DEVELOPER’s BLOG
技術ブログ
【機械学習入門】Pythonで実装する時の第一歩(気象データで天気予測)

はじめに
最近天気が不安定で、急な雨が多くまいっています。(しかも冬の雨はツライ。)
ついつい出かける時に傘を持たずに、夜、雨に降られることも多いですよね。
現在、Pythonを使った機械学習を勉強しているので、kaggleだけではなく、実際にテーマを決めて何か簡単な実装をしてみたいと思い、今回は気象庁のデータを使って ある日に雨が降っている or いないという2値の予測を実装をします。
自分で作ると愛着が湧いて、ちょくちょく予測して傘を忘れずに済むだろう。そして濡れることはもうないだろう!をモチベーションに頑張ります。
目次
気象庁のデータを収集し、整える
予測するためにデータの収集から始めましょう。中々扱いやすいデータが無いので困りますが、気象庁が提供している気象データがかなり綺麗なのでこのデータを採用します。このデータは過去の気象データで地点、期間、項目(雨量、風速など)を選択しエクセルのCSVファイルでダウンロードしてくれるのでとっても便利でした。そこで平均気温(℃)、天気概況(昼:06時~18時)、降水量の合計(mm)、日照時間(時間)、平均風速(m/s)、平均蒸気圧(hPa)、平均湿度(%)、平均雲量(10分比)がかなりを取り、東京の1日毎の1年分のデータを使うことにしました。
