DEVELOPER’s BLOG
技術ブログ
pythonで画像認識を実装する -CNNによる寿司ネタ判別-

アクセルユニバースの根岸です。
突然ですが、お寿司は食べますか?日本に住んでいて食べたことない人はほとんどいないと思います。ということは何を食べているのか判断できるのは当然の教養ですよね。一方で私のようなお寿司に疎い人もいるわけで、なんとなく美味しいで終わってしまうのはもったいない。そんな時にこそ機械学習を使って解決してみましょう。
ということで、本記事ではネットからお寿司の写真を入手して機械学習(画像認識)を用いてお寿司を判別するためのモデル構築を行うまでの一連の流れを記していこうと思います。コードも合わせて載せていくのでpythonの基本文法とAPIについて少し知っておくと理解しやすいかもしれません。
目次
- 1.お寿司の画像データをネットから収集する
- 2.画像を振り分ける
- 3.画像処理と機械学習で判別する
- 終わりに
1.お寿司の画像データをネットから収集する
まずは機械学習に必要なデータの収集から始めていきます。判別対象はお寿司なのでお寿司の画像データを収集する必要があります。方法としては
- 画像検索エンジン(googleなど)から一つずつ引っ張る
- 画像共有サイト(Instagram,フォト蔵など)で公開されているWeb APIから抽出する
- kaggle等からデータセットを取得する
- 自分で作る
があります。今回の画像はWebAPIが充実している「フォト蔵」から抽出してくることにしましょう。
そもそもWebAPIとは、あるサイトが備えている機能を外部から利用できるように公開しているものです。WebAPIでは基本的にHTTP通信が利用されており、下の図のようにユーザがAPIを提供しているサーバに対して、任意のHTTPリクエストを送信することでサーバーからXMLやJSON形式のファイルが返ってくるという仕組みになっています。こうしてAPIから任意のデータを取得する行為を俗に「APIを叩く(物理的にでは有りません)」と言います。それぞれの形式の中身もフォーマットが決まっているので、ファイルのどの部分から情報を取ってくればよいか分かりやすくなっています。(下記JSONレスポンス参照)
