DEVELOPER’s BLOG
技術ブログ
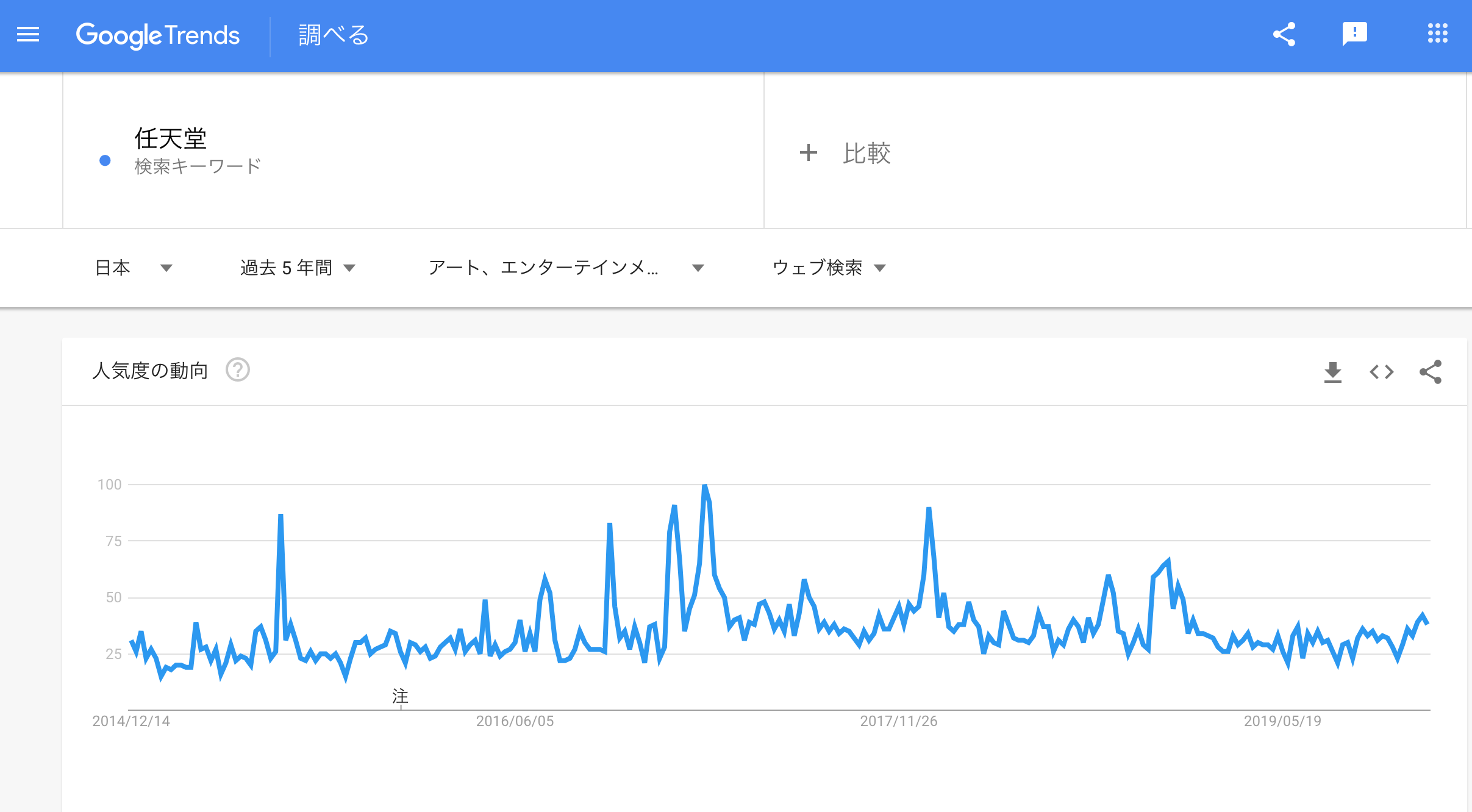
Google Trendsの結果での株価予測には「カテゴリ」が重要

はじめに
今回は世の中のトレンドを用いた株価予測をしてみたいと思います。今までに得た機械学習などの知識を実生活に用いてみたいと思っており、お金を稼ぐという意味で株価予測が候補にありました。以前、個人的にFXの値の上下予測を5分単位、1時間単位などで、テクニカル指標を用いて試してみたことがあったのですが、テクニカル指標だけでは期待した精度は出ませんでした。
ということで、世の中のトレンドも特徴量として取り入れてみようと思い立ち、トレンドに左右されそうな株価で予測してみることにしました。
よって、トレンドの影響具合を確認することをゴールとします。銘柄も絞ったほうがトレンドに対する影響が出やすいと考え、今回は任天堂を採用しました。任天堂を選んだ理由は特にないです。
結果
2015〜2019までの株価データを用い、過去6週のデータで次週の株価が上がるか下がるかの予測をし、
2015〜2018のデータで2019を予測:正解率60.4%
となりました!