データを読み込んだときにいらない情報もあったのでこんな感じでデータを整えました。
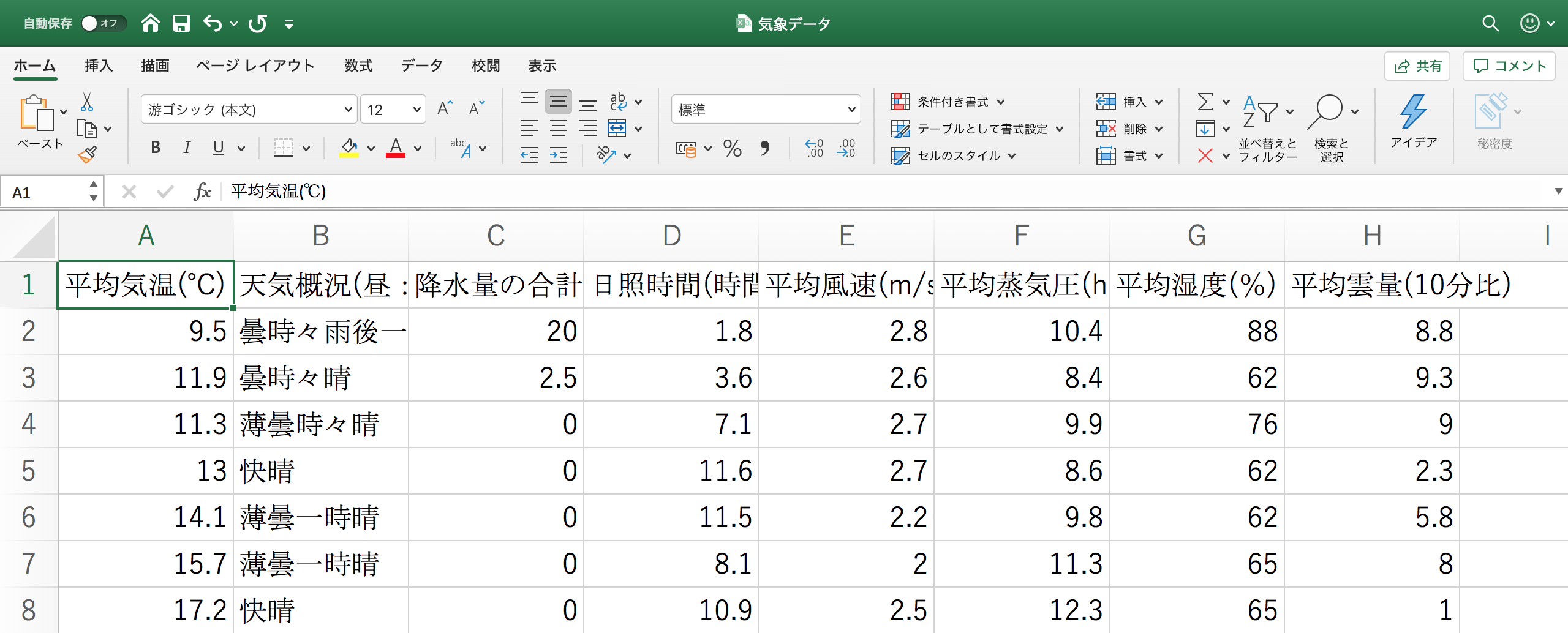
今回は、ある日に雨が降っているかどうかを予測するので降水量の合計(mm)を正解データ(目的変数)としましょう。雨の定義としては、その日の降水量の合計が0mmより大きい、つまり少しでも降ったら雨、降水量の合計が0mmならば雨でないとします。また特徴量(線形回帰では説明変数などと呼ばれています。機械が学習するために使う要素です。)としては先程あげたデータの降水量の合計以外を使ってみます。天気概況に雨があるので人が雨と判断することは簡単です。しかし、機械は「天気が雨だと降水量が0でない」ということを判断できません。人間にとって簡単なことほど機械が行うのは難しく、天気概況を特徴量に含めた時、どのように学習してくれるか検証することも面白いですね。
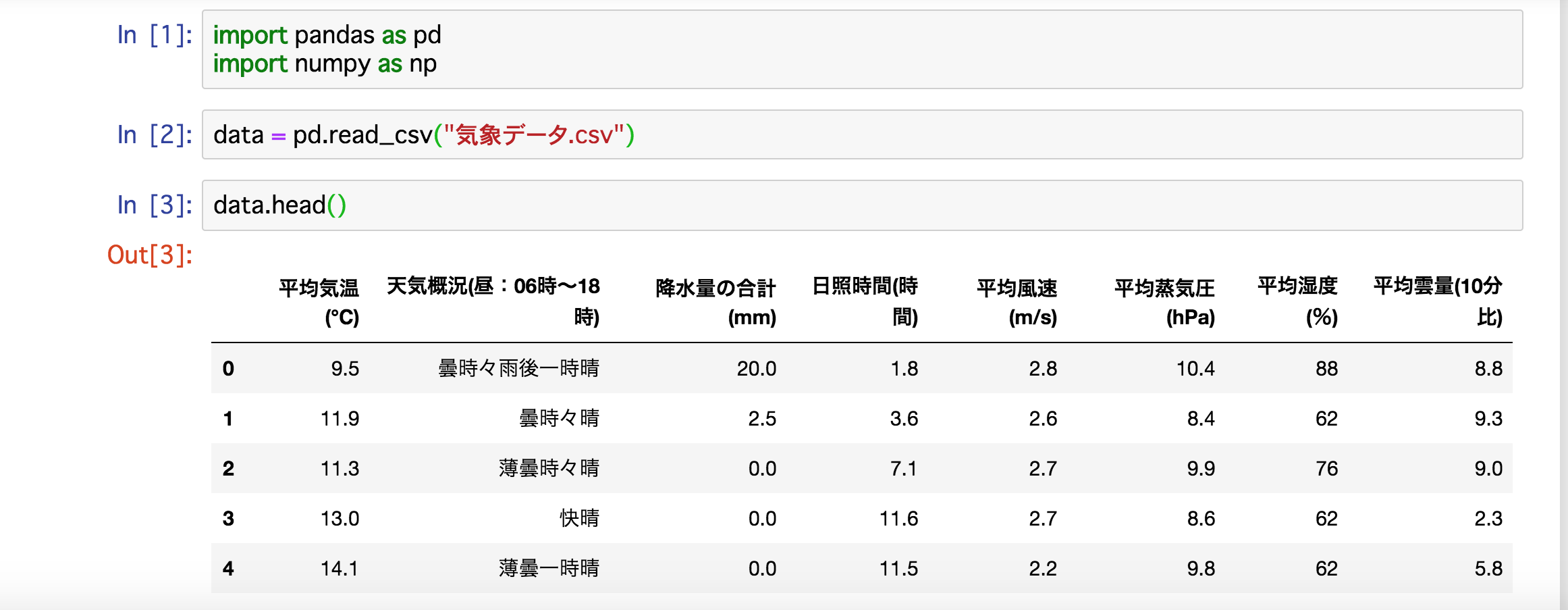
