DEVELOPER’s BLOG
技術ブログ
GAN:敵対生成ネットワークとは何か?画像生成アルゴリズムの紹介

はじめに
まずは下の動画をご覧ください。

スパイダーマン2の主役はトビー・マグワイアですが、この動画ではトム・クルーズがスパイダーマンを演じています。
これは実際にトム・クルーズが演じているのではなく、トム・クルーズの顔画像を用いて合成したもので、機械学習の技術を用いて実現できます。
機械学習は画像に何が写っているか判別したり、株価の予測に使われていましたが、今回ご紹介するGANではdeep learningの技術を用いて「人間を騙す自然なもの」を生成することができます。
「人間を騙す自然なもの」を作るには本物のデータがどのように生成されるのか理解しなければなりません。
例えば、猫の画像を生成するときに耳を3つ書いたりしません。なので猫の耳は2つであるということを学習しなければなりません。
GANによる成果物をもう1つ紹介します。こちらのサイトにアクセスすると人物の顔が出てきます。
ですが出てくる人物はこの世に存在せず、GANが生成した人物です。
ご覧になっていただいてわかるように不自然なところは何もありません。
1. GANとは
GANとはGenerative Adversarial Networksの略で敵対的生成ネットワークとも呼ばれ、2014年に発表されました。
特徴は2つのネットワークを戦わせることにあります。
Gをデータを生成するネットワーク(Generator)、DをデータがGから生成されたものか実際のデータかを判別するネットワーク(Discriminator)とします。
GはDを騙すような画像を生成できるように、DはGから生成されたデータを見抜けるように、競いながら学習をします。
論文では例として、Gを偽札を作る悪人、Dを偽札を見抜く警察としています。
全体のネットワーク構造は以下のようになっています。
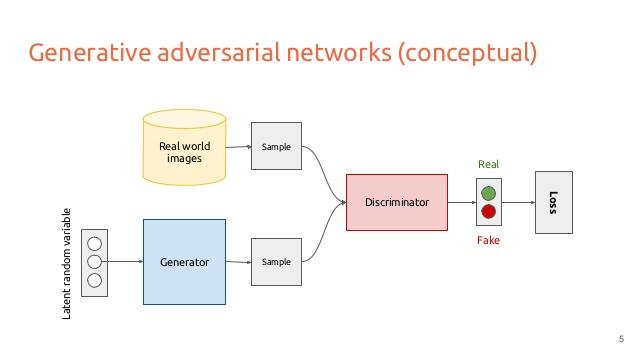
Gを図中のGenerator、Dを図中のDiscriminatorとします。
Gは何かしらの確率分布 P_z (一様分布など)から生成されたデータ z (図中 Latent random variable)から、通常のネットワークのように重みをかけて本物と同じサイズの画像を生成します。
Dは入力として画像(図中 sample)を受け取り、本物か偽物かを判定します。
\begin{eqnarray*} \min _{G} \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))] \end{eqnarray*}
2. アルゴリズム
パラメータθgとθdを更新する手順を以下に示します。
kはハイパーパラメータです。
1. 2~4をイテレーションの数だけ繰り返す
2. (2-1)~(2-4)をkの数だけ繰り返す
2-1. pzからm個のサンプル{z1,z2...zm}を取得
2-2. 実際のデータからm個のサンプル{x1,x2,...xm}を取得
2-3. θdを以下のように更新<
更新式1
3. pzに従うm個のサンプル{z1,z2...zm}を取得
4. θ_gを以下のように更新
更新式2
3. おまけ 学習の様子
zがpzに従うときG(z)がpgに従うとします。
概略は以下のようになります。
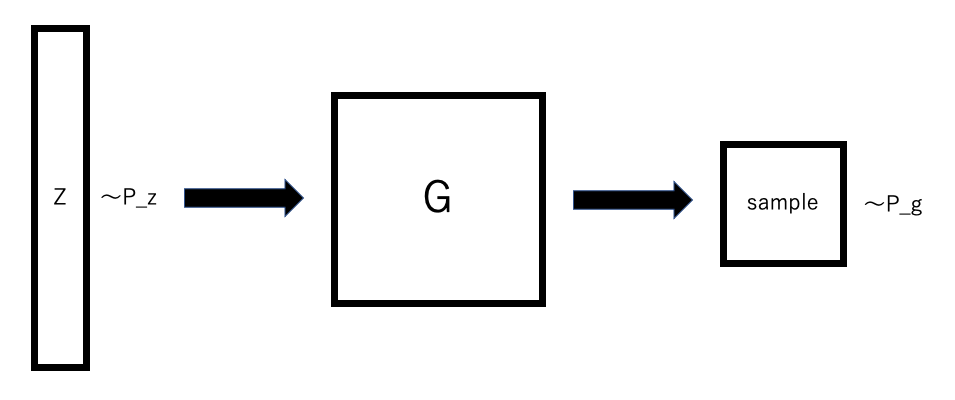
GANの目的はpg = pdataとなることです。
つまり本物のデータが生成される分布pdataとpgが等しいため、理論上は見分けがつかないことです。
これを言い換えるとD(x) = 1/2 が成り立つことだとも言えます。
これは、Dが本物のデータxをを本物だと見分ける確率が1/2で、当てずっぽうで判断していることになります。
論文にはpgがpdataに近づいていく様子が載せられています。
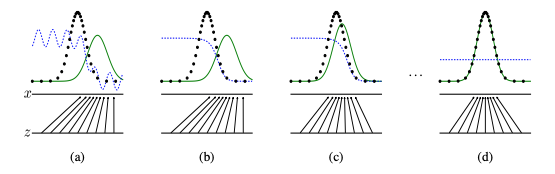
青のドット線 : D(x)
緑の線 : pg
黒のドット線 : 実際のデータxが従う確率分布pdata
a
学習前の様子です。b Dが上のアルゴリズム(2-3)の手順で更新された後です。
c Gを上のアルゴリズム4の手順で更新された後です。
bの状態と比べて、pgがpdataに近づいた事がわかります。d pg = pdataとなった様子です。
4.まとめ
GANは人を自然な画像を生成するだけでなく、最初に挙げたスパイダーマンのように2つの画像を自然に合成することもできるようです。
買おうか迷っている服を自分の体に合成して、擬似的に試着することもできます。
服の試着だけでなく、化粧品のお試しや、髪型が自分に合うのかなどを事前にわかっていると便利そうです。
今後はGANについて最新の傾向をつかめるようにしていきたいと思います。
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