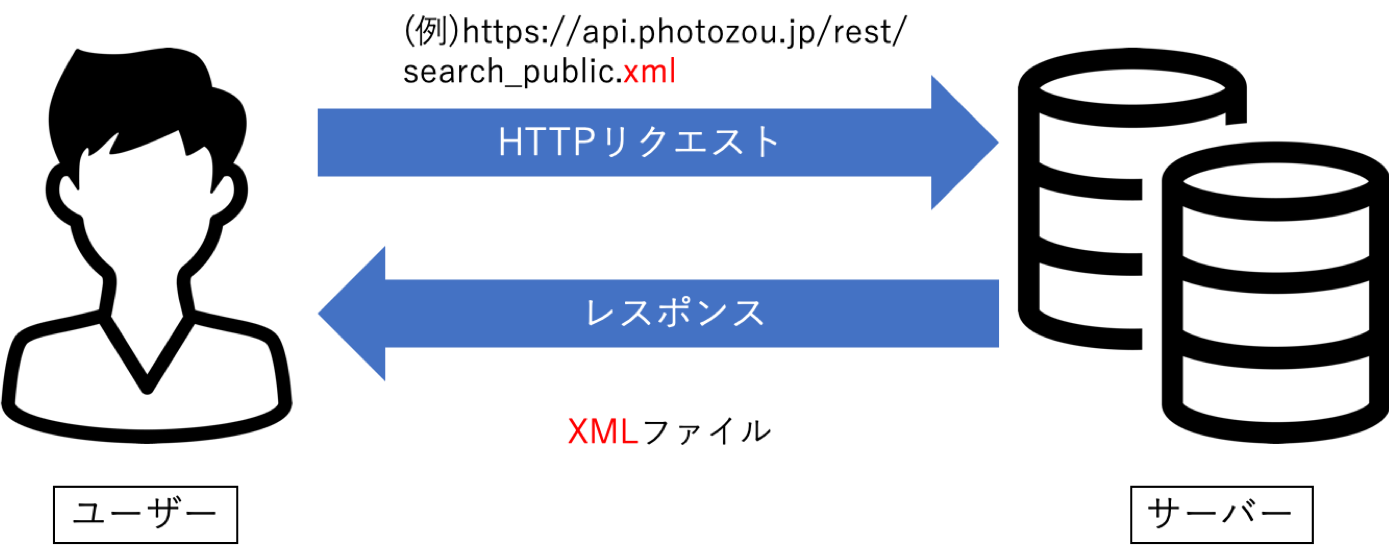
HTTPリクエストは基本的に提供元が併せて公開してくれているのでそれに従って作りましょう。
それでは早速今回利用する「フォト蔵」のWebAPIを確認していきましょう。フォト蔵の検索APIは以下のようになっています。
http://photozou.jp/basic/apimethodsearch_public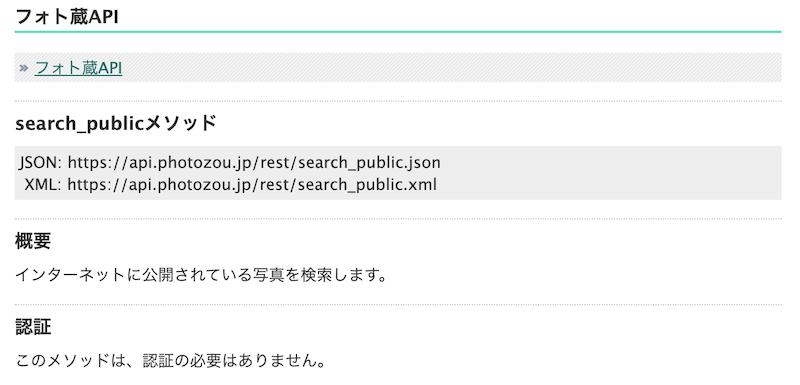
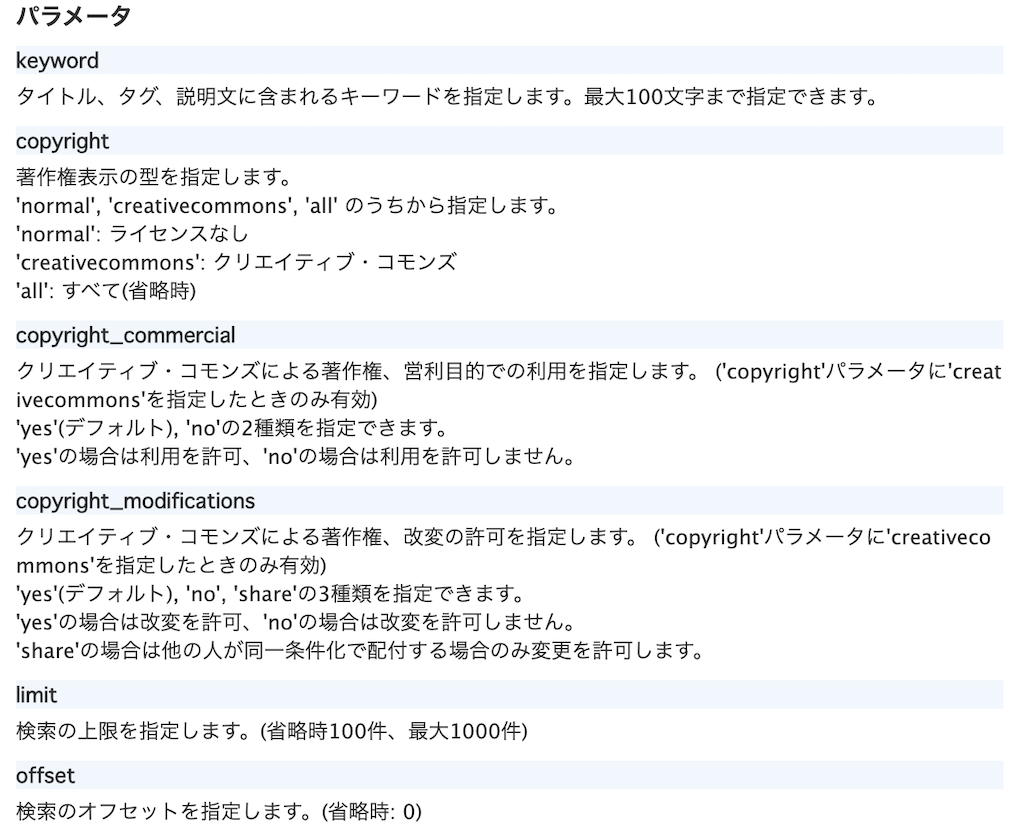
加えて以下のパラメータを指定することで、柔軟な検索が可能になっています。keywordをクエリとして設定することで任意のキーワードに沿ったデータのみ取得が可能になりそうですね。
試しにkeywordを"中トロ"としてクエリを設定してブラウザのURL欄に入力してみると以下のような表示がされます。
https://api.photozou.jp/rest/search_public.xml?keyword=中トロ
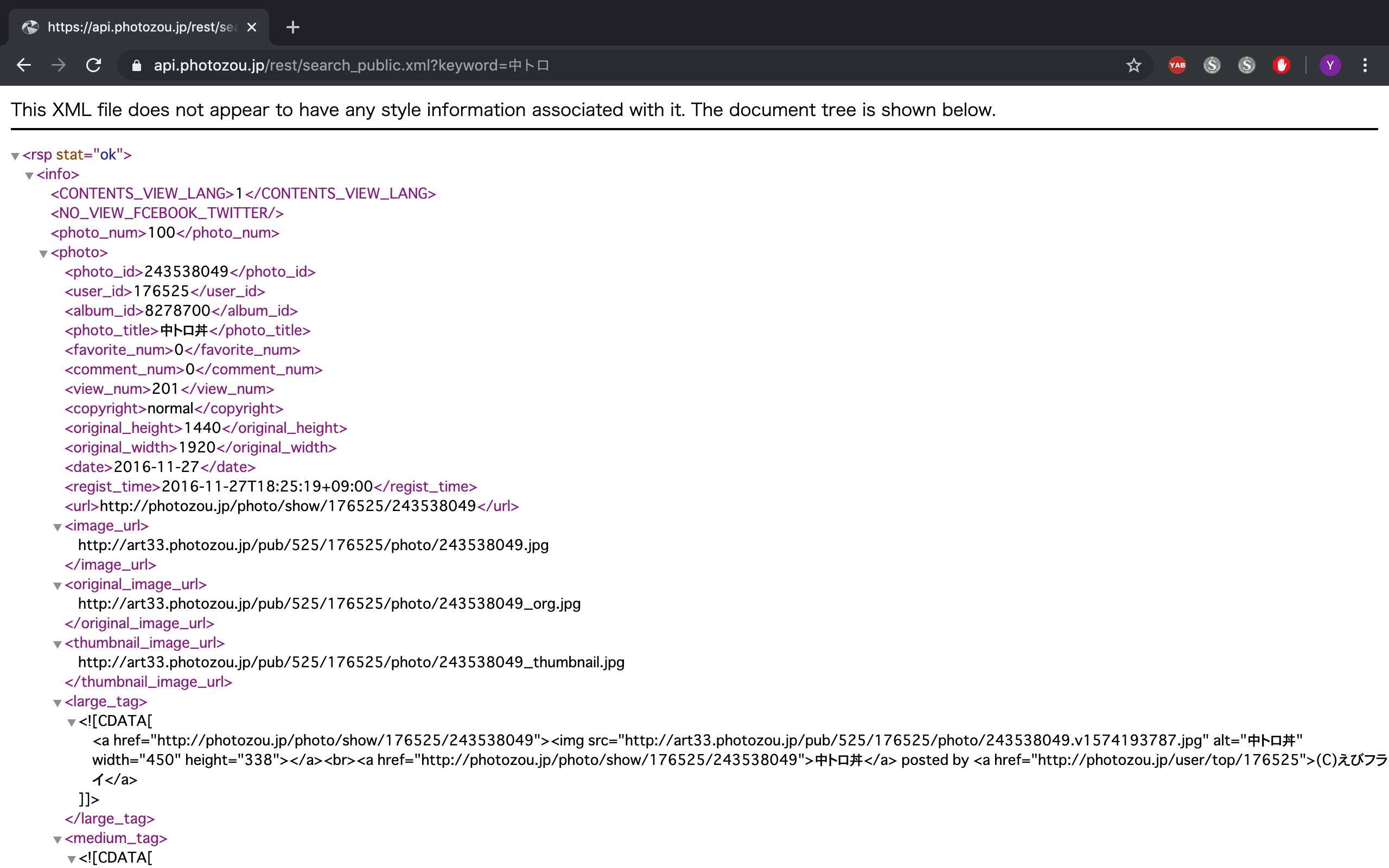
XMLファイルがブラウザ上で表示されました。
中身を詳しく見ていくとoriginal_widthやoriginal_heightがありますよね。これは元画像の解像度なので、写真の投稿者によって異なります。画像認識する上で画像サイズが違うと前処理が大変なので、サムネイルに使用している画像サイズ(120×120)の画像URLであるthumbnail_image_urlを使うことにしましょう。
このURLをファイルの中から全て抜き出してそれぞれダウンロードしてくれば欲しい画像が抜き出せるはずです。これらをすべて入手するのにurllibライブラリを使って画像を収集していきます。
それでは画像取得までの手順を確認してみましょう。
- フォト蔵のAPIを利用して(今回は)JSONファイルを取得する。
- JSONファイル内のthumbnail_image_urlから画像のURLをすべて取得する。
- 取得したURLの画像を一つずつダウンロードして保存する
JSONファイルの構成は以下のようになっています。
JSONレスポンス
{
"info": {
"photo_num": ###,
"photo": [
{
"photo_id": ###, ←画像のナンバリングとして利用
"user_id": ###,
"album_id": ###,
"photo_title": "タイトル",
"favorite_num": ###,
"comment_num": ###,
"view_num": ###,
"copyright": "normal/creativecommons",
"copyright_commercial": "yes/no"
"copyright_modifications": "yes/no/share"
"original_height": ##,
"original_width": ###,
"geo": {
"latitude": ###,
"longitude": ###
},
"date": "YYYY-MM-DD",
"regist_time": "YYYY-MM-DDThh:mm:ss+09:00",
"url": "URL",
"image_url": "URL",
"original_image_url": "URL",
"thumbnail_image_url": "URL", ←これを抜き出す
"large_tag": "<a href=\"...\">...</a>",
"medium_tag": "<a href=\"...\">...</a>"
},
...
