙す自然なもの」を生成する

概要 DeepArtのようなアーティスティックな画像を作れるサービスをご存知でしょうか? こういったサービスではディープラーニングが使われており、コンテンツ画像とスタイル画像を元に次のような画像の画風変換を行うことができます。この記事では画風変換の基礎となるGatysらの論文「Image Style Transfer Using Convolutional Neural Networks」[1]の解説と実装を行っていきます。 引用元: Gatys et a