ディープラーニングを使って、人の顔の画像を入力すると 年齢・性別・人種 を判別するモデルを作ります。 身近な機械学習では1つのデータ(画像)に対して1つの予測を出力するタスクが一般的ですが、今回は1つのデータ(画像)で複数の予測(年齢・性別・人種)を予測します。 実装方法 学習用データ まず、学習用に大量の顔画像が必要になりますが、ありがたいことに既に公開されているデータセットがあります。 UTKFace というもので、20万枚の顔画像が含まれています。ま

概要 自分に似合う色、引き立たせてくれる色を知る手法として「パーソナルカラー診断」が最近流行しています。 パーソナルカラーとは、個人の生まれ持った素材(髪、瞳、肌など)と雰囲気が合う色のことです。人によって似合う色はそれぞれ異なります。 パーソナルカラー診断では、個人を大きく2タイプ(イエローベース、ブルーベース)、さらに4タイプ(スプリング、サマー、オータム、ウィンター)に分別し、それぞれのタイプに合った色を知ることができます。 パーソナルカラーを知るメ
はじめに この記事では物体検出に興味がある初学者向けに、最新技術をデモンストレーションを通して体感的に知ってもらうことを目的としています。今回紹介するのはAAAI19というカンファレンスにて精度と速度を高水準で叩き出した「M2Det」です。one-stage手法の中では最強モデル候補の一つとなっており、以下の図を見ても分かるようにYOLO,SSD,Refine-Net等と比較しても同程度の速度を保ちつつ、精度が上がっていることがわかります。 ※https:

概要 DeepArtのようなアーティスティックな画像を作れるサービスをご存知でしょうか? こういったサービスではディープラーニングが使われており、コンテンツ画像とスタイル画像を元に次のような画像の画風変換を行うことができます。この記事では画風変換の基礎となるGatysらの論文「Image Style Transfer Using Convolutional Neural Networks」[1]の解説と実装を行っていきます。 引用元: Gatys et a