取り組みの過程
以下で、取り組みの流れを説明します。
データを持ってくる
皆さんは、Google Trendsというサービスをご存知でしょうか?トレンドを定量化する方法に悩んだ末たどり着いた方法がこれです。
あるワードを入力すると、過去にGoogleでそのワードが検索された頻度(正規化済み)を示してくれます。CSVファイルとしてダウンロードもできるため、今回はこのサービスを活用しました。手軽さがこのサービスの良い点ですね。 カテゴリごとに分けることもできる(金融、ショッピングなど)ため、いくつかに分けてみました。
最大で5年間のデータが持ってこれるようですが、1週間ごとになってしまいます。データ量が減ってしまうため、ここは少し残念です...
前処理など
以下の写真のように複数のカテゴリのデータも用います。 まずライブラリをインポートし、
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
トレンドと、任天堂の株価のデータを一つにまとめます。
trend = pd.read_csv("multiTimeline_all.csv", header=1)
trend.columns = ["date", "value_all"]
trend["date"] = pd.to_datetime(trend["date"])
for cat in ["art_entertainment", "beauty", "business", "finance", "game", "law", "news", "shopping"]:
cat_trend = pd.read_csv(f"multiTimeline_{cat}.csv", header=1)
cat_trend.columns = ["date", f"value_{cat}"]
cat_trend["date"] = pd.to_datetime(cat_trend["date"])
trend = pd.merge(trend, cat_trend, on=["date"], how="left")
import pandas.tseries.offsets
trend["date"] = trend["date"] + offsets.Day(2)
import codecs
stock_price = pd.DataFrame()
for i in range(5):
year = i + 2015
with codecs.open(f"7974_{year}.csv", "r", "Shift-JIS", "ignore") as file:
stock_price_each_year = pd.read_table(file, delimiter=",", header=1)
stock_price = pd.concat([stock_price, stock_price_each_year], axis=0)
stock_price = stock_price[["日付", "出来高" , "終値調整値"]]
stock_price.columns = ["date", "volume", "close_price"]
stock_price["date"] = pd.to_datetime(stock_price["date"])
matrix = pd.merge(trend, stock_price, on=["date"], how="left")
matrix = matrix.dropna(subset=["volume"])
トレンドのデータは毎週日曜日の日付になっていたので、2日遅らせて火曜日としました(月曜日は休日で株価のデータがない場合が多いため)。 ここから1〜6週間前のトレンドを特徴量として作ります。
new_fe = []
for i in range(6):
for col in ['value_all', 'value_art_entertainment', 'value_beauty',
'value_business', 'value_finance', 'value_game', 'value_law',
'value_news', 'value_shopping', 'volume', 'close_price']:
matrix[f"{col}_{i+1}_weeks_ago"] = matrix[f"{col}"].shift(i+1)
new_fe.append(f"{col}_{i+1}_weeks_ago")
matrix = matrix.drop([3, 4, 5, 6, 7])
そして、このnew_feの特徴量を予測に使います。
matrix["close_price_diff"] = matrix["close_price"] - matrix["close_price"].shift() matrix["binary"] = matrix["close_price_diff"].apply(lambda x: 1 if x >= 0 else 0)
目的変数も作りました。
ちなみに、目的変数と特徴量(使わないもの含む)の相関の上位です。