予測するためによく使われているAnacondaのjupyterNotebook、Python3.7を使います。手始めにデータを読み込んで表示させましょう。
もう少しデータを扱いやすく直します。天気概況ですが、文字情報のため扱いにくいです。そこで「晴」→4、「曇」→3、「雨」→2、「それ以外」(雪など)→1と数値化してしまいましょう。また、正解データになる降水量の合計に関しても降水量があれば1、なければそのまま0にしましょう。
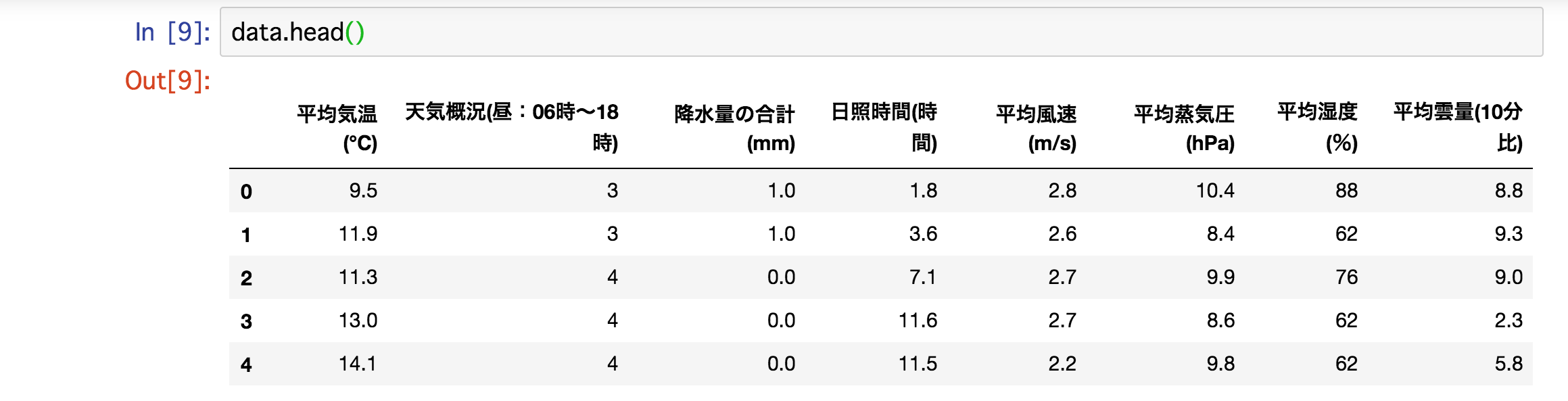
上のようにデータを整えればOKです。データを整える際はプログラミングがあまり得意でなければそのままエクセルのファイルの数値を1つずつ変えれば問題ないと思います。(データ量が膨大だったらプログラミングを書きましょう。)プログラミングを書いてデータを整えるのもプログラミングの良い練習になると思います。
線形回帰で実装する
ここまで来たらついに予測ができます。
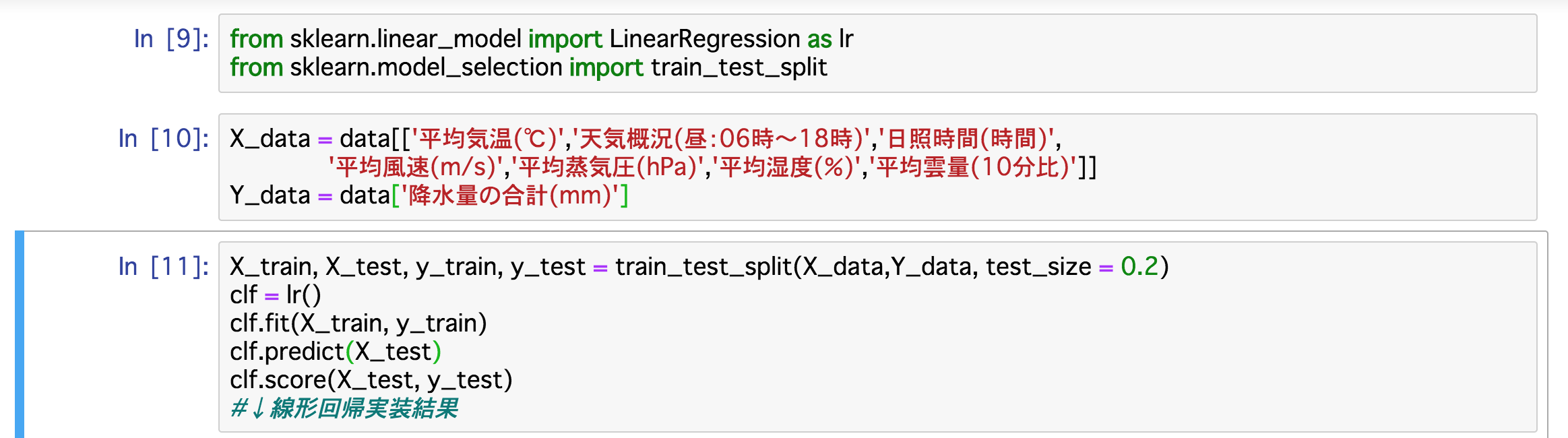
まずは、年月日以外のすべてのデータを説明変数、降水量の合計を目的変数として線形回帰してみましょう。今回はライブラリを使って実装します。
