目次
- 1. はじめに
- 2. Cursorの概要
- 3. 言語モデルの選択
- 4. 4つのモード
- 4-1. Agentモード
- 4-2. Askモード
- 4-3. Planモード
- 4-4. Debugモード
- 5. Rulesの設定
- 5-1. プロジェクトルール
- 5-2. ユーザールール
- 6. コードレビューでの活用
- 6-1. レビュー用のプロジェクトルールを作成する
- 6-2. レビュー対象の差分ファイルを作成する
- 6-3. レビューしてもらう
- 7. おわりに
1. はじめに
生成AIを活用したコードエディタが急速に広まりつつある昨今、Cursorはその代表的な存在のひとつです。
私自身、とあるプロジェクトでCursorを使うことになったものの、使い始めて数日は正直なんとなくで使っていたところがありました。
そこで本記事では、
・これからCursorを使ってみようとしている方
・とりあえず使い始めたものの、手探りで使っている方
に向けて、実際の画面や設定例を交えながら、使ってみて「もっと早く知っておけばよかった」と感じたポイントをまとめてみました。
2. Cursorの概要
Cursorは、VSCodeをベースに生成AIを統合したコードエディタです。
既にVSCodeを使っている方であればCursorへの機能的・心理的な移行はスムーズかと思います。
コード補完や生成だけでなく、既存のプロジェクト全体を前提にした質問応答や、設計・実装の補助までをエディタ上で完結できる点が特徴です。
ChatGPTを別タブで使うのとは異なり、現在のコードやファイル構成を文脈として扱えるため、より実践的なやり取りが可能になります。
3. 言語モデルの選択

CursorではGPT系やGemini系など含めて様々な言語モデルを選択できますが、モデルごとに料金や得意な作業が異なります。
下の表では、2025年12月時点での代表的なモデルとその特徴について、入力単価が安い順に整理しています。
特徴についてはCursorに聞いてまとめてもらいました。
| モデル名 | 特徴 |
|---|---|
| Grok Code |
レスポンスが速く、日常的な開発作業向け。 短い質問や軽いコード補完、試行回数の多い作業で使いやすい。 |
| Gemini 3 Flash |
高速な応答性と効率性を備えたモデル。 プロ級の知性と速度を兼ね備え、日常的な開発作業に適している。 |
| GPT-5.1 Codex Max |
汎用性が高く、幅広い用途で安定した性能を発揮。 複雑な推論や多段階のタスクに強みを持つ。 |
| Composer 1 |
Cursor向けに設計されたエージェント型モデル。 複数ファイルにまたがるコードの読み書きや変更が可能。 |
| GPT-5.2 |
OpenAIの最新かつ最も高度なコーディングモデル。 複雑で長時間のコーディングタスクやサイバーセキュリティ分野での性能が向上している。 |
| Gemini 3 Pro |
マルチモーダルな理解力とツール活用に優れ、画像や動画、コードを統合的に処理可能。 プロトタイピングやMVP開発に適している。 |
| Claude 4.5 Sonnet |
安定性と予測可能性が高く、指示に忠実で小規模な非破壊的編集に適している。 複雑なリファクタリングやエージェント型ワークフローに最適。 |
| Claude 4.5 Opus |
Anthropicの最も高度なAIモデルで、コーディング性能が業界トップクラス。 情報検索やツール使用、分析、Excel自動化などの企業向け機能も強化されている。 |