]
}
}
それでは実際にコードを書いていきます。
まずは必要なモジュールをimportしてきます。
import urllib.request as req
import urllib.parse as parse
import os, re, time
import json
#APIのメソッドを指定
photozou_api='https://api.photozou.jp/rest/search_public.json'
sushi_dir='./image/sushi'
- urllib.request:URLの読み込み、ダウンロード
- urllib.parse:相対URLから絶対URLを取得
- os, re:ディレクトリー作成
- time:ソースコードの一時停止(リソースを逼迫させないためにAPI叩く間隔を空ける)
- json:JSONファイル読み込み
API用のHTTPリクエストとダウンロードした画像を保存する自身のディレクトリーを指定しておきます。
次に画像を検索するための関数search_photoを作っていきます。上記APIのパラメータ表記を参考にkeyword, offset,limitを指定することでAPIのクエリを組み立てて、それに応じた指定のJSONファイルをダウンロードして返す関数になっています。
この時に画像保存のためのフォルダを一緒に作っています。limitの値を変更すれば最大で引っ張ってこれる画像URLの数を調整できます。ここでは上記WebAPIのパラメータに書いてある初期値の100を使います。
def search_photo(keyword, offset=0, limit=100): #画像の検索及びJSONファイルを返す関数
#APIのクエリ組み立て
keyword_encoding=parse.quote_plus(keyword) #HTMLフォーム値の空白をプラス記号に置き換え
query="keyword={0}&offset={1}&limit={2}".format(keyword_encoding,offset,limit)
url=photozou_api+'?'+query
#クエリとキャッシュを保存しておく
if not os.path.exists(sushi_dir):
os.makedirs(sushi_dir)
sushi=sushi_dir+"/"+re.sub(r'[^a-zA-Z0-9\%\#]','_',url)
if os.path.exists(sushi):
return json.load(open(sushi, "r", encoding='utf-8'))
print(url)
req.urlretrieve(url,sushi)
time.sleep(1) #逼迫させないために間隔を空ける
return json.load(open(sushi, "r", encoding='utf-8'))
JSONファイルが取得できたらその中からthumbnail_image_urlの部分を抜き出してダウンロードしてみましょう。中にはthumbnail_image_urlを持たないものが混ざっているので、例外として排除しておきます。ファイル名はphoto_idと'_thumb'を用いてjpgで保存します。画像をダウンロードするときにもリソースの逼迫につながらないように配慮して間隔を空けるようにしておきましょう。
def download_single(info, save_dir): #画像のダウンロード
#画像保存のためのフォルダを作成
if not os.path.exists(save_dir):
os.makedirs(save_dir)
if info is None:
return
if not 'photo' in info['info']:
return
photo_list=info['info']['photo']
for photo in photo_list:
photo_title=photo['photo_title']
photo_id=photo['photo_id']
url=photo['thumbnail_image_url']
path=save_dir+'/'+str(photo_id)+'_thumb.jpg'
if os.path.exists(path):
continue
try:
print('download',photo_id,photo_title)
req.urlretrieve(url,path)
time.sleep(1)#間隔を空ける