モデルのトレーニングと予測
モデルはLGBMを用いました。時系列データであるためLSTMも使ってみたかったのですが、データ量が少ないため断念しました。今回のLGBMのmetricはAUCです。
import lightgbm as lgb
from sklearn.metrics import accuracy_score
params = {'objective': 'binary',
'max_depth': -1,
'learning_rate': 0.01,
"boosting_type": "gbdt",
"bagging_seed": 44,
"metric": "auc",
"verbosity": -1,
"random_state": 17
}
X = matrix[new_fe]
y = matrix["binary"]
columns = X.columns
y_oof = np.zeros(X.shape[0])
score = 0
feature_importances = pd.DataFrame()
feature_importances['feature'] = columns
X_train, X_valid = X[:X.shape[0]//5*4], X[X.shape[0]//5*4:]
y_train, y_valid = y[:X.shape[0]//5*4], y[X.shape[0]//5*4:]
dtrain = lgb.Dataset(X_train, label=y_train)
dvalid = lgb.Dataset(X_valid, label=y_valid)
clf = lgb.train(params, dtrain, 3000, valid_sets = [dtrain, dvalid], verbose_eval=100, early_stopping_rounds=400)
feature_importances[f'fold_{fold_n + 1}'] = clf.feature_importance(importance_type="gain")
def my_binary(x):
if x >= 0:
return 1
else:
return 0
y_pred_valid = clf.predict(X_valid)
y_oof[valid_index] = list(map(my_binary, y_pred_valid))
print(f"AC: {(accuracy_score(y_valid, list(map(my_binary, y_pred_valid))))}")
