DEVELOPER’s BLOG
技術ブログ
Googleを理解する!文脈を読み取る最新の機械学習(BERT, ELMo)

AIの進歩が目覚ましい近年、文章の文脈まで読み取ってくれるAIがあれば嬉しいですよね。
ビジネスの場面でも、クレームとお褒めの言葉を分類したり、議事録のアジェンダと中身が合っているかなど、文脈を判断できればAIの使える場はぐんと広がります。
文脈を機械が読み取るのは難しく、研究者も今まで苦労してきました。
しかし近年、ELMoとBERTという2つのAIが現れたことで、今機械学習は目覚ましい進歩を遂げています。
多くの解説記事は専門家向けに書いてあることが多く、要点だけをまとめたり、仕組みをわかりやすく説明した記事は多くありません。
今回の記事は、そういった「よくわからないけどもっと知りたい」「本質をつかみたい」という要望に答えるべく、最新のAIをできるだけわかりやすく説明することを目的としています。
目次
- 今までのAI
- ELMoとBERT ~新星の誕生~
- 弱点と新たな新星
今までのAI
今までのAIは、単語一つ一つに対して数字を当てはめる方式をとってきました。
有名な例がWord2Vecの
「王」+「男」ー「女」=「女王」
という式です。上手に学習ができれば、このように単語ごとに数字を当てはめても他の単語との相関関係を表す事ができました。
しかし、大きな問題があります。
例えば、次の文を御覧ください。
「昨日から雨が降っている」
この文は、砂漠地域についての文章と熱帯地域の雨季についての文章では意味合いが違ってきます。
他にも、
「コストは2倍だが、利益は3倍だ。」
と
「利益は3倍だが、コストは2倍だ。」
の2つでは重点が違いますし、順番が違うだけで文章全体の意味合いが変わってきてしまいます。
つまり、単語ごとの数値だけではなく、文脈を考慮した数値を使わないとAIは文章を正確に判断できないのです。
ELMoとBERT ~新星の誕生~
そこで2018年に生まれたのがELMo、そしてその後継者のBERTです。
ELMoは文の単語を1語ずつ読み取り、単語の情報を徐々に蓄積させていく手法を使います。
以下の図を御覧ください。
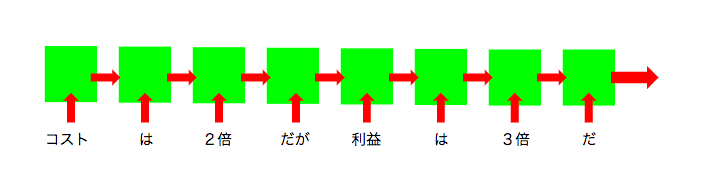
緑の箱はLSTMで、前の単語の情報を引き継いで新しい単語の情報を学習させています。(LSTMについてはこちらを参照)
つまり「利益は3倍」というフレーズが、前に「コストは2倍だが」と書いてあるという情報をふまえた上でAIに学習されることになります。
当然、後ろ側が前を参照できるだけでは、前の単語にしっかりと文脈を反映させることはできません。そこで文章の単語を逆向きにして同じような学習をさせます。