少し教師あり学習(線形回帰のように正解データがある学習)について説明します。教師あり学習ではデータを訓練用のデータと評価用のデータに分ける必要があります。
訓練用のデータというのは機械に学習させるための材料になるものです。このデータをもとに機械は学習をします。そしてその学習をしたモデルを用いて評価用のデータを評価します。最後にその評価結果ともともとの正解データを見比べてどれだけあっているかが精度として出るわけです。
つまり、pythonで実装する際もデータをどれくらいの割合で分けるか機械に指示する必要があります。そのライブラリがIn [9]の2行目「from sklearn.modelselection import traintest_split」です。1行目のライブラリは線形回帰のライブラリになります。
実装した結果が次のようになりました。
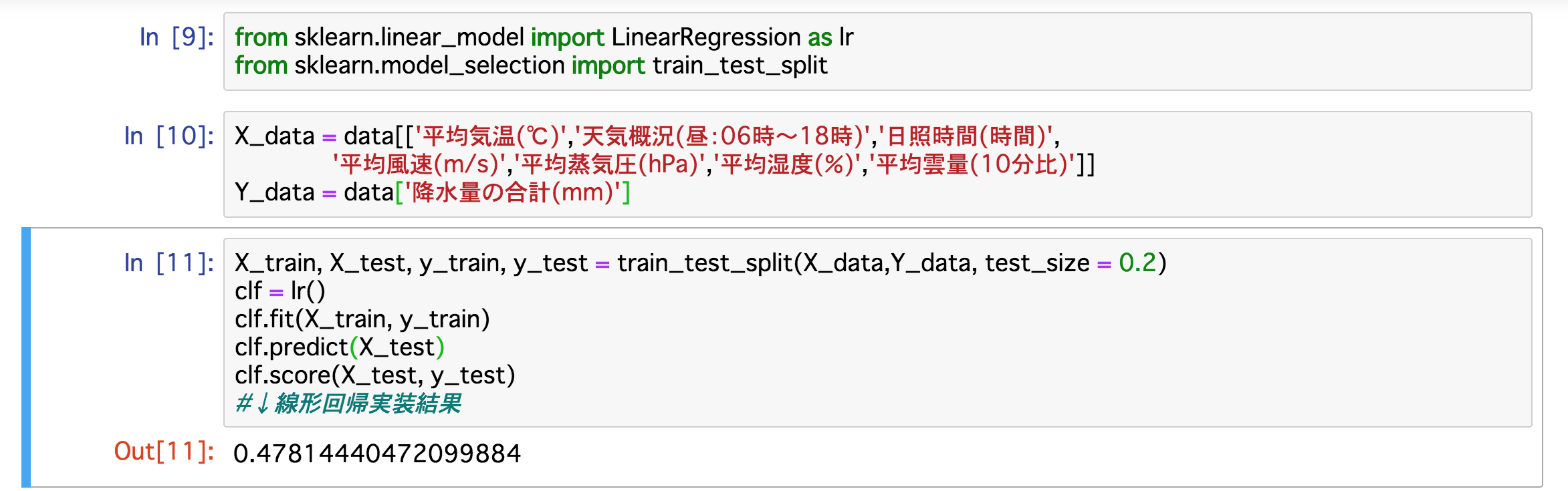
精度は、0.4781...となっているので約48%。ということはほぼ半分なので全然予測ができていません...。
