DEVELOPER’s BLOG
技術ブログ
機械学習とは?学習の種類や予測プロセスの紹介
もくじ
機械学習の概要
機械学習とは与えられたデータからデータに潜む規則性を自動的に発見し、データの分類や未知のデータの予測をコンピュータの計算手法を利用して行うことである。データから予測を行うとき、扱うデータによっては膨大な規則を用いたり、人力では見つけることの難しい規則が存在したりするので、人間だけでは予測が困難な場合があるが、それをコンピュータの計算に落とし込むことで予測が容易になる。機械学習を用いてデータの予測を可能にすることよって、以下の例のように私達の生活の中で大きな役割を果たしているのである。
- 工場の製造ラインでの不良品検出
- 株価の予測
- ECサイトでのレコメンド機能
人工知能と機械学習の違い
機械学習と並べて話題に出されるものとして、人工知能が挙げられる。人工知能とは人間が行っている言語理解や推論、問題解決などの知的な活動をコンピュータに行わせる技術である。人工知能と機械学習は、一見すると同じようなものに聞こえる。しかし、機械学習はある特定の分野においてデータに基づいて予測の結論を下すため、人工知能における人間の知的な活動のすべてを網羅しているわけではない。つまり、人工知能の一つのトピックとして機械学習が位置づけられる。 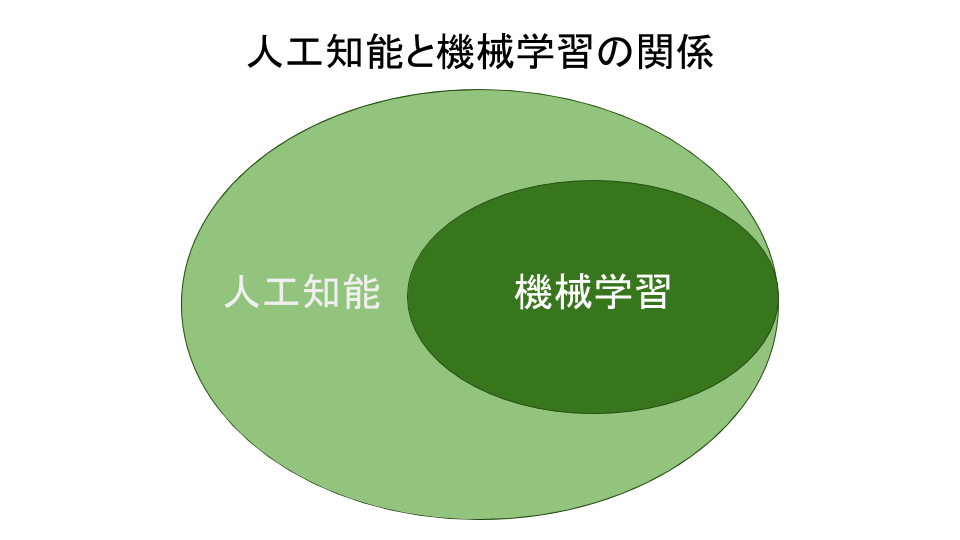
機械学習の種類
機械学習は主に以下の3種類に大別される。
-
教師あり学習
教師あり学習とは予測するものの正解が分かっているデータに対して未知のデータの予測をする機械学習である。教師あり学習の中にはデータをカテゴリ別に分ける決定境界を引く分類と、カテゴリではなく、入力のデータからどのような値をとるか予測する回帰モデルを求める回帰の2種類の方法が存在する。工場の生産ラインで、部品の形状などから不良品かどうか判別するのは分類であり、今までの株価の変動から将来の株価を予測するのは回帰だと言える。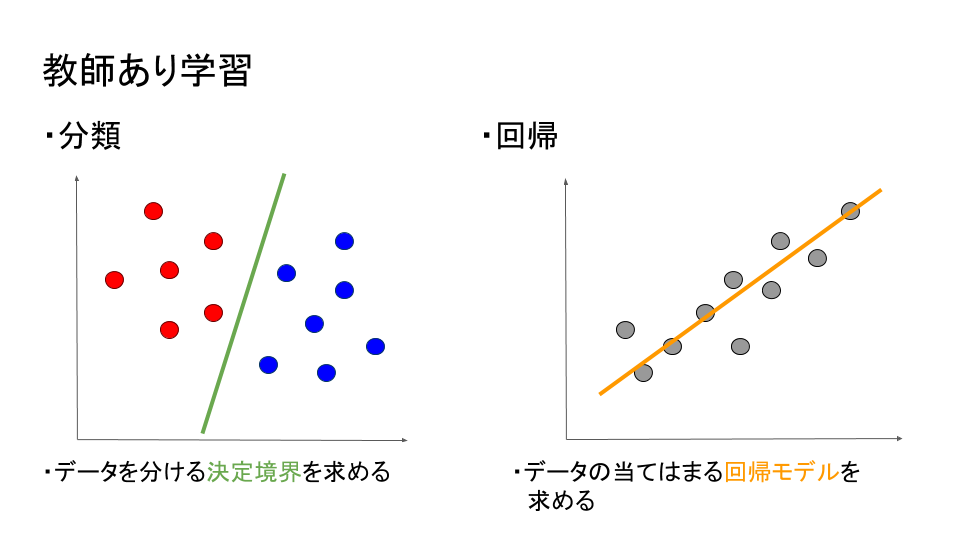
-
教師なし学習