del X_train, X_valid, y_train, y_valid
AUCと正解率は以下です。

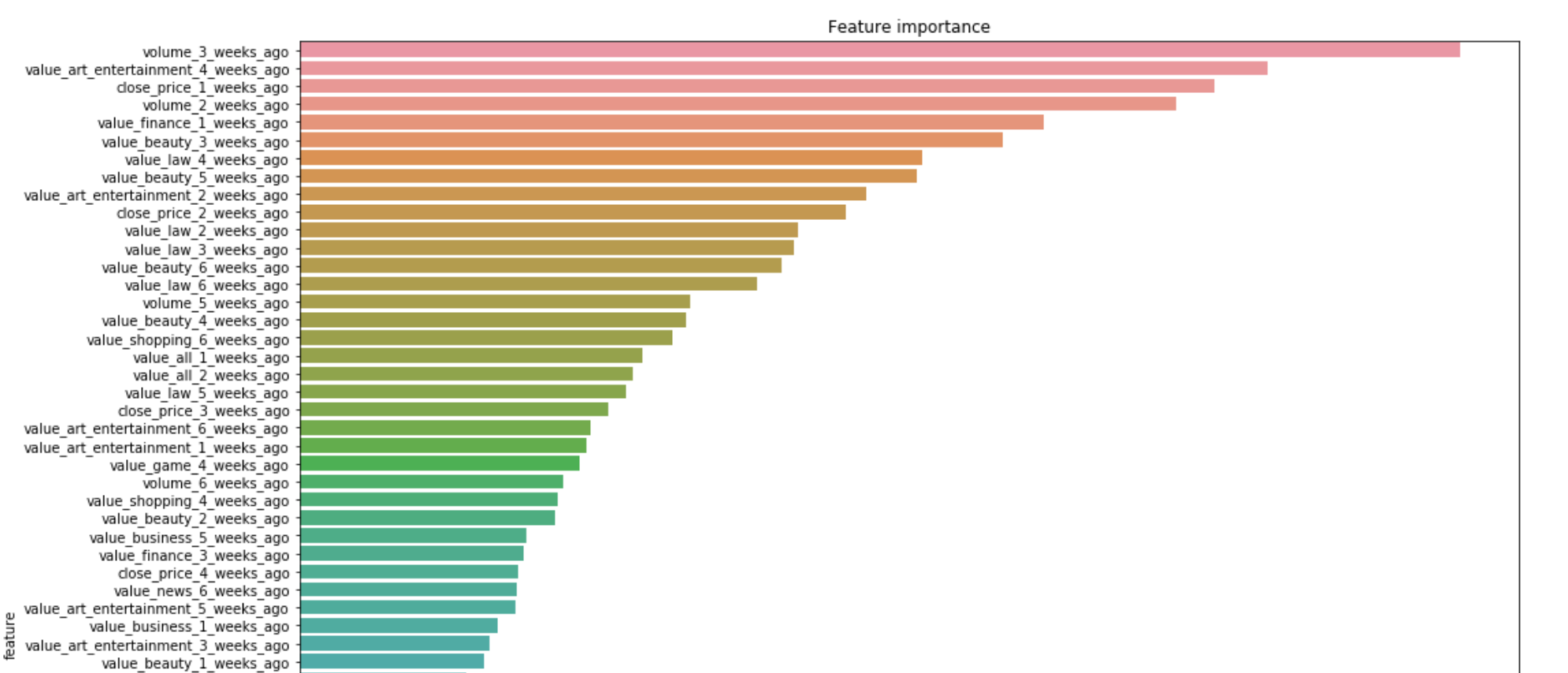
特徴量重要度の上位は以下のようになりました。
また、この予測した通りに取引した場合の結果も計算しました。
def my_profit(diff, ans, pred):
if ans == pred:
return abs(diff)
else:
return abs(diff) * -1
sum(matrix.iloc[int(X.shape[0]/20):, :][["close_price_diff", "binary", "pred"]].apply(lambda x: my_profit(x[0], x[1], x[2]), axis=1).values)
結果は以下です。

つまり、毎回100株の取引をすると30万円の儲けです!これはなかなか嬉しいですね
結果の考察
データが240と少ないため、断定はできませんが、トレンドと株価には何かしらの関係があるのではないかと考えられます。
特徴量重要度をみると、「取引量」のほか、「アート、エンターテイメント」、「金融」、「美容、フィットネス」などのカテゴリのトレンドが重要であったことがわかります。また、6週間前の値が特徴量として効いていたりもするようで、非常に興味深いです。少し追加で調べていきます。
まず、Google Trendsから得られるのはあくまで検索数の上下であり、それは任天堂のプラスなトレンドもマイナスなトレンドも同時に反映しています。にも関わらず、なぜ上下を60%で予測できたのかについて考えました。僕はこれについて、カテゴリごとにトレンドを分けた特徴量を加えたからではないかという考えに至りました。上に記載した特徴量重要度をみてみると、value_all、すなわち全体の検索数の特徴量があまり予測に寄与していないことがわかります。
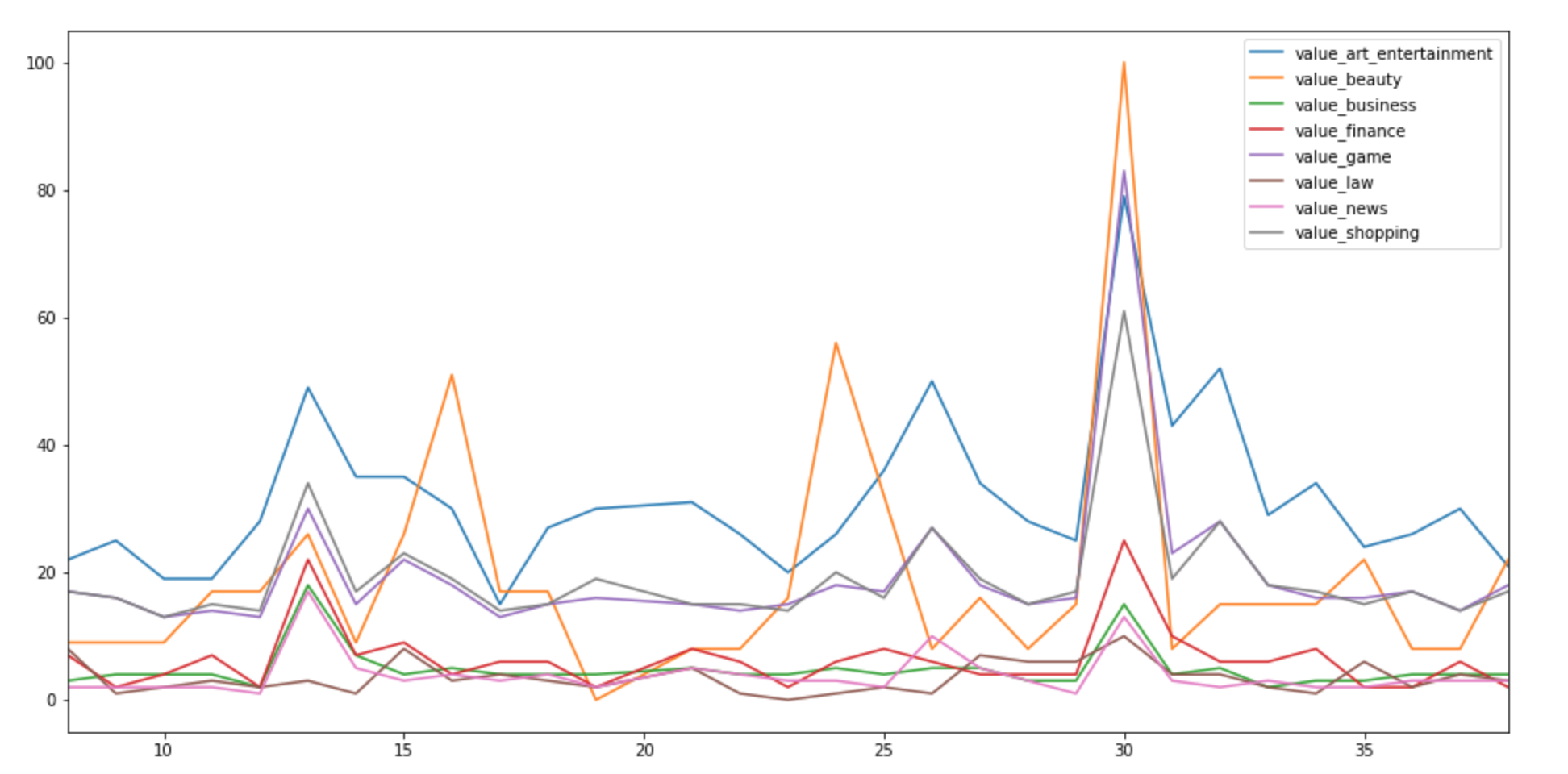
これはカテゴリごとの時間の変化での検索数(正規化済み)の上下の1部のグラフですが、カテゴリによって動きが大きく違います。
つまり、任天堂にとってプラスなトレンドを表すカテゴリ、逆にマイナスを表すカテゴリがあるのではないでしょうか。例えば、アート、エンターテイメントの検索はマイナスよりプラスな意味での検索をする人が多く、法律の検索は告訴した、告訴されたなどのマイナスな検索が多そうです。