except Exception as e:
print('ダウンロードできませんでした url=',url)
それでは上記2つを実行する関数を作って行きます。
実際に何個の画像を取得できるかわからないのでwhileとmax_photoで上限内でありったけの画像をダウンロードしてくることにします。いくつか条件分岐させていますがニッチなカテゴリーを検索するわけじゃないので、記述しなくても問題ないですが念のため。
def download_all(keyword, save_dir, max_photo=1000):
offset=0
limit=100
while True:
info=search_photo(keyword, offset=offset, limit=limit)
#情報が欠損している場合(例外処理)
if (info is None) or (not 'info' in info) or (not 'photo_num' in info['info']):
print('情報が欠損しています')
return
photo_num=info['info']['photo_num']
if photo_num==0:
print('photo_num=0,offset=',offset)
return
#画像が含まれている場合
print('download offset=', offset)
download_single(info, save_dir)
offset+=limit
if offset >= max_photo:
break
モジュールとして使わずに単独で使用する用に以下を記述しておきます。download_allのkeywordを'中トロ'にしていますがここのkeywordを変えることでそれに応じた検索画像をダウンロードしてきます。
if __name__=='__main__':
download_all('中トロ','./image/sushi')
ということでプログラムが完成した(downloader-sushi.pyで保存)のでターミナルから実行してみましょう。
$ python3 downloader-sushi.py
するとフォト蔵にある中トロの画像を最大で1000件ダウンロードします。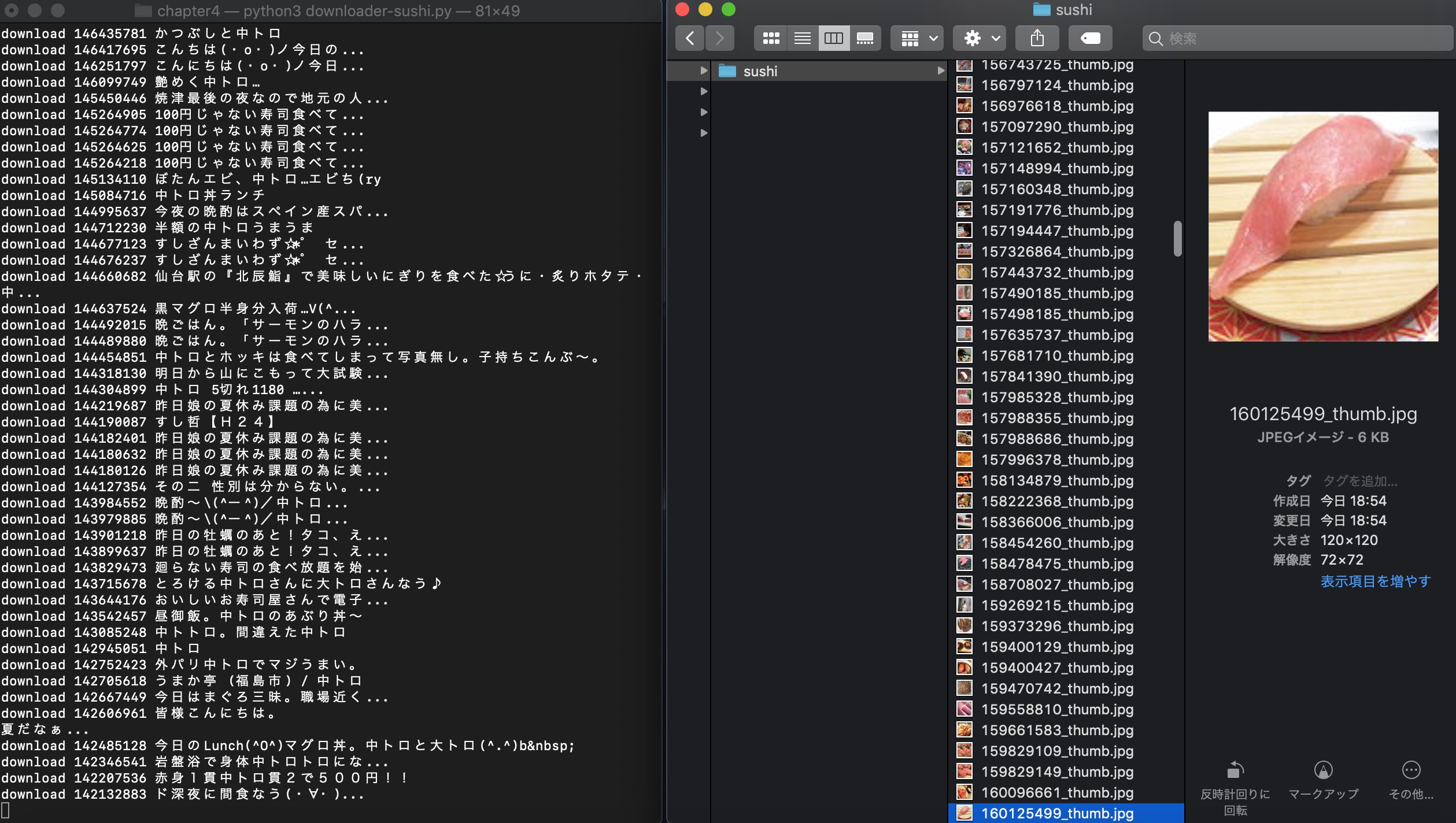
中トロ以外にも鉄火巻、こはだについて同じ処理をした後、新しいフォルダ"tyutoro","tekkamaki","kohada"を作成します。

これにて学習に必要な材料は揃いましたが・・・
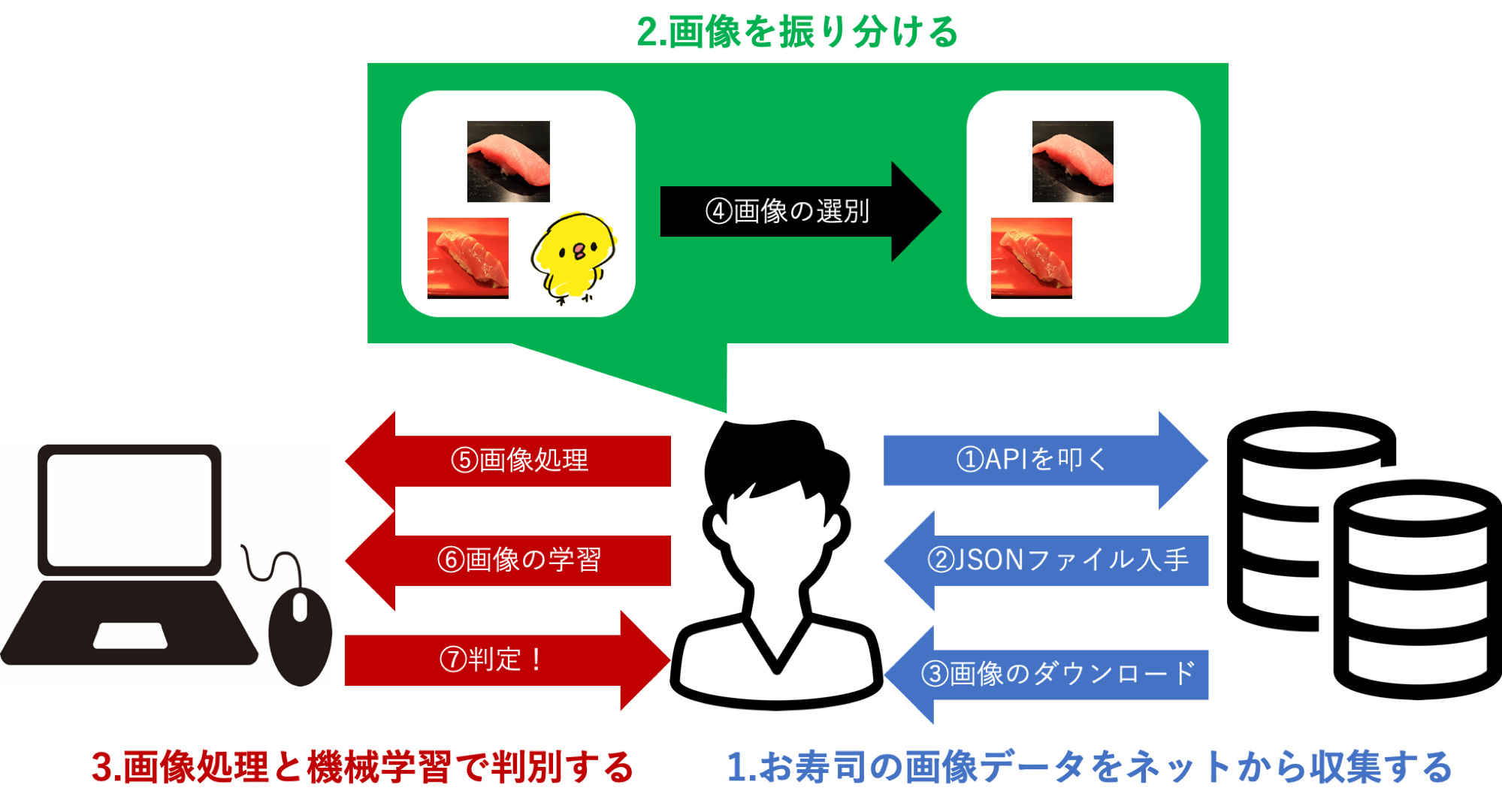
2.画像を振り分ける
ここからが泥臭い作業になります。
中トロと検索すれば全て中トロのお寿司を1貫を画面いっぱいに載せてくれている画像なら良いのですが、残念ながら中には複数の別のお寿司が写ってる、中トロが写っていない、もはや人しかいない、なんて画像がかなり混在しています。ここで手作業で学習に使えそうな画像を抽出するという泥作業が発生します(画像を部分的にアノテーションすれば使えるものもありますが、サイズの調整が大変なので割愛します)。正にデータサイエンティストの醍醐味ですね!
そうして抽出した画像数は以下の通りです。
- 中トロ 111点
- 鉄火巻 135点
- こはだ 66点
計311点
圧倒的こはだ不足です。そもそも全体的にサンプルが足りていないですが、見逃してください...。
これらの画像のファイルは"./image"上にそれぞれ作成しました。後は画像処理を行って画像認識のモデルに突っ込んでいきましょう。
3.画像処理と機械学習で判別する
ここで行うことは3点です
- 画像を数値データに変換と水増し(画像処理)
- 画像認識モデルの構築と学習
- 画像の判別
3-1 画像を数値データに変換と水増し
画像データを学習させるためには数値データへの変換が必須です。変換後はデータサイエンティスト御用達のNumpyの形式に変換させましょう。まずは必要なモジュールをimportしてきます。
from PIL import Image
import os, glob
import numpy as np
- PIL:画像処理(エンコードに利用)
- glob:画像のディレクトリパス一覧を取得
分類対象は中トロ、鉄火巻、こはだの3種類なので下記で指定しておきます。
root_dir='./image/'
categories=['tyutoro','tekkamaki','kohada']