現状、公式ドキュメントにモデルごとの具体的な利用シーンが詳しく載っているわけではなく、実際には試しながら把握していく部分も多い印象です。
また、実際の開発では「これは軽い作業だからこのモデル」「次は設計だからこのモデル」とモデルを毎回切り替えるのは、思った以上に判断コストがかかります。
そのため、モデル選択にこだわりがない場合は、少なくとも最初はデフォルトのAutoを使うのが無難だと感じました。
Autoは、Cursorがタスク内容に応じて適切なモデルを自動で選択してくれるため、モデルの違いを意識せずに作業を進めることができます。
ただし、稀に「急に変なこと言い出したな」と感じる場面もあるため、その場合は明示的にモデルを選択する必要があるかと思います。
4. 4つのモード(Agent/Ask/Plan/Debug)

Cursorには、作業内容ごとに使い分けられるAgent / Ask / Plan / Debugの4つのモードが用意されています。
デフォルトではAgentモードで動作します。
言語モデルはデフォルトのAutoのままでも大きな問題は起きにくい一方で、モードについてはそれぞれの特徴を理解した上で使い分ける必要があると思っています。
4-1. Agentモード
Agentモードは、エディタ上でのコード作成やコマンド実行などの作業をCursorに任せたいときに使います。
新機能の実装やRspecのテスト作成など、実際に手を動かす開発作業をまとめて進められます。
一方で、Agentモードは「最終的にコードを直す」前提で動く傾向があります。
例えば「このエラーの原因は?」と単に質問しただけのつもりでも、原因が確定していない段階でもコードの修正まで進めてしまうことがあります。
そのため、考えを整理したいだけの場面や、まずは状況を理解したい段階では、後述する別のモードを選んだほうが快適でしょう。
4-2. Askモード
Askモードはその名の通り、質問や相談をしたいときに使います。
途中から入ったプロジェクトの既存コードの流れを理解したい場合や、この処理が何を意図して書かれているのかを確認したい場面などで有効です。
私の場合は費用を抑えるため、一般的な構文や言語仕様のようにプロジェクトの文脈が不要な内容はChatGPTで確認し、
文脈を踏まえた回答が必要な場合はAskモードを使うようにしています。
4-3. Planモード
Planモードは、実装に入る前に方針を整理・具体化したいときに使います。
こちらから要件や目的を伝えると、Cursorから前提条件や確認事項が提示されます。
それらのやり取りを踏まえて、実装方針や作業手順をMarkdown形式のドキュメントとしてまとめてくれます。
「何を作るか」「どこを直すか」などを文章として可視化できるため、少し規模のある改修や新機能を考える場面で役立ちます。
また、作成された計画ファイルは、後述するコードレビューでも活用できます。
※Planモードについてはコチラの記事でも詳しく紹介されているので是非ご覧ください。
Cursor Planモードのススメ:なぜ"いきなり書かせる"と事故るのか
4-4. Debugモード
Debugモードは、バグの原因特定から修正・検証までを進めたいときに使います。
バグの状況を伝えると、複数の仮説を立てたうえでログ出力の追加などのコード修正を行い、バグ再現のための画面操作やコマンド実行の手順を示してくれます。
その実行結果をもとに原因を絞り込み、修正案の提示や再修正を進めていく流れになります。