教師あり学習に対して、教師なし学習は正解の無いデータから情報を見つけることを目的とする機械学習である。教師なし学習はデータのみからグループ分け(クラスタリングなど)やデータの次元縮減(例えば、空間上の3次元のデータを平面上の2次元のデータとして写すなど)をすることで、データの隠れた構造を見つけ出す手法と言える。ECサイトでの顧客の購買行動から、一緒に買われているものを見つけ出して提案するレコメンドは教師なし学習である。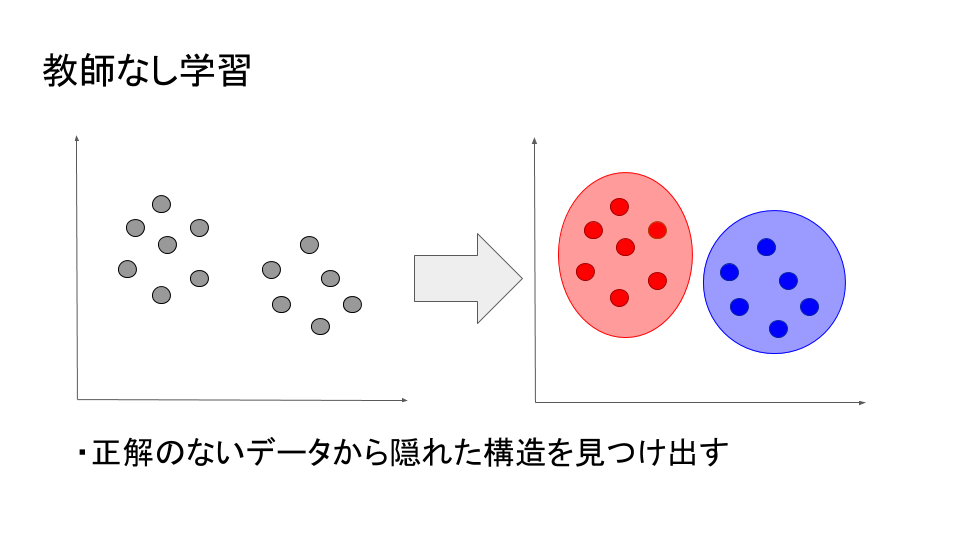
-
強化学習
強化学習はエージェントと呼ばれるシステムと環境とがやり取りをすることで行われる機械学習である。エージェントは何かしらの行動をすることによって環境から報酬を得ることができ、この報酬が最大になるように自身のシステムを改善していく 。ラベルや値などの決まった正解は無いが、エージェントの行動の出来を数値化して学習を進めていく。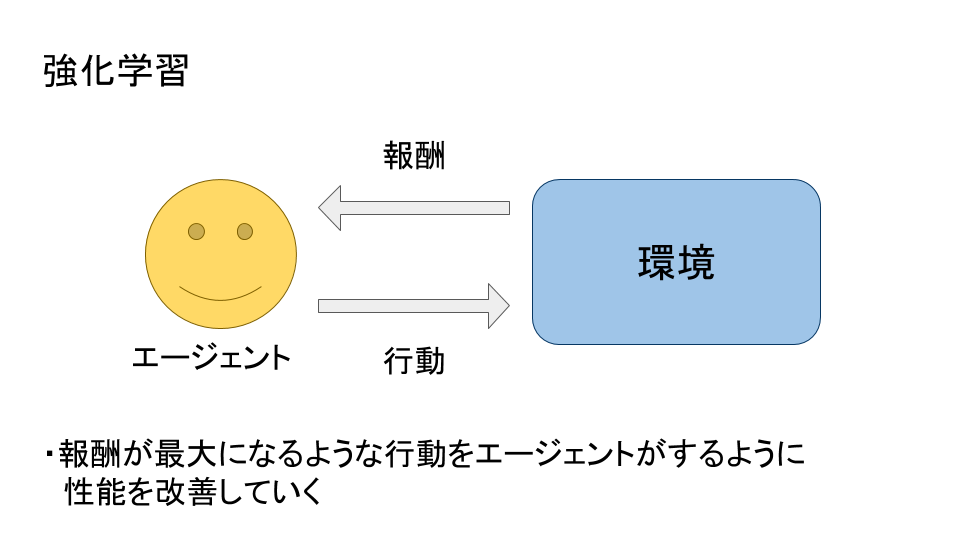
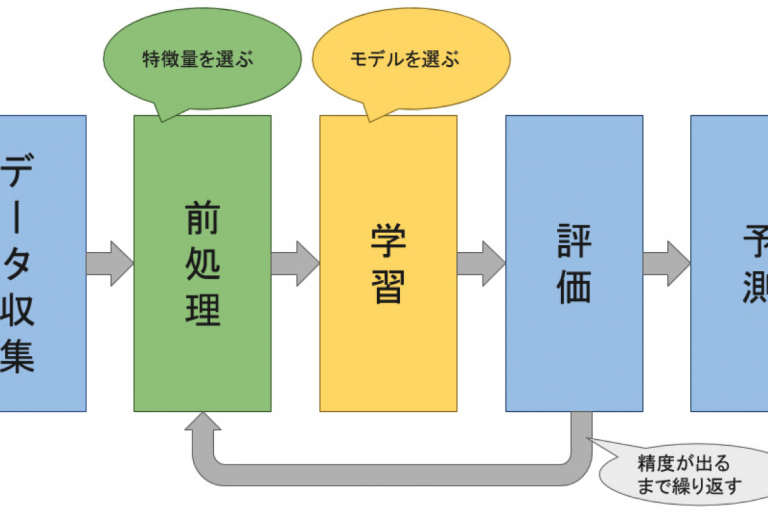
機械学習のプロセス
ここで、機械学習がどのようなプロセスで予測まで行われるのか説明する。
- データの収集
まず必要なのはデータの収集である。当然、データから何かを予測するためにはそのためのデータを集計しなければならない。 - データの前処理
ほとんどの場合、実際に学習を始める前に、データに対して前処理を行っておく。機械学習を行う上では予測に必要な情報だけを抽出しておくことで、この後の学習の段階でコンピュータが行う計算を簡潔にすることができる。例えば用いるデータが画像ならば、画像のサイズの拡大や縮小、回転などすることで前処理を行う。 機械学習では予測したい情報に対して、それを特徴づける他の情報を特徴量と呼ぶ。そのため、前処理のことを特徴抽出と呼ぶこともある。 - 学習