nb_classes=len(categories)
image_size=100
次にフォルダ(カテゴリー)ごとに画像データを読み込んでRGB変換、Numpy形式への変換を行う関数を宣言していきます。
この際に画像の水増しも一緒に行っていきます。画像の角度を変えたり反転させることで画像数を増やしていきます。注意すべきことは水増ししたデータが学習データとテストデータの両方に混在してしまうとリークが発生してしまい、精度が異常に高くなってしまう現象が起きるので、水増しは学習データのみ行うようにしましょう。is_trainの真偽で水増しをするかどうかを設定しています。
#画像処理と水増しを行う
X=[]
Y=[]
def padding(cat, fname, is_train):
img=Image.open(fname)
img=img.convert("RGB") #RGB変換
img=img.resize((image_size,image_size)) #画像サイズ変更(100×100)
data=np.array(img) #numpy形式に変換
X.append(data)
Y.append(cat)
#学習データのみ水増しするので学習データではない場合は以下のfor文を実行しない
if not is_train:
return
for angle in range(-20, 20, 10):
#画像の回転
img2=img.rotate(angle)
data=np.asarray(img2)
X.append(data)
Y.append(cat)
#画像の左右反転
img3=img.transpose(Image.FLIP_LEFT_RIGHT)
data=np.asarray(img3)
X.append(data)
Y.append(cat)
#カテゴリーごとの処理
def make_train(files, is_train):
global X,Y
X=[]
Y=[]
for cat, fname in files:
padding(cat, fname, is_train)
return np.array(X), np.array(Y)
加えてディレクトリーごとに分けられているファイルを収集してallfilesに統合しています。
#ディレクトリーごとにファイルを収集する
files_all=[]
for idx, cat in enumerate(categories):
image_dir=root_dir+'/'+cat
files=glob.glob(image_dir+'/*.jpg')
for f in files:
files_all.append((idx, f))
加えてディレクトリーごとに分けられているファイルを収集してallfilesに統合しています。
最後に学習データとテストデータに分けてモデルに入れるデータが整います。
import random, math
#シャッフル
random.shuffle(files_all)
MATH=math.floor(len(files_all)*0.6)
train=files_all[0:MATH]
test=files_all[MATH:]
後はモデルを作って学習させて完成ですね。
3-2 画像認識モデルの構築と学習
それでは機械学習のフェーズに入っていきましょう。
使用するモデルはCNN(畳み込みニューラルネットワーク)です。ここではTensorFlowとKerasを組み合わせてCNNを組み立てて行きます。モデルの概要は以下のようにしています。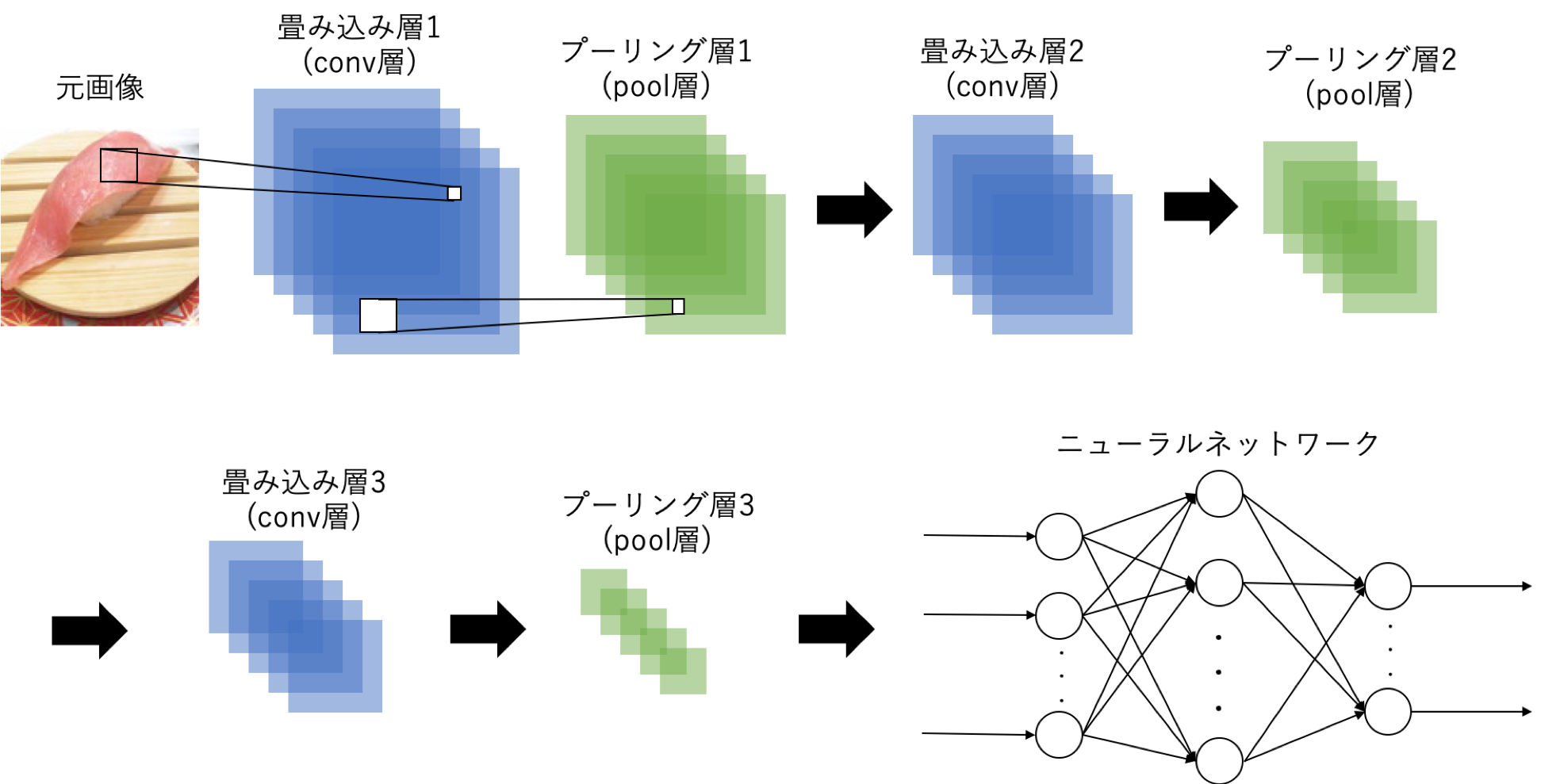
CNNの具体的な中身が以下の通り
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 100, 100, 64) 1792
_________________________________________________________________
activation_1 (Activation) (None, 100, 100, 64) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 50, 50, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 50, 50, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 50, 50, 128) 73856