このモードは2025年12月にリリースされた比較的新しいもので、まだあまり試せてはいませんが、デバッグの進め方そのものを支援してくれる点が特徴的だと感じています。
5. Rulesの設定

Cursorには、振る舞いをあらかじめ調整できる「Rules」という仕組みがあり、プロジェクト固有の前提や自分の作業スタイルを共有した状態でCursorとやり取りできます。
Rulesには主にプロジェクトルールとユーザールールの2つがあり、いずれもCursor SettingsのRules and Commandsから設定できます。
5-1. プロジェクトルール
プロジェクトルールは、特定のプロジェクトごとに適用されるルールで、開発環境や作業前提などをCursorに伝えることができます。
例えば、RSpecをDocker Compose経由で実行する場合は以下のようなルールを設定できます。
--- alwaysApply: true --- RSpecのテストを実行する際は、必ず以下の形式で実行すること: - 'docker-compose exec web bundle exec rspec [テストファイルパス]' - 直接 'bundle exec rspec' を実行しないこと 例: - 全テスト: 'docker-compose exec web bundle exec rspec' - 特定ファイル: 'docker-compose exec web bundle exec rspec spec/models/user_spec.rb' - 特定行: 'docker-compose exec web bundle exec rspec spec/models/user_spec.rb:10'
このルールにより、CursorはRSpecを正しいコマンドで実行できるようになります。
ルールがない場合はデフォルトでbundle exec rspecなどを実行して失敗するため、毎回正しいコマンドを指示する必要があります。
(これが結構ストレスでした。。)
なお、alwaysApplyはルールの適用方法(Rules Type)の一つで、すべてのチャットセッションに自動的に適用されることを表しています。
適用方法は「そのルールをどのタイミングで適用するか」を指定するもので、全部で4つあります。
| 適用方法 | 概要 | 必要な要素 |
|---|---|---|
| Always Apply | すべてのチャットセッションに自動的に適用 | alwaysApply: true |
| Apply Intelligently | ルールの説明文をもとに、Cursorが関連ありと判断したら適用 | description |
| Apply to Specific Files | 指定したファイルに関する話題のときのみ適用 | globs |
| Apply Manually | @で該当ルールを指定した時に適用 | なし |
5-2. ユーザールール
ユーザールールは、すべてのプロジェクトに適用されるルールで、会話スタイルや個人の開発スタイルをCursorに伝えることができます。
例えば、私の環境では以下のようなルールがあらかじめ設定されていました。
(Cursorを日本語対応させた際に自動で追加されたのかもしれません。)
Always respond in Japanese
このように、ユーザールールはプロジェクトルールとは異なり1~2文程度で簡潔に記載するのが良いようです。