せっかく頑張っても最初はこんな感じです。ここで少しだけ上のプログラミングに関して補足します。In [11]の1行目の部分で訓練データと評価用データに分けています。今回は、「 test_size = 0.2」としているので全データに対して訓練データが80%、評価用データが20%としています。このデータは訓練データ、評価用データのどちらに割り振られるかランダムなので評価するごとに同じ結果は出ません。振り分けられ方によっては精度が上下することもあるので、正確な精度を出したいときは何回か実装してその平均を取ります。
実装結果から精度UPするために
線形回帰をした時、精度が約52%でした。この精度になった原因としては以下が考えられます。
①過学習してしまった。
②データが少ない。
③2値に分類するのにそもそも線形回帰の相性が悪い。
以上3点が思いつきました。順番に見ていきましょう。
まず①について、そもそも過学習というのは説明変数の相性が悪かったり説明変数が多すぎて機械が誤って学習してしまうことです。誤って学習してしまうことで、精度が悪くなってしまいます。そこで、説明変数を見直しましょう。例えば、日照時間は長ければ、気温が高くなりそうのなので気温のデータだけあれば大丈夫そうです。また、平均蒸気圧は気温に依存して決まるそうなのでこれもいらなそうです。そこで日照時間と平均蒸気圧をなくして予測してみましょう。その結果は、