_________________________________________________________________
activation_2 (Activation) (None, 50, 50, 128) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 25, 25, 128) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 25, 25, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 23, 23, 128) 147584
_________________________________________________________________
activation_3 (Activation) (None, 23, 23, 128) 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 11, 11, 128) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 11, 11, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 15488) 0
_________________________________________________________________
dense_1 (Dense) (None, 1028) 15922692
_________________________________________________________________
activation_4 (Activation) (None, 1028) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 1028) 0
_________________________________________________________________
dense_2 (Dense) (None, 3) 3087
_________________________________________________________________
activation_5 (Activation) (None, 3) 0
=================================================================
Total params: 16,149,011
Trainable params: 16,149,011
Non-trainable params: 0
_________________________________________________________________
加えてディレクトリーごとに分けられているファイルを収集してallfilesに統合しています。
それでは上記を元にコードを書いていきます。
# データをロード
def main():
X_train, y_train=make_train(train,True)
X_test, y_test=make_train(test,False)
# データを正規化する
X_train=X_train.astype("float") / 256
X_test=X_test.astype("float") / 256
y_train=np_utils.to_categorical(y_train, nb_classes)
y_test=np_utils.to_categorical(y_test, nb_classes)
# モデルを学習し評価する
model=model_train(X_train, y_train)
model_eval(model, X_test, y_test)
# モデルを構築
def build_model(in_shape):
model=Sequential()
model.add(Convolution2D(64 , 3, 3, border_mode='same',input_shape=in_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(128, 3, 3, border_mode='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(128, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1028))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