前処理によって抽出した特徴量を用いて学習を行う。予測したい情報に合わせて予測に用いる計算手法を選び、その後データを入力して結果を出力する規則算出する。この規則を作るために用いる計算手法やルールをモデルと呼び、ここで用いられるデータは訓練データと呼ばれる。この学習のモデルをどう構築するかによって予測の精度が大きく変わってくる。 - 精度の評価
学習したモデルに対してどのぐらいの精度で予測が成功しているのか評価する必要がある。そのため先程学習で使った訓練データとは別に、テストデータを用いて精度を測定する。これによって、学習に用いてないデータに対しても良い精度が出ているか(汎化という)を確認する。精度が悪ければ、もう一度モデルの構築や場合によってはデータの収集に戻って学習を繰り返す。 - 未知のデータに対して予測
良い精度のモデルが得られたのならば、それを用いて新たに得られる未知のデータに対して予測が行うことができる。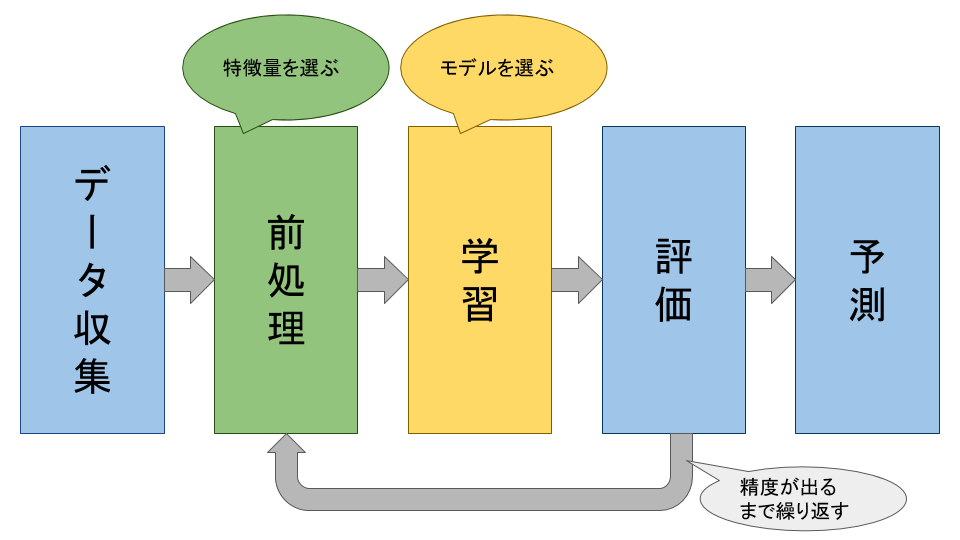
機械学習のこれからの発展
冒頭で示した例から分かる通り、機械学習は今もなお研究され続けられている分野であり、また今後も発展していく分野であることが分かる。最近ではPythonやRなどのデータサイエンスの分野で用いられることの多いプログラミング言語に便利なライブラリが用意されている。特にPythonは多次元配列の高速なベクトル演算を可能にするNumPyや、機械学習ライブラリとしてscikit-learn などを用いることで、オープンソースのライブラリを使って簡単に機械学習のプログラムを実装することができる。他にも表形式のデータ操作を可能にするpandasやデータの可視化を実現するmatplotlibも存在し、Pythonのライブラリの発展とともに、高度な機械学習プログラミングが可能となっていく。
まとめ
今回の記事では以下のことを述べた。
- 機械学習の簡単な説明
- 人工知能と機械学習の違い
- 機械学習の3つの分類である教師あり学習、教師なし学習、強化学習について
- 機械学習とPythonのライブラリの発展
機械学習は人間では困難な膨大なデータからの予測を可能にし、私達の生活の中で重要な役割を担っている。また研究がされていくことで、より機械学習が発展していきよりよいサービスが創造されていくに違いない。