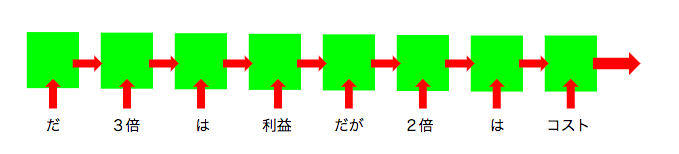 シンプルなように見えますが、ELMoはこの手法を使うことで様々な記録を塗り替え、AIの進歩に大きく貢献しました。
シンプルなように見えますが、ELMoはこの手法を使うことで様々な記録を塗り替え、AIの進歩に大きく貢献しました。
その僅か数カ月後、2018年10月に今度はGoogleがELMoを改良したBERTを発表し、時代はBERTのものになりつつあります。
BERTが改良した点は、主な計算にLSTM(上図で緑の箱)の代わりにTransformer(下図でオレンジの箱)を採用したことです。
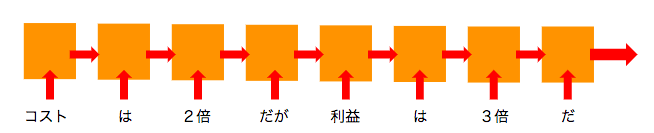
Transformerとは強そう名前ですが、論文"All you need is Attention"において注目を浴びたAIの学習機で、Attentionと呼ばれるその名の通り「注意度」を考慮に入れた非常に強力なAIのモデルとされています。(Attention モデルについてはこちらを参照)
LSTMより強力な部品を使っている分、BERTのほうがELMoよりも性能が高いというわけです。
BERTはコードが公開されているだけでなく、日本語を含めた104ヶ国語に対応しており、まさにGoogleの力を存分に発揮したAIとなっています。
文脈を読み取るとどのような課題に対応できるのでしょうか。
実際にBERTは
- MNLI:含意関係の分類
- QQP:質問内容が同じであるかを当てる
- QNLI:質問と文が与えられ、文が質問の答えになるかを当てる
- SST-2:映画のレビューに対する感情分析
- CoLA:文の文法性判断
- STS-B:2文の類似度を5段階で評価する
- MRPC:ニュースに含まれる2文の意味が等しいかを当てる
- RTE:小規模な含意関係の分類
で最高スコアを叩き出しています。
弱点と注意点
ここまで解説したように、BERTは文章の文脈を考慮に入れて文章を分類・生成できる強力なAIで、今後の応用が期待されています。
しかし弱点があるわけではなく、正しく理解しないとお金と時間の無駄になってしまいます。
今回の記事では要点のみを説明したので、細かい部分や数学は省略してあります。
また、BERTは文章をインプットし、文章を出力するAIです。なので実際の個別の課題を解く際はBERTの出力を更に分類したりするモデルが必要になってきます。
しかし言語全体の文脈感を反映させるにあたってやはり強力なAIと言えるでしょう。
また、BERTには弱点があります。
実際の学習では、文章の単語をランダムに隠し、そこを学習させることで精度を向上さています。
しかし実際の文章では文中の単語が隠されていることはなく、また複数の単語が隠されていた場合、それらの間の関係性を学習することができません。
例えば、
[単語]は2倍だが、[単語]は3倍だ。
というふうに隠されていた場合、文が正解として認識される単語の組み合わせは多数あります。なので本来の「コスト」「利益」という単語を学ぶよりも精度が下がってしまいます。
この弱点を克服したのが、今年(2019年)6月に発表されたXLNetなのですが、それはまた次回のブログ記事でご紹介致します。
以上、文脈を読み取ることができる最新のAIについて解説してきました。細かい部分は省略していますが、本質だけを突き詰めると意外とシンプルだという事がわかります。
文脈を読み取ることができれば、社会の様々な場面でAIがますます活躍することになるでしょう。
そのために複雑な数学を理解する必要はありませんが、AIの本質をしっかり把握しておくことで、変化の波に遅れることなく、AI活用の場を見出す事ができるのです。
アクセルユニバースの紹介
私達はビジョンに『社会生活を豊かにさせるサービスを提供する。』ことを掲げ、このビジョンを通して世界を笑顔にしようと機械学習・深層学習を提案しています。
例えば、現在人がおこなっている作業をシステムが代わることで、人はより生産性の高い業務に携わることができます。
当社ではみなさまの課題やお困り事を一緒に解決していきます。
下記にご興味がありましたら、問い合わせ口からご連絡ください。
- 問い合わせ業務を自動化したい
- 入力された文章を振り分けたい
- 機械学習・深層学習は他になにが出来るのか興味ある
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 機械翻訳とは 機械翻訳の手法 現在の機械翻訳の欠点 欠点が改善されると 今後の展望 機械翻訳とは 機械翻訳という言葉を理解するために2つ言葉を定義する。 系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。 系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。 この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)

概要 今回は、以前ブログで紹介したText-to-Text Transfer Transformer(T5)から派生したWT5(Why? T5)を紹介します。 Text-to-Text Transfer Transformerとは、NLP(自然言語処理)のタスクをtext-to-text(テキストを入力して、テキストを出力する)形式として考えたもので、様々なタスクでSoTA(State of the Art=最高水準)を獲得しました。こちらの記事で詳し

フェイクニュースは珍しいものではありません。 コロナウイルスの情報が凄まじい速さで拡散されていますが、その中にもフェイクニュースは混ざっています。悪意により操作された情報、過大表現された情報、ネガティブに偏って作成された情報は身近にも存在しています。 これらによって、私たちは不必要な不安を感じ、コロナ疲れ・コロナ鬱などという言葉も出現しました。 TwitterやInstagramなどのソーシャルメディアでは嘘みたいな衝撃的なニュースはさらに誇張な表現で拡散

Googleが発表したBERTは記憶にも新しく、その高度な性能はTransformerを使ったことで実現されました。 TransformerとBERTが発表される以前の自然言語処理モデルでは、時系列データを処理するRNNとその発展形であるLSTMが使われてきました。このLSTMには、構造が複雑になってしまうという欠点がありました。こうしたなか、2017年6月に発表された論文「Attention is all you need」で論じられた言語モデルTran