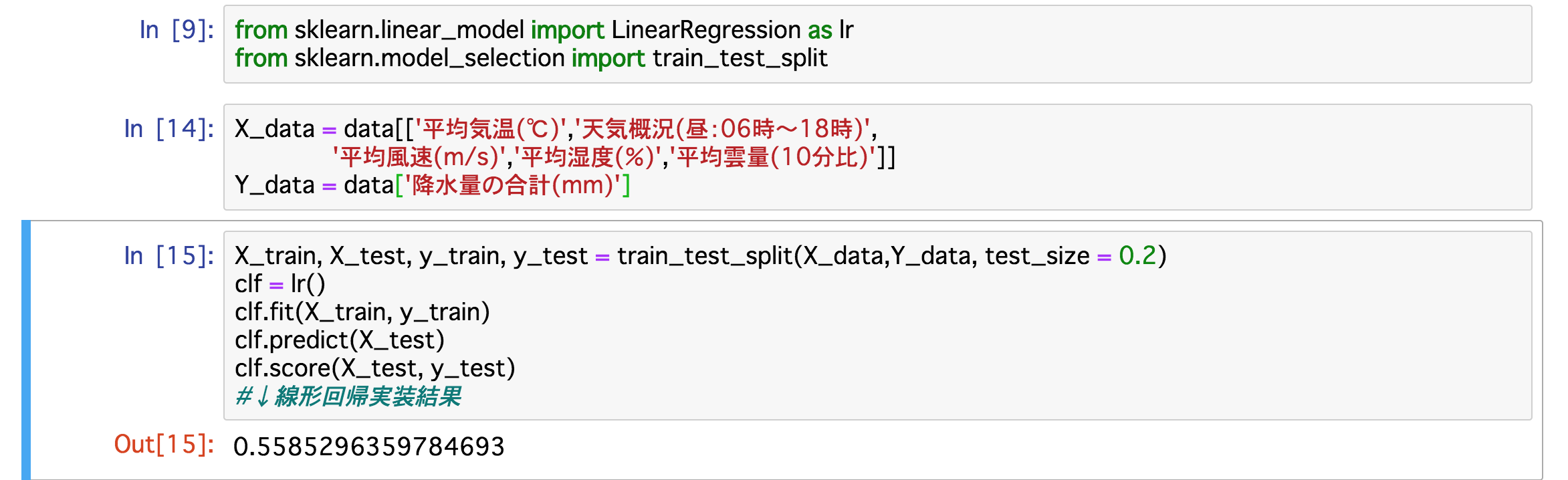
精度は、0.5585...なので多少上がりました。
次に②については、データが少ないと機械もうまく学習することができません。1年分のデータから3年分のデータに増やして実装してみました。
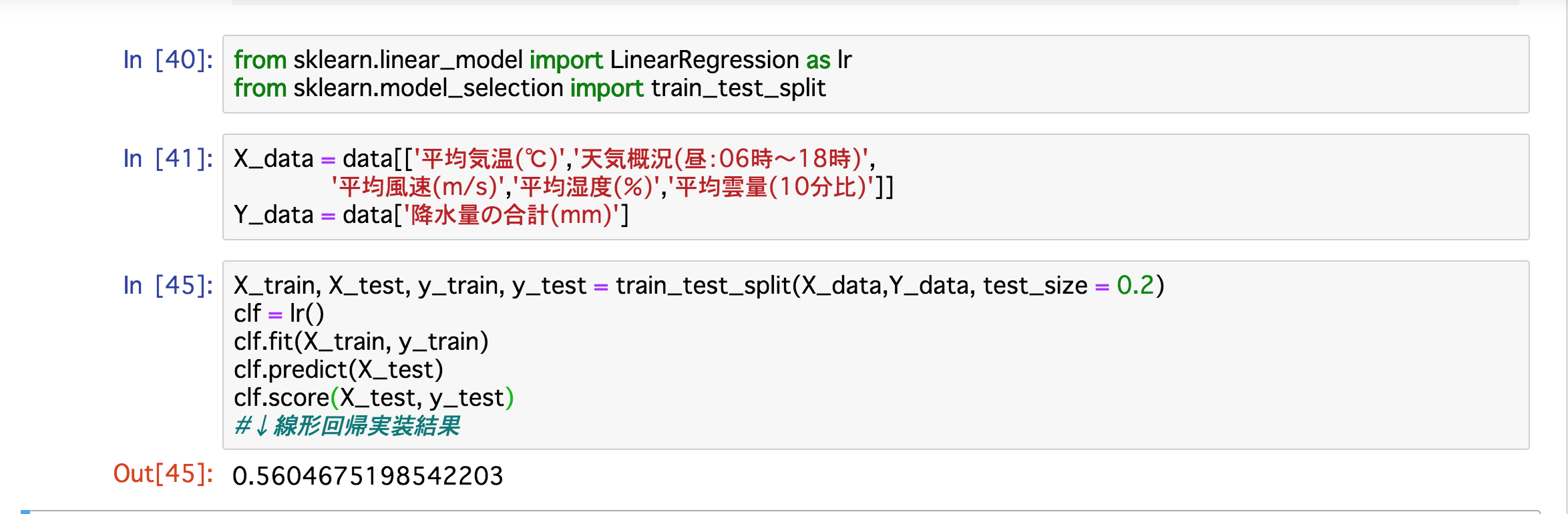
①の説明変数も減らして実装したのですが精度はほぼ変わらなかったですね。
最後に③についてです。線形回帰は最小2乗法を用いた最もシンプルな回帰モデルですが、今回の精度の結果からあまり2値に分類するのには適したモデルではないのかもしません。そこで、2値分類する際に有名なモデルとして、ナイーブベイズやロジステック回帰です。ロジステック回帰にして実装してみましょう。
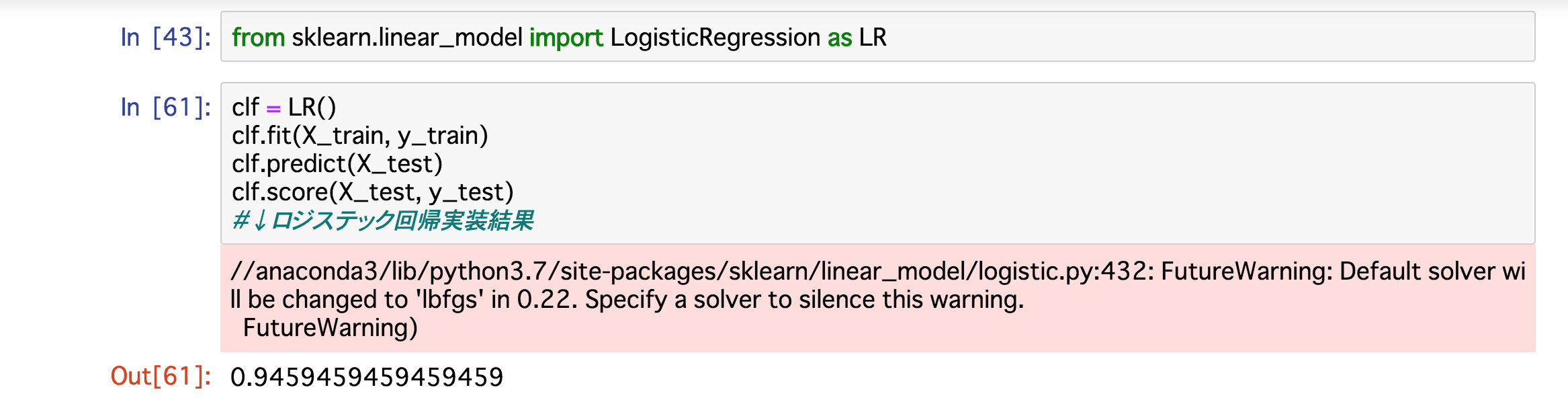
これも①の説明変数も減らして実装すると、精度はすごく上がりました。
皆さんもいろいろ実験してみてください。
まとめ
今回は、線形回帰を用いて雨が降るかどうかを予測しました。先程の精度UPについて考察する所では、以下のようにして精度を上げることができました。
特徴量(説明変数)をうまく選ぶ
モデルを変えてみる
他にもデータを見直し、もっと学習に合うようにデータを直して精度を上げます。このような作業をデータの 前処理(特徴量を選択するのも前処理です)と言います。前処理は知識やセンスが問われ、うまくできると精度がとても上がります。そして、人によってやり方も様々なので正解もありません。この精度を競うコンペも行われていて、有名所はkaggleやSIGNATEがあります。コンペで優秀な成績を納めれば懸賞金も貰えるのでチャレンジしてみて下さい!
参考文献
定期的にメルマガでも情報配信をしています。
ご希望の方は問い合わせページに「メルマガ登録希望」とご連絡ください。
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 実装前の課題 採用した技術と理由 実装した内容の紹介 改善したこと(抑制できたコスト) 実装前の課題 SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。 弊社では2021年2月からSRE活動を行っており、セキュリ

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数