model.summary()
return model
# 学習
def model_train(X, y):
model=build_model(X.shape[1:])
model.fit(X, y, batch_size=30, nb_epoch=30)
return model
# 評価
def model_eval(model, X, y):
score=model.evaluate(X, y)
print('loss=', score[0])
print('accuracy=', score[1])
if __name__=="__main__":
main()
3-3 画像を判別する
ということでプログラムが完成した(sushi_cnn.pyで保存)のでターミナルから実行してみましょう。
$ python3 sushi_cnn.py
計算に結構な時間かかりますが、最終的に以下のような正答率が出てきました。
loss= 1.2733278312683105
accuracy= 0.8826666955947876
およそ88%といったところでしょうか。
他にも画像サイズを変えてみたり、層を変えてみたりしましたが概ね90%前後を漂う感じでした。3種類と比較的少ない種類を判定しましたが、ほどほどに上手くできてるかと思います。
終わりに
本記事では、Web APIによる画像入手に始まり、前処理(データの振り分けや選別)、CNNの学習による画像認識まで行ってみました。もちろん学習させたお寿司の種類が少なかったので実際に使えるわけではないですが、"データが集まって前処理をしっかりすれば"実用的なものになっていくのではないでしょうか。
○環境
OS:Mac Catalina 10.15.1
CPU:3.1 GHz デュアルコアIntel Core i7
RAM:16 GB 1867MHz DDR3
python:3.7.5
各種ライブラリは投稿時点で最新のものを使用しています
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

ディープラーニングを使って、人の顔の画像を入力すると 年齢・性別・人種 を判別するモデルを作ります。 身近な機械学習では1つのデータ(画像)に対して1つの予測を出力するタスクが一般的ですが、今回は1つのデータ(画像)で複数の予測(年齢・性別・人種)を予測します。 実装方法 学習用データ まず、学習用に大量の顔画像が必要になりますが、ありがたいことに既に公開されているデータセットがあります。 UTKFace というもので、20万枚の顔画像が含まれています。ま

概要 自分に似合う色、引き立たせてくれる色を知る手法として「パーソナルカラー診断」が最近流行しています。 パーソナルカラーとは、個人の生まれ持った素材(髪、瞳、肌など)と雰囲気が合う色のことです。人によって似合う色はそれぞれ異なります。 パーソナルカラー診断では、個人を大きく2タイプ(イエローベース、ブルーベース)、さらに4タイプ(スプリング、サマー、オータム、ウィンター)に分別し、それぞれのタイプに合った色を知ることができます。 パーソナルカラーを知るメ
はじめに この記事では物体検出に興味がある初学者向けに、最新技術をデモンストレーションを通して体感的に知ってもらうことを目的としています。今回紹介するのはAAAI19というカンファレンスにて精度と速度を高水準で叩き出した「M2Det」です。one-stage手法の中では最強モデル候補の一つとなっており、以下の図を見ても分かるようにYOLO,SSD,Refine-Net等と比較しても同程度の速度を保ちつつ、精度が上がっていることがわかります。 ※https:

はじめに まずは下の動画をご覧ください。 スパイダーマン2の主役はトビー・マグワイアですが、この動画ではトム・クルーズがスパイダーマンを演じています。 これは実際にトム・クルーズが演じているのではなく、トム・クルーズの顔画像を用いて合成したもので、機械学習の技術を用いて実現できます。 機械学習は画像に何が写っているか判別したり、株価の予測に使われていましたが、今回ご紹介するGANではdeep learningの技術を用いて「人間を騙す自然なもの」を生成する