6. コードレビューでの活用

Cursorは実装や修正だけでなく、コードレビュー用途でもかなり使えます。
今のところ、以下のような手順でレビューしてもらっています。
6-1. レビュー用のプロジェクトルールを作成する
例えばこのようなルールを作成します。
--- alwaysApply: true --- # コードレビュールール コードレビューを行う際は、このファイルを必ず参照し、 最初に「review.mdcファイルを参照しました」と出力すること。 ## チェック項目 ### 1. コーディング規約・品質 - [ ] RuboCop(.rubocop.yml)に準拠しているか - [ ] 可読性が保たれているか(命名・責務・重複コード) - [ ] デバッグコードや不要なコメントが残っていないか ### 2. テスト - [ ] 変更内容に対応するテストが書かれているか - [ ] エッジケース・異常系が考慮されているか ### 3. セキュリティ・安全性 - [ ] SQLインジェクション / XSS / 認可まわりに問題がないか - [ ] 機密情報がハードコードされていないか ### 4. パフォーマンス - [ ] N+1など明らかな非効率がないか - [ ] 大量データを扱う処理が妥当か ### 5. 仕様・ロジック - [ ] 計画ファイル・仕様に沿った実装になっているか - [ ] ロジックの誤りや境界値の考慮漏れがないか - [ ] 既存機能への影響がないか ## レビュー時の参照物 - 差分ファイル(changes.diff 等) - Planモードで作成した計画ファイル ## レビューコメント - 各項目を '[x] / [ ]' で明示する - 必須修正と任意修正を区別する - 可能であれば改善案を添える
ちなみに、このルールはCursorと一緒に作ったもので、読みやすさを優先して短く整理しています。
実際にはプロジェクトごとに必要な観点を追加・調整する必要があると思います。
6-2. レビュー対象の差分ファイルを作成する
下記のようなコマンドを実行し、差分ファイルを作成します。
git diff origin/develop..HEAD > changes.diff
基底ブランチがmainの場合は、Cursorが用意している「Branch (Diff with Main)」シンボルを渡せば十分です。
一方、main以外を基底にしたい場合は、現状このようにgit diffで差分ファイルを作るのが一番確実そうです。
6-3. レビューしてもらう
Askモードを選択し、下記2つのファイルを渡して「レビューして」と入力します。
- 上記で作成した
changes.diff - 実装前にPlanモードで作成した計画ファイル
Askモードを使うことで、コードを書き換えられずレビューに集中してもらえます。
7. おわりに
本記事では、実際にCursorを使ってみる中で、「もっと早く知っておけばよかった」と感じたポイントを中心に紹介してきました。
Cursorをこれから使い始める方や、すでに使ってはいるものの活用しきれていないと感じている方にとって、少しでも参考になれば幸いです。
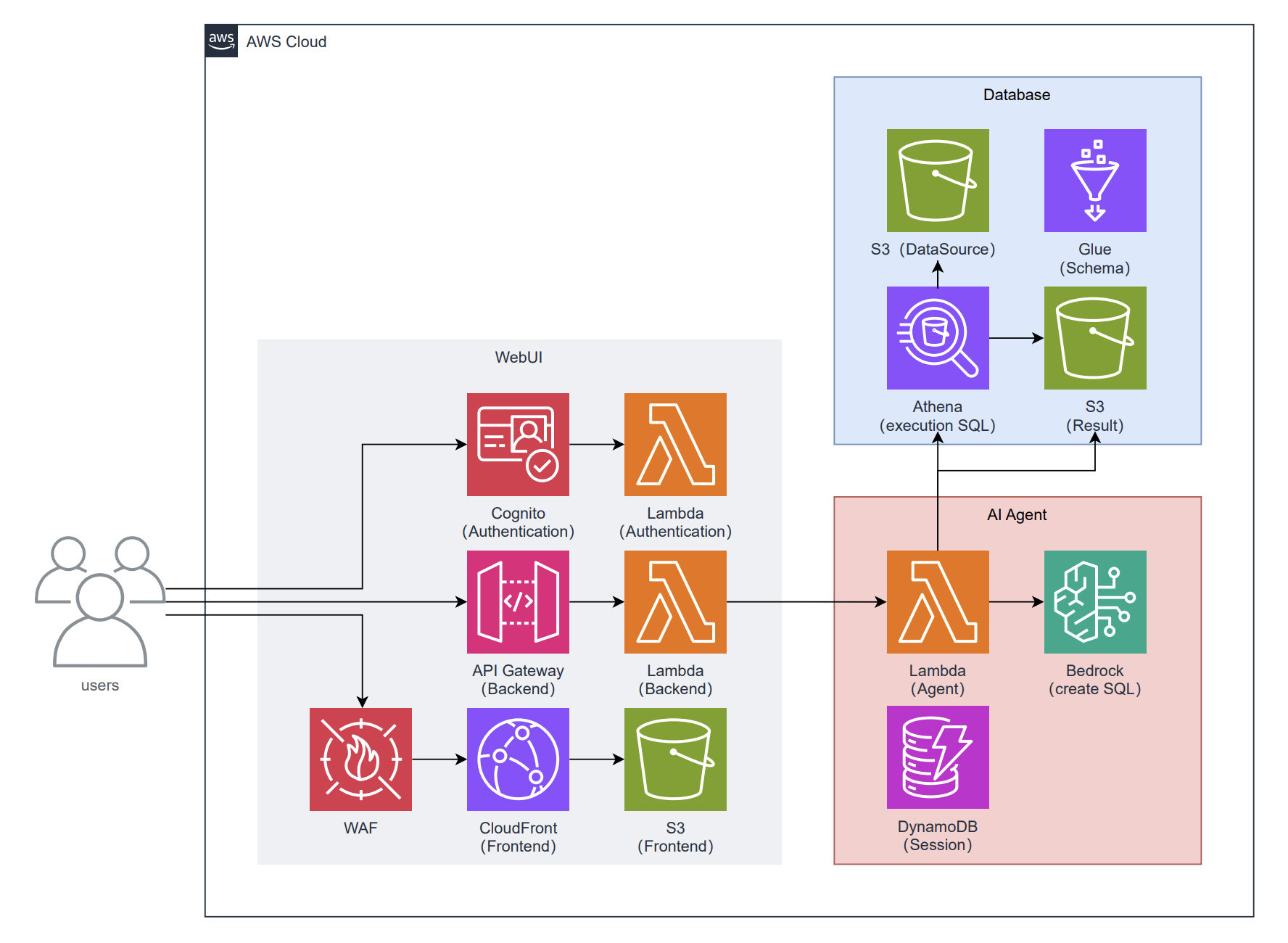

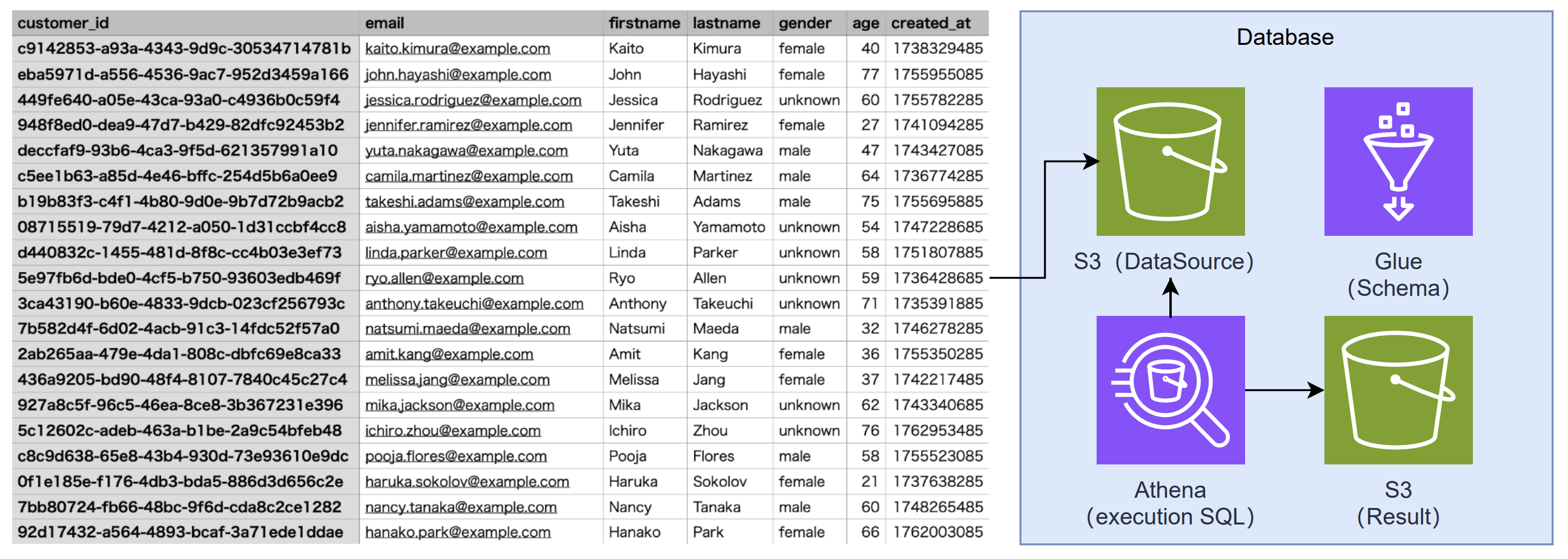
 AIエージェントと会話ベースでのやりとり
AIエージェントと会話ベースでのやりとり
 情報システム部→AIエージェント
情報システム部→AIエージェント