関連記事

はじめに ポイント1:設計書を書いてもらいましょう ポイント2:Geminiを使うときの指示の出し方 ポイント3:自分で修正したら「読み直して」と必ず伝える まとめ はじめに 生成AIを使ってコード生成や修正を行うことは、もはや特別なことではなくなってきました。 Gemini や CodeX、Copilot、Cursor など、選択肢も増え、「うまく使えばかなり楽になる」という実感を持っている方も多いと思います。 一方で、実際に使い込

はじめに 復旧キーとは? 「復旧キーがない場合」を試す まとめ はじめに 先日、私用のMacBook Proにログインできなくなる問題が発生しました。 経緯としては、2台あるMacBook Pro AとMacBook Pro Bを取り違えてしまい、MacBook Pro AにMacBook Pro Bのパスワードを入力し続け、パスワード入力の試行可能回数を超過してMacBook Pro Aにロックがかかりました。 Macのログインパスワー

はじめに SSM統合コンソールによる一元管理 OSなど構成情報の可視化 Patch Managerによるパッチ運用の標準化 証明書有効期限の集中監視と自動通知 導入効果と業務改善イメージ 導入時の設計上の留意点 継続的改善を支える「運用の仕組み化」 1.はじめに クラウド活用が拡大し、AWS環境が複数アカウントで利用されたり、複数システムにまたがって利用されることは、システム運用における構成の一貫性を維持することの難易度を

はじめに 可用性設計の基礎:リージョンとAZの仕組みを理解する 止まらない設計を妨げる単一点障害:単一AZ構成の限界 マルチAZ構成:同一リージョン内での止まらない仕組み マルチリージョン構成:事業継続(BCP)のための冗長化 まとめ:設計段階で「どこまで止めないか」を決めよう 1. はじめに AWSは、数クリックで仮想サーバー(EC2)を立ち上げられるなど、手軽にサービスを構築できるクラウドです。システム企画や開発の初期段階では