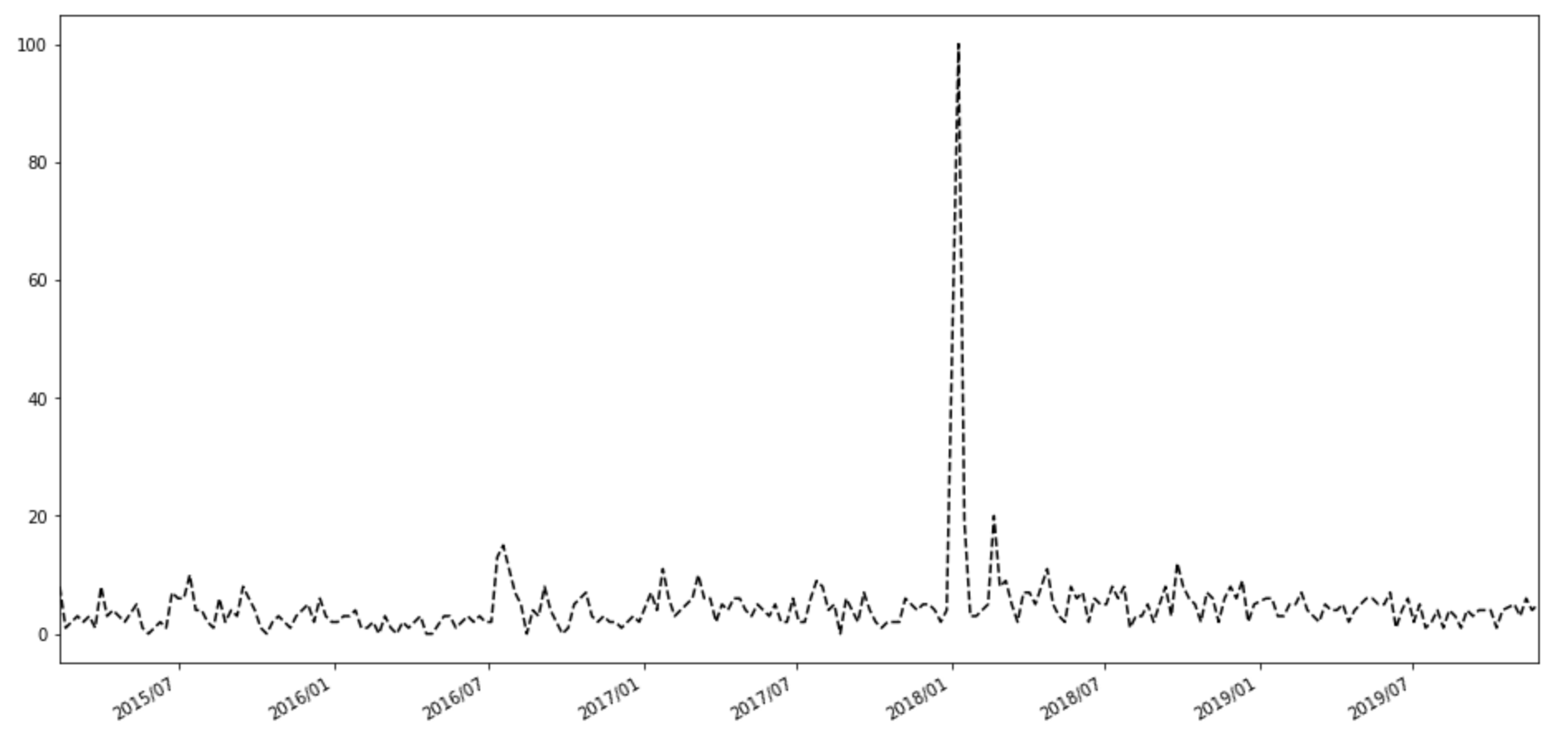
上の写真は法律カテゴリの検索数ですが、2018年1月付近に急増加しています。1月10日はコロプラが、12月22日付で特許権侵害に関する訴訟を任天堂より提起され、1月9日に訴状内容を確認したことを発表した日です。
まとめ
トレンドの特徴量だけでここまでの精度が出るとは思っていませんでした。トレンドの測り方はGoogle Trends 以外にもツイッターなどのSNSがあるため、これらを増やしていくことで長期間での株価の予測は可能なのではないでしょうか。株価は様々なものに影響を受けるものであるため、どんな特徴量を足していくか?が重要だと思われます。
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

ご挨拶 AWS全冠エンジニアの小澤です。 今年の目標はテニスで初中級の草トーナメントに優勝することです。よろしくお願いいたします。 本記事の目的 本記事では、生成AIでVOC分析を行うことで得られた知見を共有したいと思います。 昨今、生成AIの登場など機械学習の進歩は目覚ましいものがあります。一方、足元では自社データの利活用が進まず、世の中のトレンドと乖離していくことに課題感を持たれている方も多いかと思います。また、ガートナーの調査(2024年1月)による

なぜ機械学習で双対問題を学ぶのか 結果から述べるのであれば、SVM(サポートベクトルマシーン)の原理で双対問題を使いたいからです。 これから実際どのように双対問題が使われているのか、また、双対問題の簡単な具体例を交えて説明していきたいと思います。 まずSVMについて簡単に説明したいと思います。 予測には過去のデータを使います。 しかし、外れ値のような余計なデータまで使ってしまうと、予測精度が下がるかもしれません。 そこで「本当に予測に必要となる一部のデータ

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数

目次 機械翻訳とは 機械翻訳の手法 現在の機械翻訳の欠点 欠点が改善されると 今後の展望 機械翻訳とは 機械翻訳という言葉を理解するために2つ言葉を定義する。 系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。 系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。 この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)